一种广播电视新闻视频转图文稿制作系统和制作方法与流程
本发明涉及广播电视新闻媒资内容制作领域,更为具体的,涉及一种广播电视新闻视频转图文稿制作系统和制作方法。
背景技术:
1、随着计算机算力的提升以及相关视觉、nlp技术的成长,运用人工智能等技术为媒体机构和内容创作者提供通用型创作工具,提升内容生成与分发效率,助力媒体深度融合也逐渐成为一种趋势。在这种环境下,百度、知乎等各大厂商都相继推出了“图文转视频”的工具或功能。对内容创作者来说,市面上的这些“图文转视频”工具足以满足他们的需求,相关用户可以快速上手,借助“图文转视频”工具自动实现配音、字幕、画面的视频内容生产。
2、然而,要想提升传统主流媒体在新媒体领域的话语权和影响力,除“图文转视频”外,“视频转图文”能力也必不可少。地方电视台等传统主流媒体客户都有自己的新媒体传播矩阵(比如微信公众号、微博等),传播矩阵里不可避免的更多的是图文形式的稿件,纯靠人工将新闻视频转化为图文稿再进行分发耗时耗力,也容易丢失新闻的时效性。“视频转成图文稿”能力可以方便用户将电视新闻视频快速转化为图文稿件以在新媒体渠道进行传播,点对点推送到用户手中,提高新闻宣传的时效性和用户满意度。就目前调研情况来看,市面上还没有“视频转图文”的相关产品雏形。现有技术中,视频转图文稿的产品和相关技术存在空缺。并且,现有技术制作的图文稿存在可读性较差,制作效率低的技术问题。
技术实现思路
1、本发明的目的在于克服现有技术的不足,针对视频转图文稿产品和技术的空缺,提供一种广播电视新闻视频转图文稿制作系统和制作方法,提升图文稿制作效率,增强图文稿可读性,填补了空白。
2、本发明的目的是通过以下方案实现的:
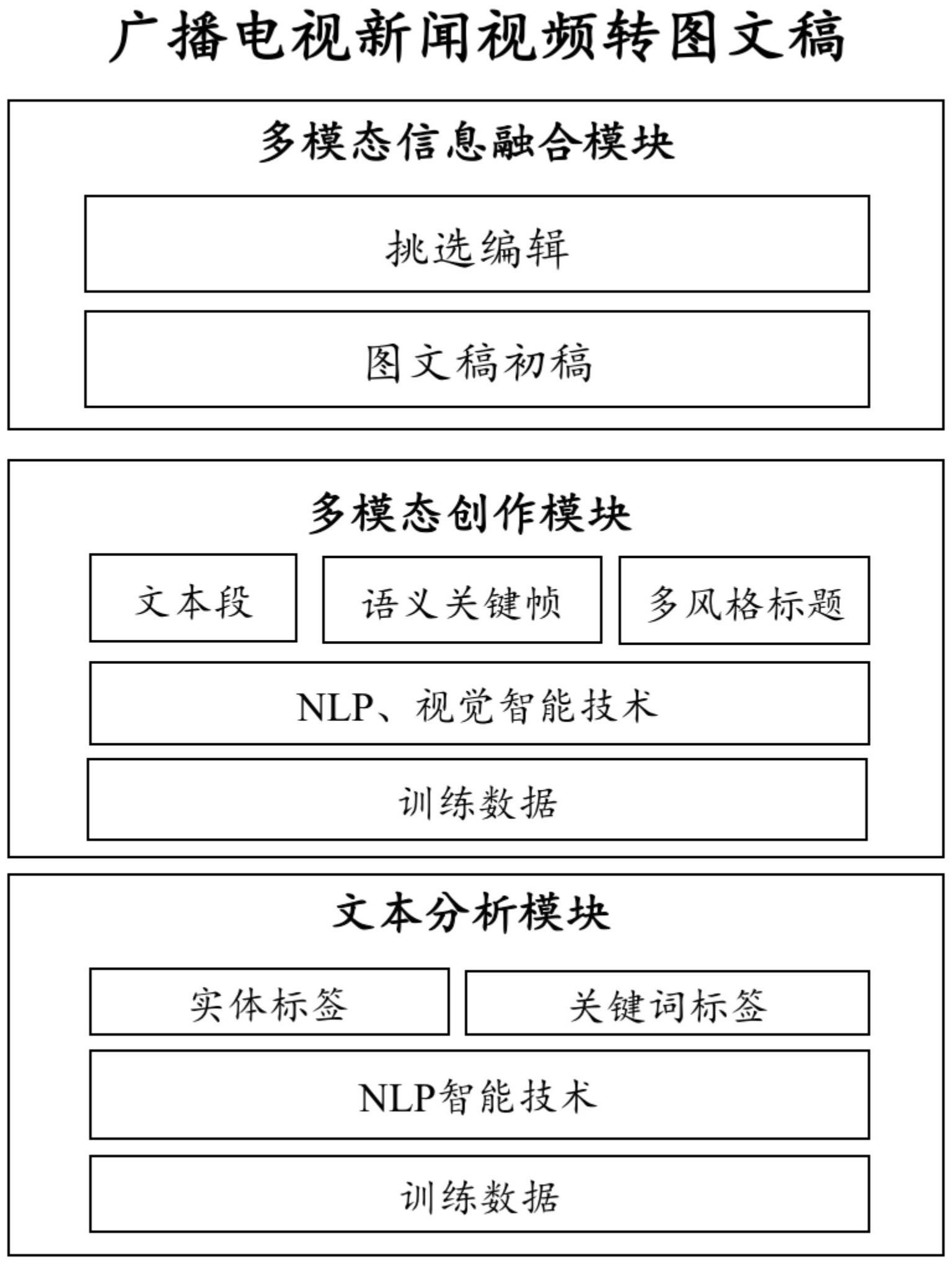
3、一种广播电视新闻视频转图文稿制作系统,其特征在于,包括:
4、文本分析模块,用于提取输入视频的文本标签;
5、多模态创作模块,用于将输入视频的语音文本内容分段,并为每个段落提取语义相关的关键帧,并生成多种风格的候选标题;
6、多模态信息融合模块,用于基于入出点对齐关键帧、分段文本与文本标签以形成图文稿初稿,并在编辑工具中分段呈现;其中,每个段落除文本信息外,还配有相应的候选关键帧、文本标签,同时还呈现有整个图文稿的候选标题。
7、进一步地,所述文本分析模块包括语音识别结果分析子模块,用于对输入视频的语音识别结果进行分析,以提取相关文本标签。
8、进一步地,所述文本分析模块包括文本纠错子模块、标点补全子模块、实体提取子模块和关键词提取子模块中的一个或多个。
9、进一步地,所述多模态创作模块包括人脸识别子模块、转场识别子模块、场景识别子模块、同期声识别子模块、文本分段子模块、语义关键帧提取子模块和多风格标题生成子模块中的一个或多个。
10、进一步地,还包括训练数据模块,所述训练数据模块内的训练数据包括新闻视频数据和新闻文本数据;所述文本分析模块与多模态创作模块利用所述训练数据来优化和提升准确率。
11、一种广播电视新闻视频转图文稿制作方法,包括如下步骤:
12、s1,提取输入视频的文本标签;
13、s2,多模态创作:生成分段文本、相应关键帧和多种风格的候选标题;
14、s3,多模态信息融合:基于入出点对齐关键帧、分段文本与文本标签以形成图文稿初稿,并在编辑工具中分段呈现;其中,每个段落除文本信息外,还配有相应的候选关键帧、文本标签,同时还呈现整个图文稿的候选标题。
