一种视频的提取方法及装置与流程
本发明属于视频分析,尤其涉及一种视频的提取方法及装置。
背景技术:
1、近年来,随着移动终端,移动通信,以及平台的相继成熟,让很多用户得以充分利用碎片时间拍摄和观看短视频,如何利用已有资源高效转换为信息承载量高短视频,是一个很重要的议题。
2、现有技术中,对于视频的提取主要还是采用人工剪辑的方式,常常会耗费巨大的人力资源,且效率较低。
技术实现思路
1、鉴于上述问题,本技术提出了一种视频的提取方法及装置,可以节省大量人力资源并提高效率,具体方案如下:
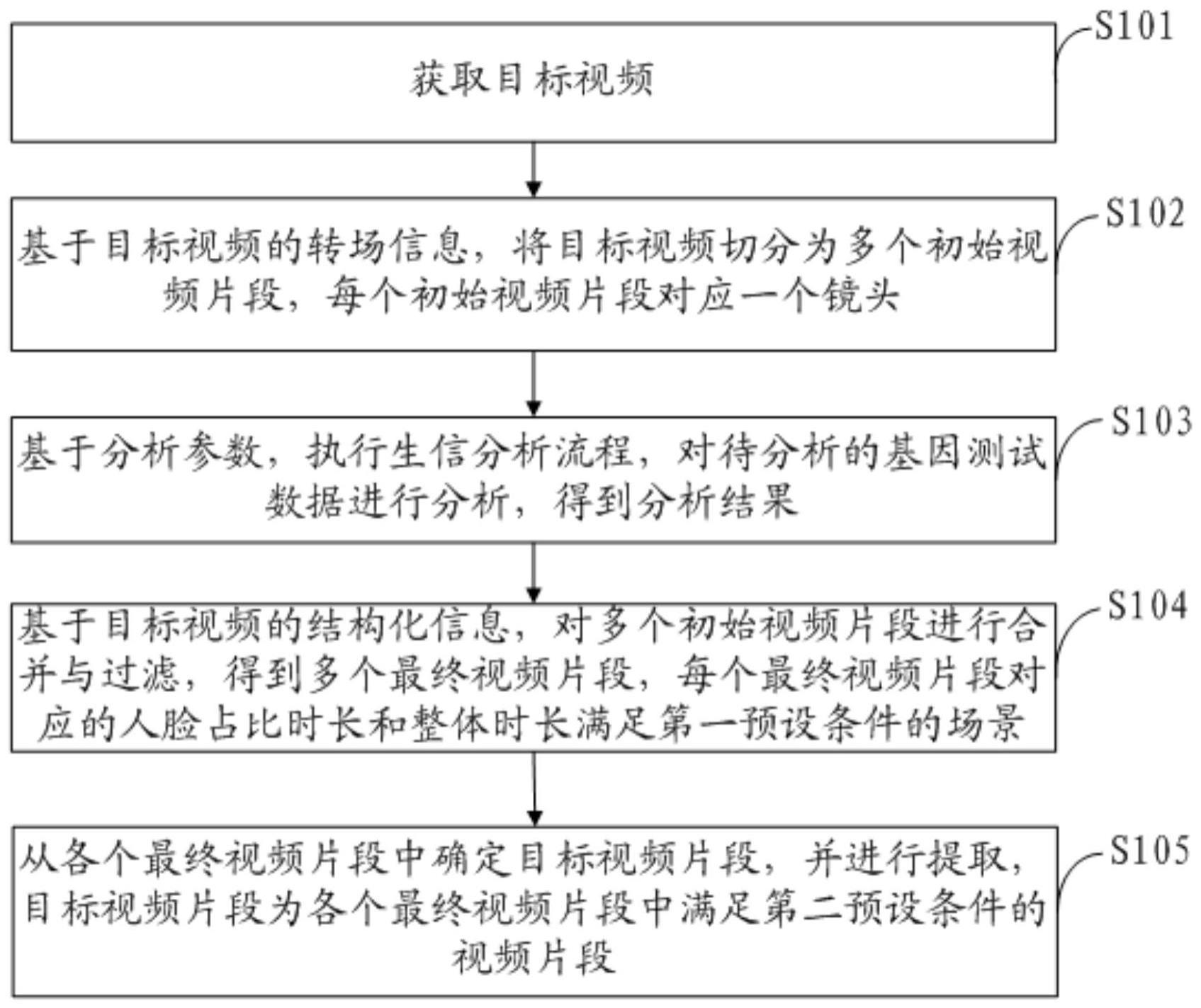
2、一种视频的提取方法,包括:
3、获取目标视频;
4、确定所述目标视频的结构化信息,所述目标视频的结构化信息包括所述目标视频内各个时间点的音频类型信息、人脸信息以及文本信息;
5、基于所述目标视频的转场信息,将所述目标视频切分为多个初始视频片段,每个初始视频片段对应一个镜头;
6、基于所述目标视频的结构化信息,对所述多个初始视频片段进行合并与过滤,得到多个最终视频片段,每个最终视频片段对应的人脸占比时长和整体时长满足第一预设条件的场景;
7、从各个所述最终视频片段中确定目标视频片段,并进行提取,所述目标视频片段为各个所述最终视频片段中满足第二预设条件的视频片段。
8、可选的,所述基于所述目标视频的结构化信息,对所述多个初始视频片段进行合并与过滤,得到多个最终视频片段,包括:
9、基于各个所述初始视频片段的结构化信息,对各所述初始视频片段进行合并,得到第一合并结果,所述第一合并结果包括多个第一视频片段;
10、基于各个所述第一视频片段的结构化信息,对所述第一合并结果中的各所述第一视频片段进行合并,得到第二合并结果,所述第二合并结果包括多个第二视频片段;
11、基于各个所述第二镜头片段的结构化信息,对所述第二合并结果中的各所述第二视频片段进行合并,得到第三合并结果,所述第三合并结果包括多个第三视频片段;
12、对所述第三合并结果中各所述第三视频片段进行过滤,得到多个最终视频片段。
13、可选的,所述基于各个所述初始视频片段的结构化信息,对各所述初始视频片段进行合并,得到第一合并结果,包括:
14、从所述多个初始视频片段中确定当前视频片段以及与所述当前视频片段相邻的后一初始视频片段;
15、基于所述当前视频片段的结构化信息,以及所述后一初始视频片段的结构化信息,确定所述当前视频片段与所述后一初始视频片段之间是否连续;
16、如果所述当前视频片段与所述后一初始视频片段之间连续,则将所述当前视频片段与所述后一初始视频片段进行合并后作为新的当前视频片段,如果所述当前视频片段与所述后一初始视频片段之间不连续,则将所述后一初始视频片段作为新的当前视频片段,继续执行合并步骤直至最后一个初始视频片段处理完毕,得到第一合并结果。
17、可选的,所述初始视频片段的结构化信息的属性包括id集合;所述基于所述当前视频片段的结构化信息,以及所述后一初始视频片段的结构化信息,确定所述当前视频片段与所述后一初始视频片段之间是否连续,包括:
