一种基于多智能体强化学习的小区间干扰协调方法
本发明涉及无线移动通信,尤其涉及一种异构网络下的小区间干扰协调方法。
背景技术:
1、异构网络是指在宏基站(macro base station,mbs)的覆盖范围内部署中继(relay)、微微基站(pico base station,pbs)等低功率节点。异构网络中,由于其多层次、多接入的复杂网络形态,存在着网络负载不均衡和小区间干扰严重的问题。
2、针对异构网络中出现的问题,小区范围扩展技术(cell range expansion,cre)被引入异构网络的技术体系。cre技术的核心原理是在用户使用的传统最大参考信号接收功率(maximum reference signal receiving power,max-rsrp)基站接入方式的基础上,为pbs添加一个大于零的偏移量,称为cre偏置值。正向cre偏置值的存在,允许用户接入提供更低信干噪比(signal to interference plus noise ratio,sinr)的pbs。换言之,通过降低用户接入pbs的门槛,使得更多用户选择pbs,增加了pbs转移mbs负载的能力。根据用户关联基站的方式,与pbs关联的用户可以划分为两部分:由于正向cre偏置值存在而关联pbs基站的微微小区扩展用户(pico expansion user equipment,peue),和即使不添加正向cre偏置值也关联pbs基站的微微小区中心用户(pico centre user equipment,pcue)。
3、对于不同功率基站覆盖范围重合区域内的用户,特别是处于微微小区边缘的用户,会遭受来自大功率mbs的干扰。对于cre技术,一方面如果偏置值设定过小,微微小区覆盖面积并不能得到明显扩展,cre均衡负载能力无法得到明显体现;另一方面如果偏置值设定过大,微微小区的覆盖面积得到不合理扩展,那些本来应当更适合接入mbs的用户被迫选择接入pbs,从而遭受来自mbs的强烈干扰,因此需要选择合适的cre偏置值。诸多技术人员都此做出了深入研究。文献“t.jung,i.song,s.lee,s.jung,s.yoon and j.kang,"cellrange expansion with geometric information of pico-cell in heterogeneousnetworks,"2018ieee 87th vehicular technology conference(vtc spring),2018,pp.1-5,doi:10.1109/vtcspring.2018.8417616”考虑了pbs在系统中的位置,并提出了一个cre偏置值调整方案,以使系统和速率最大化。文献“gu jing,deng yifei,zhangxin.dynamic cre bias selection algorithm based on heuristic reinforcementlearning[j].computer engineering,2020,46(5):200-206”提出了一种基于启发函数进行cre偏置值动态选择的hsarsa算法,家庭基站独立地从经验中学习cre偏置值。
