一种在大数据量环境下的实时异常检测系统
本发明涉及网络数据监控,具体而言,涉及一种在大数据量环境下的实时异常检测系统。
背景技术:
1、网络异常通常指网络运营偏离正常网络行为的情况,造成异常的原因包括很多种,例如网络过载、蠕虫网络入侵、路由策略修改以及分布式拒绝服务(ddos)攻击。网络流量异常是网络异常中最常见的威胁。网络异常流量可能导致中心网络速率降低甚至引起网络瘫痪,会对网络环境造成严重的损坏。
2、在过去的几年中,机器学习在异常识别、分类取得了很高的准确性,然而将机器学习方法应用到实际生产环境中功能性方面取得很精确性的成功,但性能仍然存在许多挑战,其中一个挑战就是在时效性。传统有监督学习算法的分类过程是在分类模型训练好的前提下,将待评估检测的数据通过模型去预测分类。这时存在两种情况,如果接入网关侧将流量数据持久化成pcap包时间策略设置过长,则实时性检测时效性大打折扣;若时间策略设置过短,则每次完成打包后系统中就要从磁盘中加载模型,这个过程频繁发生会使得检测效率低下。
3、在模型优化方面,当有新的带标签的数据集到来时,我们优化模型重新上传到系统,这个过程首先会让系统整体停顿然后更换模型重新上线,这一过程可能会导致一段时间内系统不可用,在不可用的时间段内流量数据会丢失,无法检测。
4、除此之外,在完成检测工作后,传统关系型数据库对于大数据量环境下异常检测结果的查询工作在时间性能方面也是存在巨大挑战。虽然传统数据库在查询方面做出了许多优化,例如优化索引和主从分离等手段,但是在数据量到达千万级别时效果甚微,可能会造成系统界面长时间停顿甚至与数据库连接中断不可用。
5、针对于上述描述,我们发现目前的网络异常检测方法存在的缺陷主要是以下三个方面:
6、1)在特征提取和分类预测过程中,cicflowmeter在生成特征流量数据时,需要计算出流量数据包所有数据以及将数据落盘到磁盘后,再进行预测,导致效率低下,实时性较差;
7、2)在主业务中会进行额外的数据同步操作,使得数据检索和存储性能较低;
8、3)流量密集时,处理速度不能与之匹配可能会导致流量数据丢失,性能较差。
技术实现思路
1、本发明在于提供一种在大数据量环境下的实时异常检测系统,其能够缓解上述问题。
2、为了缓解上述的问题,本发明采取的技术方案如下:
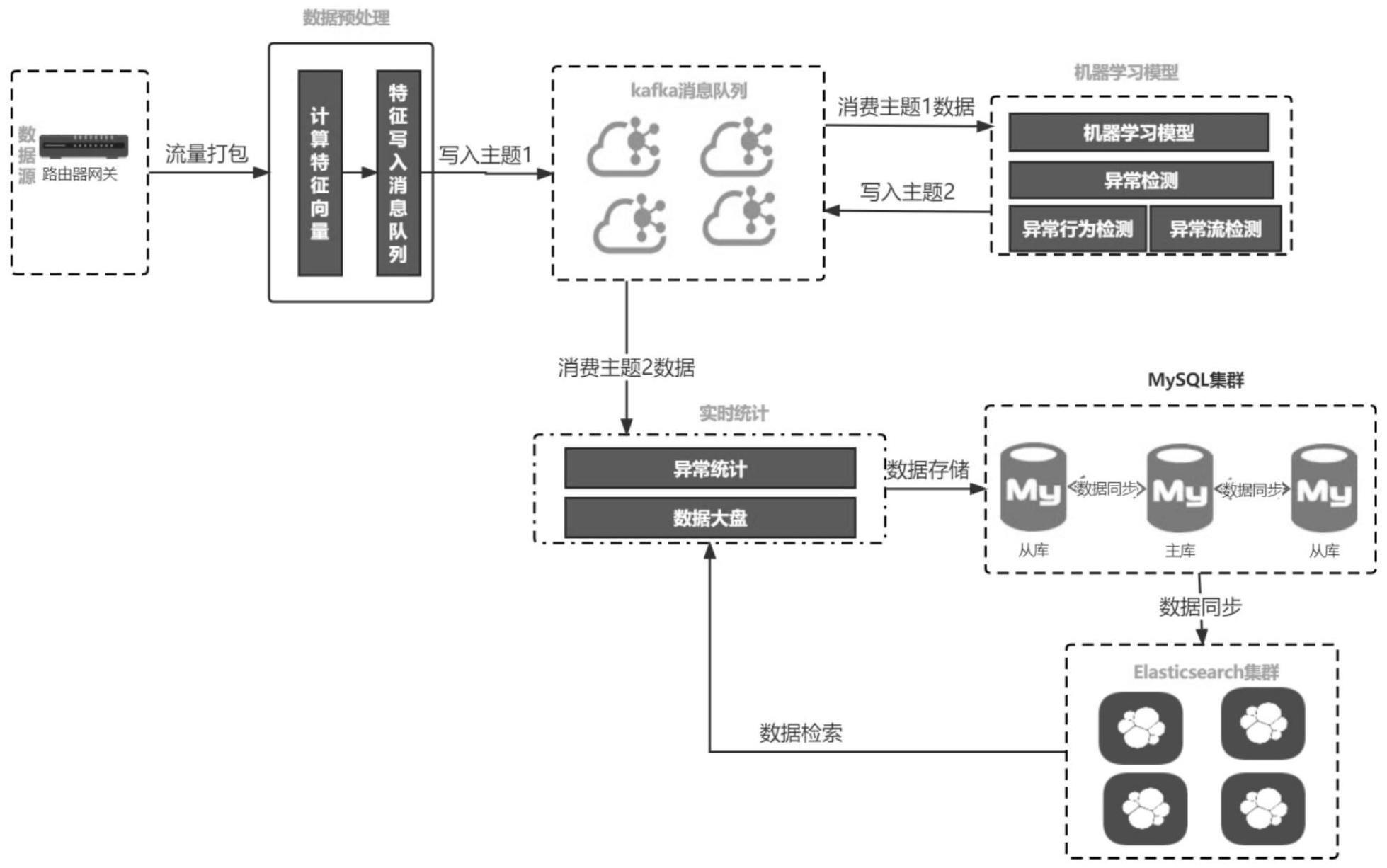
3、一种在大数据量环境下的实时异常检测系统,实时异常检测系统的异常检测流程包括以下步骤:
4、s1、启动实时异常检测系统,同时加载机器学习模型;
5、s2、将系统接入侧路由器网关的流量打包,得到流量数据包;
6、s3、通过cicflowmeter软件计算得到流量数据包的特征数据,并发送至消息队列;
7、s4、机器学习模型从消息队列获取特征数据,并采用多检测线程的方式,同时对多个特征数据进行异常检测,得到异常检测结果,并写入消息队列;
8、s5、实时统计模块从消息队列获取异常检测结果,并进行数据统计,得到异常统计结果;
9、s6、实时统计模块将异常检测结果,以及异常统计结果发送至mysql集群,mysql集群对异常检测结果和异常统计结果进行添加持久化操作,并将新增变动的数据同步至elasticsearch集群;
10、s7、elasticsearch集群根据新增变动的数据,进行数据查询,并将查询结果返回至实时统计模块的数据大盘。
11、在本发明的一较佳实施方式中,步骤s3中,cicflowmeter软件每计算出一条特征数据,则发一条未发往消息队列的特征数据至消息队列。