18、判断所述当前视频片段的结构化信息的id集合和所述后一初始视频片段的结构化信息的id集合是否一致;
19、若一致,则确定所述当前视频片段与所述后一初始视频片段之间连续;
20、若不一致,则确定所述当前视频片段与所述后一初始视频片段之间不连续。
21、可选的,所述基于各个所述第一视频片段的结构化信息,对所述第一合并结果中的各所述第一视频片段进行合并,得到第二合并结果,包括:
22、从所述多个第一视频片段中确定当前视频片段以及与所述当前视频片段相邻的后一第一视频片段;
23、基于所述当前视频片段的最后一个结构化信息,以及所述后一第一视频片段的第一个结构化信息,确定所述当前视频片段与所述后一第一视频片段之间是否连续;
24、如果所述当前视频片段与所述后一第一视频片段之间连续,则将所述当前视频片段与所述后一第一视频片段进行合并后作为新的当前视频片段,如果所述当前视频片段与所述后一第一视频片段之间不连续,则将所述后一第一视频片段作为新的当前视频片段,继续执行合并步骤直至最后一个第一视频片段处理完毕,得到第二合并结果。
25、可选的,所述第一视频片段的结构化信息的属性包括起始时间;所述基于所述当前视频片段的最后一个结构化信息,以及所述后一第一视频片段的第一个结构化信息,确定所述当前视频片段与所述后一第一视频片段之间是否连续,包括:
26、基于所述当前视频片段的最后一个结构化信息的起始时间和所述后一第一视频片段的第一个结构化信息的起始时间,确定时间间隔,并判断所述时间间隔是否小于第一预设阈值;
27、若所述时间间隔小于所述第一预设阈值,则判断所述当前视频片段的最后一个结构化信息与所述后一第一视频片段的第一个结构化信息的类型是否一致;
28、若一致,则确定所述当前视频片段与所述后一第一视频片段之间连续;
29、若不一致或所述时间间隔不小于所述第一预设阈值,则判断所述当前视频片段的最长时间占比人脸信息和所述后一第一视频片段的最长时间占比人脸信息是否一致;
30、若所述当前视频片段的最长时间占比人脸信息和所述后一第一视频片段的最长时间占比人脸信息一致,则确定所述当前视频片段与所述后一第一视频片段之间连续;
31、若所述当前视频片段的最长时间占比人脸信息和所述后一第一视频片段的最长时间占比人脸信息不一致,则确定所述当前视频片段与所述后一第一视频片段之间不连续。
32、可选的,所述基于各个所述第二镜头片段的结构化信息,对所述第二合并结果中的各所述第二视频片段进行合并,得到第三合并结果,包括:
33、从所述第二合并结果中确定目标第二视频片段,所述目标第二视频片段为所述第二合并结果中满足第三预设条件的第二视频片段;
34、从所述目标第二视频片段中确定当前视频片段和与所述当前视频片段相邻的后一目标第二视频片段;
35、基于所述当前视频片段的结构化信息和所述后一目标第二视频片段的结构化信息,确定所述当前视频片段和所述后一目标第二视频片段是否连续;
36、如果所述当前视频片段与所述后一初始视频片段之间连续,则合并所述当前视频片段和所述后一目标第二视频片段及之间的第二视频片段,并将合并后的作为新的当前视频片段,如果所述当前视频片段与所述后一初始视频片段之间不连续,则将后一目标第二视频片段作为新的当前视频片段,继续执行合并步骤直至最后一个目标第二视频片段处理完毕,得到第三合并结果。