15、进一步地,在步骤s1中,所述提取输入视频的文本标签,包括子步骤:
16、s11,利用语音识别获得输入视频的语音文本;
17、s12,利用文本纠错子模块对s11中获得的语音文本进行纠错;
18、s13,利用标点补全子模块对s12中纠错后的语音文本进行标点补全;
19、s14,利用实体提取子模块提取s13中标点补全后的语音文本中的实体标签;
20、s15,利用关键词提取子模块提取s13中标点补全后的语音文本的关键词标签。
21、进一步地,在步骤s2中,所述生成分段文本、相应关键帧和多种风格的候选标题,包括子步骤:
22、s21,利用转场识别子模块将新闻视频分割为多个片段;
23、s22,利用同期声识别子模块判断s21中每个片段的音频是否为同期声;
24、s23,利用人脸识别子模块、场景识别子模块结合判断s21中每个片段是否为演播室;
25、s24,结合s23中演播室结果、s22中同期声结果,利用文本分段子模块对s13中标点补全后的语音文本进行分段,并给出每个段落的类别。
26、进一步地,在步骤s24中,所述结合s23中演播室结果、s22中同期声结果,利用文本分段子模块对s13中标点补全后的语音文本进行分段,并给出每个段落的类别,具体包括子步骤:
27、s241,将连续的演播室片段合并,并使其单独成段;
28、s242,将步骤s241中剩余非演播室片段中的连续同期声片段合并,并使其单独成段;
29、s243,对步骤s242中余下的连续的非演播室非同期声片段,利用文本分段子模块整合后,依据整合后的内容长度自适应地分段;
30、s244,给出新闻视频的所有分段结果以及每个段落的类别;
31、s245,对视频进行分析,为每个文本段提取语义关键帧,具体为:在每段文本对应的视频入出点内,结合相关人脸识别结果、文本标签提取结果,利用语义关键帧提取子模块为每个文段获得候选关键帧,输出的每个候选关键帧带有相应的置信度。
32、进一步地,所述类别包括“演播室”、“非演播室-同期声”、“非演播室-非同期声”。
33、本发明的有益效果包括:
34、(1)本发明填补了本领域市场产品空白和相应技术空缺。
35、(2)本发明利用多种智能技术,对广播电视新闻视频进行识别、提炼和分析,生成图文稿初稿,让编辑人员可以高效地在图文稿初稿上进行二次加工和编辑,极大提升图文稿制作效率。
36、(3)本发明利用多种智能技术对广播电视新闻进行分析和提炼创作,高效生成图文稿,并提供了多风格的候选标题、多角度的文本标签以及带置信度的候选关键帧,能够让编辑人员迅速了解新闻视频内容,将更多的精力投入到新闻视频的相应图文稿的二次加工和创作上,极大提升图文稿制作效率。其中,本发明的多模态创作模块利用nlp技术、视觉图像技术和语音技术将不可用的视频语音转换成可用的图文稿文本,并为每个文本段落赋予了与其语义相关的视频关键帧,避免了图不对文或文不对图的简单堆砌,增强了图文稿的可读性。其中,本发明将分析结果直接呈现在编辑工具中,分段呈现,每个段落除文本信息外,还配有相应的候选关键帧、文本标签等,同时还将呈现多风格的候选标题,加强了智能分析结果与编辑工具的联动,让编辑人员可以根据图文稿将要投放的新媒体渠道(如微信公众号、微博等)灵活且快速地进行关键帧的选择、标签、标题的选择以及相关段落文本的改写等。
- 还没有人留言评论。精彩留言会获得点赞!