4、现有采用深度强化学习解决cre偏置值优化问题的算法中,主要分为集中式框架和分布式框架两种。集中式框架中,一个中央控制器作为智能体,为系统内所有基站设定不同的cre偏置值,以提高系统吞吐量。但缺点在于随着基站数量的增加,偏置值空间尺寸极速膨胀,优化难度和复杂性也随之增加。分布式框架下多个pbs作为多个智能体单独训练、单独执行,但缺点在于全局信息交互不足,忽略了系统内所有基站之间的合作关系,单个最优不代表全局最优。
技术实现思路
1、本发明提出了一种异构网络下基于多智能体强化学习算法动态调整cre偏置值的小区间干扰协调技术,在应对网络负载不均衡和小区间干扰严重问题的同时,提高系统内所有用户的总吞吐量。
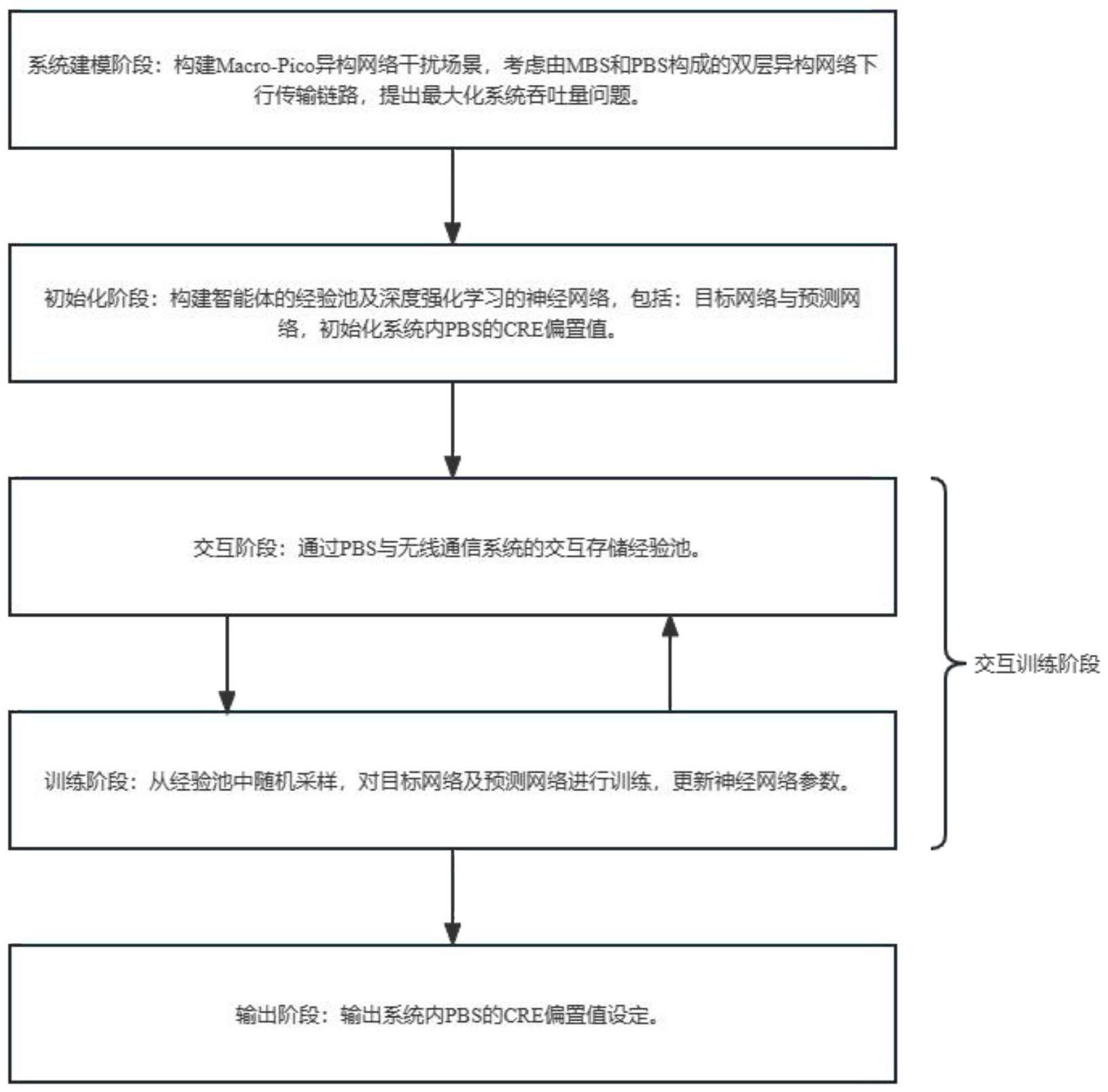
2、为解决上述技术问题,本发明采用的方法是一种基于多智能体强化学习的小区间干扰协调方法,包括如下步骤:
3、步骤1、系统建模阶段:构建macro-pico异构网络干扰场景作为无线通信系统,考虑由宏基站(macro base station,mbs)和微微基站(pico base station,pbs)构成的双层异构网络下行传输链路,提出最大化系统吞吐量问题。
4、步骤1系统建模阶段中包括如下具体步骤:
5、步骤1.1、考虑系统中有1个mbs和np个pbs,nu个用户随机均匀分布在整个系统中,其中每个pbs的覆盖范围内包含nup个随机分布的用户。其中,nu是系统内全体用户的数量。生成全体用户时,要求在每个pbs的覆盖范围内生成nup个剩下nu-nup×np个用户随机分布在mbs的覆盖范围内。
6、步骤1.2、提出小区范围扩展模型,具体如下:
7、在异构网络中,用户常使用max-rsrp策略来选择关联基站,即每个用户与观测到的提供最高rsrp的基站相关联。为了有效拓宽pbs的服务范围,使更多用户特别是处于宏小区和微微小区交界处的用户选择pbs,cre技术为每个pbs添加一个正向偏置值,此时用户的关联基站为:
8、
9、其中,i表示第i个基站,u表示第u个用户,i=0时指代宏基站mbs,1≤i≤np时指代微微基站pbs;即为使用cre技术时第u个用户的关联基站序号,σi表示基站i的cre偏置值,由于mbs不设置cre偏置值,所以σ0=0;rsrpiu代表第u个用户接收到的来自第i个基站的rsrp,计算如下:
10、rsrpiu=pigiu (2)
11、
12、其中,pi表示第i个基站的发射功率,pm表示宏基站mbs的发射功率,pp表示微微基站pbs的发射功率,giu表示第u个用户与第i个基站之间的信道增益;
13、步骤1.3、提出几乎空白子帧(almost blank subframe,abs)模型,具体如下:
14、本发明联合使用时域干扰协调技术中的abs技术,以减轻cre技术对于边缘用户的干扰。abs技术的特点在于将子帧划分为两种类型:非abs子帧和abs子帧。abs子帧期间,mbs不传输任何有效数据,pbs调度受到mbs严重干扰的peue;非abs子帧期间,mbs正常服务宏小区用户(macro user equipment,mue),pbs只调度pcue。用户在非abs和abs期间受到不同程度的干扰,因此由pbs提供服务的第u个用户处的sinr在不同子帧期间分别表示如下:
15、
16、