12、在本发明的一较佳实施方式中,步骤s3中,实时异常检测系统采用调用的方式获取cicflowmeter软件服务,且cicflowmeter软件内部持久化策略修改为发送计算得到的特征数据到消息队列。
13、在本发明的一较佳实施方式中,在启动实时异常检测系统时,将机器学习模型直接加载到系统运行工作内存中,机器学习模型订阅消息队列中对应的流量特征主题,获取该主题对应的特征数据。
14、在本发明的一较佳实施方式中,步骤s6中,mysql集群与elasticsearch集群数据同步,具体包括以下步骤:
15、s61、监听mysql集群的binlog日志,获取变动数据;
16、s62、根据变动数据的操作类型,将变动数据转换为不同类型的对象;
17、s63、将变动数据对应的数据库表、操作类型以及不同类型的对象初始化为binlog传输服务对象;
18、s64、将binlog传输服务对象转换为json类型并发送到消息队列中的数据同步主题;
19、s65、初始化添加/删除/更新列表,对从消息队列的数据同步主题接收到的数据对象操作类型,即binlog传输服务对象的操作类型进行分类,并添加到操作类型对应的列表中;
20、s67、根据不同的变动数据的操作类型,生成不同的请求方法发送到elasticsearch实现数据同步。
21、在本发明的一较佳实施方式中,步骤s7中,海量数据检索中使用elasticsearch检索,具体步骤如下:
22、s71、根据用户界面输入的查询条件,生成数据请求体;
23、s72、将数据请求体发送到es集群获取数据响应体;
24、s73、若响应成功,则从数据响应体中抽出数据对应的主键索引集合后,执行步骤s74,否则根据数据请求体直接在mysql集群进行全表查询后跳转至步骤s75;
25、s74、根据主键索引集合到mysql集群进行反表查询;
26、s75、根据获取到查询结果,返回给用户。
27、在本发明的一较佳实施方式中,实时异常检测系统基于查询结果,采用docker-kubernetes批量滚动更新机器学习模型。
28、与现有技术相比,本发明的有益效果是:
29、提出了在特征提取和分类预测模型中实现流式处理的流程,cicflowmeter在生成特征流量数据时,不再需要计算出流量数据包所有数据以及将数据落盘到磁盘后,再进行预测,而是引入消息队列中间件,减少落盘过程以及提前预测时间,进一步提升实时性。
30、提出elasticsearch和mysql主从架构做为海量数据异常检索,结合elasticsearch高性能的全文检索以及mysql高可靠的持久化存储,利用各自搜索存储引擎的优点,同时在数据更新同步方面设计专门的同步模块,不会在主业务中进行额外的数据同步操作,使得数据检索和存储性能大大提升。
31、搭建kubernetes服务器,是针对于流量密集场景下,核心检测部分下线更新重新上线的过程,为了防止流量密集过多避免消息队列中流量丢失的现象,在系统中更新完分类模型后,使用kubernetes滚动更新,保证业务时刻在线上运行,同时kubernetes也可以监控系统cpu使用情况过多也就是异常检测流量数据过多,异常检测线程使用过多的情况下也可以实现系统水平迁移,保证数据不丢失以及提升系统实时性。
32、为使本发明的上述目的、特征和优点能更明显易懂,下文特举本发明实施例,并配合所附附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!