37、可选的,所述第二视频片段的结构化信息包括所述第二视频片段内各个时间点的音频类型信息和人脸信息;所述基于所述当前视频片段的结构化信息和所述后一目标第二视频片段的结构化信息,确定所述当前视频片段和所述后一目标第二视频片段是否连续,包括:
38、基于所述当前视频片段的音频类型信息和所述后一目标第二视频片段的音频类型信息,确定音频类型相似度;
39、基于所述当前视频片段的人脸信息和所述后一目标第二视频片段的人脸信息,确定人物相似度;
40、判断所述音频类型相似度和所述人物相似度是否满足第二预设阈值;
41、若所述音频类型相似度和所述人物相似度满足所述第二预设阈值,则确定所述当前视频片段和所述后一目标第二视频片段连续;
42、若所述音频类型相似度和所述人物相似度不满足所述第二预设阈值,则确定所述当前视频片段和所述后一目标第二视频片段不连续。
43、可选的,所述最终视频片段的结构化信息包括所述最终视频片段内各个时间点的音频类型信息,所述音频类型信息包括音乐和/或对话;所述从各个所述最终视频片段中确定目标视频片段,并进行提取,包括:
44、基于所述最终视频片段的结构化信息,对所述最终视频片段进行动作识别,得到目标视频片段,所述目标视频片段为满足各个时间点的音频类型信息为音乐且动作识别为目标类别的所述最终视频片段;或满足各个时间点的音频类型信息为音乐和对话,整体时长大于第四预设阈值,动作识别为目标类别且动作识别的类别置信度大于等于第五预设阈值的所述最终视频片段。
45、一种视频的提取装置,包括:
46、获取单元,用于获取目标视频;
47、确定单元,用于确定所述目标视频的结构化信息,所述目标视频的结构化信息包括所述目标视频内各个时间点的音频类型信息、人脸信息以及文本信息;
48、切分单元,用于基于所述目标视频的转场信息,将所述目标视频切分为多个初始视频片段,每个初始视频片段对应一个镜头;
49、处理单元,用于基于所述目标视频的结构化信息,对所述多个初始视频片段进行合并与过滤,得到多个最终视频片段,每个最终视频片段对应的人脸占比时长和整体时长满足第一预设条件的场景;
50、提取单元,用于从各个所述最终视频片段中确定目标视频片段,并进行提取,所述目标视频片段为各个所述最终视频片段中满足第二预设条件的视频片段。
51、基于上述技术方案,本发明提供的视频的提取方法及装置,在获取目标视频之后,确定目标视频的结构化信息,基于目标视频的转场信息,将目标视频切分为多个初始视频片段,每个初始视频片段对应一个镜头,基于目标视频的结构化信息,通过多种深度学习的方法对多个初始视频片段进行合并与过滤,得到多个最终视频片段,每个最终视频片段对应的人脸占比时长和整体时长满足第一预设条件的场景,通过动作识别从各个最终视频片段中确定目标视频片段,并进行提取,目标视频片段为各个最终视频片段中满足第二预设条件的视频片段,可以从目标视频高效提取信息承载量高的目标视频片段,且节省了大量人力资源。
- 还没有人留言评论。精彩留言会获得点赞!