17、其中,表示关联到pbs的第u个用户处于abs子帧期间的sinr,表示关联到pbs的第u个用户处于非abs子帧期间的sinr;即为该关联基站的发射功率,表示第u个用户与该关联基站之间的信道增益;表示关联到第个pbs基站的第u个用户所遭受的同频邻区干扰;n0是噪声功率;
18、由mbs提供服务的第u个用户处的sinr在不同子帧期间分别表示如下:
19、
20、
21、其中,表示关联到mbs的第u个用户处于abs子帧期间的sinr,表示关联到mbs的第u个用户处于非abs子帧期间的sinr,由于mbs在abs子帧期间不传输任何有效数据,因此sinr表示为零。p0表示第0个基站的发射功率,即mbs的发射功率,p0=pm;g0u表示第u个用户与第0个基站之间的信道增益,即第u个用户与mbs之间的信道增益。
22、定义第i个基站在abs子帧期间的服务用户数量为在非abs子帧期间的服务用户数量为定义abs比例β为一帧内abs子帧数占总子帧数的比值,β满足以下条件:
23、0<β<1 (8)
24、步骤1.4、提出最大化系统吞吐量模型,具体如下:
25、本发明假设每个用户获得几乎相等的资源量,因此可以根据香农公式计算第u个用户的吞吐量为:
26、
27、其中,w是系统带宽,和分别表示第u个用户所关联的第个基站在abs和非abs期间的服务用户数量。根据用户关联基站类型的不同,当用户关联pbs时等于当用户关联mbs时等于同理当用户关联pbs时等于当用户关联mbs时等于
28、关联第i个基站的所有用户的吞吐量可以计算如下:
29、
30、
31、
32、其中,表示abs期间第i个基站内用户的吞吐量之和;表示非abs期间第i个基站内用户的吞吐量之和。
33、系统吞吐量是系统内所有小区的总吞吐量,也是系统中所有用户的吞吐量之和。本发明的目标是,通过联合优化系统内所有pbs的cre偏置值,最大化系统内所有用户的吞吐量之和:
34、
35、其中,表示第1个、第2个……第np个基站的cre偏置值;表示系统吞吐量最大时第1个、第2个……第np个基站的cre偏置值取值。
36、步骤2、初始化阶段:构建智能体的经验池及深度强化学习的神经网络,包括:目标网络与预测神经网络,初始化系统内微微基站pbs的小区范围扩展(cell rangeexpansion)偏置值。
37、所述智能体是指将系统内所有pbs划分成k个不同的区域,第k个区域内所有nk个pbs被视为一个智能体,共享一个cre偏置值;其中1≤k≤k;此时,智能体agent表示如下:
38、{agent1,…,agentk} (14)
39、
40、很明显,当k=1,n1=np时,系统内所有pbs共享同一个动态调整的cre偏置值;当k=np,n1=…=nk=1时,系统每个pbs单独拥有一个个性化的cre偏置值。
41、步骤3、交互训练阶段:通过pbs与无线通信系统的交互存储经验池,并从经验池中随机采样,对目标网络及预测神经网络进行训练,更新神经网络参数。
42、步骤3交互训练阶段中pbs与无线系统的交互是指在强化学习系统中,环境产生描述系统状态的信息,即状态。智能体通过观察状态并使用此信息来选择动作。通过执行下一步动作,智能体对环境产生一定影响,而环境则根据智能体所采取的动作反馈一个奖励。当“状态→动作→奖励”的循环完成时,智能体和环境之间就完成了一次交互。针对本发明,具体包括如下步骤:
43、步骤3.1、设置轮次数nepisode=1。
44、步骤3.2、设置时间步nstep=0,相同步数nsame_step=0,最近吞吐量clast=0,cre偏置值σ=σ0。
45、步骤3.3、单个智能体在t时刻观测到的状态信息
46、将pbs覆盖扩展区域内的peue数量及peue所受干扰情况作为状态信息。具体而言,对于第k个智能体,状态信息ok由两部分组成:局部信息和全局信息。
47、第一部分局部信息:第k个智能体中各个pbs覆盖扩展区域内的peue数量及peue所受干扰情况。
48、
49、其中,表示因为cre偏置值的存在,关联到第k个智能体中第i个pbs的peue数量;表示关联到第k个智能体中第i个pbs的peue所受干扰强度的均值
50、第二部分全局信息:其他k-1个智能体范围内所有pbs覆盖扩展范围内的peue数量及peue所受干扰情况。
51、
52、其中,表示因为cre偏置值的存在,关联到第l个智能体中pbs扩展范围内的所有peue数量;表示关联到第l个智能体中pbs的所有peue所受干扰强度的均值;
53、此时,强化学习系统中所有智能体的状态信息构成联合状态信息o:
54、o={o1,…,ok} (18)
55、步骤3.4、将单个智能体状态信息连同智能体编号输入预测神经网络,获取动作空间内不同cre偏置值的单体动作价值函数值,并使用ε-贪婪策略选择动作
56、智能体的输出即为所代表的区域内pbs的cre偏置值。因此,第k智能体的动作ak为:
57、
58、其中,σk表示cre偏置值,所有pbss的cre偏置值构成集合为第k个智能体的动作空间,表示所有可能cre偏置值的集合。多智能体系统内所有智能体的动作构成联合动作a:
59、a={a1,…,ak} (20)
60、步骤3.5、单个智能体执行动作即设定新的cre偏置值后,获取状态信息及环境反馈的奖励奖励设定为基于多智能体强化学习算法动态调整cre偏置值时智能体内所有用户的吞吐量,与不使用cre技术时的系统吞吐量之差的相关函数。对于第k个智能体,其奖励具体定义如下:
61、
62、其中,ci,0表示第i个基站在不使用cre技术时,所关联用户的吞吐量之和,表示动态调整cre偏置值与不使用cre技术时,第k个智能体中pbs的吞吐量总和之差;c0-c0,0表示动态调整cre偏置值与不使用cre技术的系统内mbs的吞吐量之差;μ是奖励调节因子;τk是第k个智能体对mbs吞吐量变化的贡献因子。此处
63、步骤3.6、在全部智能体完成步骤3.1-步骤3.5后,计算全局奖励rt,并且整合获得联合动作at、联合状态信息ot和下一个联合状态信息ot+1,并以(ot,at,rt,ot+1)的形式存入经验池所述全局奖励rt的计算如下:
64、
65、步骤3.7、若经验池中的记录数量小于取样数量nbatch,则令nstep=nstep+1,转入步骤3.3;若经验池中的记录数量大于等于取样数量nbatch,则转入步骤3.8。
66、步骤3.8、从经验池中随机取出一小批量nbatch个经验样本数据,用于训练预测神经网络。
67、步骤3.9、计算目标函数yt,构建神经网络损失函数l(θ),接着再通过小批量梯度下降(mini-batch gradient descent,mbgd)方法更新参数。
68、
69、
70、步骤3.10、更新时间步:nstep=nstep+1并计算系统吞吐量:
71、步骤3.11、若ct=clast,则令nsame_step=nsame_step+1,否则nsame_step=0,clast=ct。
72、步骤3.12、每隔nupdate步更新目标网络参数:θ-=θ。
73、步骤3.13、nepisode=nepisode+1。
74、步骤3.14、若nsame_step≤nsame_step且nstep≤nstep,转入步骤3.3,否则转入步骤3.15。
75、步骤3.15、若nepisode≤nepisode,转入步骤3.2,否则转入步骤4。
76、步骤4、输出阶段:输出系统内微微基站pbs的cre偏置值设定。
77、进一步的,步骤2初始化阶段具体包括:初始化最大训练轮数nepisode、每轮最大训练步骤数nstep、每轮最大相同步骤数nsame_step、学习率ra、折扣因子rd、贪婪策略ε、经验池预测神经网络权重参数θ、目标网络权重参数θ-;初始化系统内pbs的cre偏置值σ0。
78、进一步的,所述步骤3.3中与的计算方式如下:
79、
80、
81、其中,表示关联到第k个智能体中第i个pbs的第u个peue所受到的同频邻区干扰;表示关联到第l个智能体中第i个pbs的第u个peue所受到的干扰强度,表示第l个智能体中第i个pbs的peue数量,1≤i≤nk
82、进一步的,步骤3.5中τk的计算方式如下:
83、
84、本发明提供一种基于值分解网络(value decompositionnetworks,vdn)算法的神经网络训练及更新方式。vdn属于值分解方法中的经典方法之一,采用集中式训练、分布式执行的架构。该算法认为联合动作价值函数qtotoal与每个智能体的单体动作价值函数qm间存在线性加和关系,利用qm的加和来表示qtotoal:
85、
86、其中,qtotoal(ot,at)表示全体智能体的联合动作价值函数,表示单个智能体的单体动作价值函数,nagent表示多智能体数量。在本发明中nagent=k,此时联合动作价值函数qtotoal表示为:
87、
88、vdn方法中的单个智能体可视作一个近似的“深度学习网络(deep q-learning,dqn)结构”。此时,vdn算法的目标值td target及损失函数定义为:
89、
90、
91、其中,rt是t时刻的全局奖励;表示目标神经网络输出的联合动作价值函数,θ-表示与联合动作价值函数相关的所有目标神经网络的参数;qtotoal(ot,at;θ)表示预测神经网络输出的联合动作价值函数,θ表示与联合动作价值函数相关的所有预测神经网络的参数。与qtotoal(ot,at;θ)可分别由目标神经网络及预测神经网络输出的单体动作价值函数根据公式融合而成:
92、
93、
94、其中,表示第m个智能体的目标神经网络参数,θm表示第m个智能体的预测神经网络参数,θ={θ1,…,θk}。
95、本发明的一种基于多智能体强化学习的小区间干扰协调方法,具有以下优点:利用多智能体强化学习算法,将系统内pbs划分为多个智能体,采用集中式训练、分布式执行的算法,使其根据智能体自身及其他智能体中的用户分布及所受干扰情况,单独调整小范围内或单个pbs的cre偏置值,避免了偏置值空间尺寸膨胀、优化难度高的问题,综合考虑全局信息,有效提高了系统吞吐量并且改善系统内单个用户吞吐量。
- 还没有人留言评论。精彩留言会获得点赞!