基于细粒度状态引导的协议漏洞挖掘测试方法与系统
本发明属于协议自动化安全检测,具体涉及基于细粒度状态引导的协议漏洞挖掘测试方法与系统。
背景技术:
1、协议模糊测试是一种自动化的协议漏洞挖掘测试技术,它通过向待测协议实体程序输入大量随机、不合法或未预料的数据,以期发现其潜在的漏洞或异常。为了使网络协议模糊测试过程中生成的测试用例更加符合协议规范的要求,提升测试用例的接受率,并且与此同时提升对协议实体程序代码的覆盖率。近年来,相关研究工作提出了基于语法生成与覆盖信息引导的模糊测试方法,解决了协议测试过程中存在的大量报文变异操作破坏报文的结构格式的问题,以及基于语法生成的黑盒协议模糊器缺乏覆盖信息反馈指导的问题。
2、基于语法生成和覆盖信息引导的协议漏洞挖掘测试相关工作有:peach*,pavfuzz,z-fuzzer与epf等。z-fuzzer在基于语法生成的黑盒协议模糊器boofuzz上引入覆盖信息反馈来指导后续报文变异。epf使用基于群体的模拟退火在模糊化过程中启发式的调度种子库中的测试用例,对种子库中的测试用例进行重组与突变,生成新的测试用例。pavfuzz通过学习不同数据模型的两个字段之间的关系,计算更新每个可变字段的变异权重,引导模糊测试朝着覆盖率最大化的方向进行。peach*在peach的基础上引入了覆盖率反馈机制,利用触发新路径覆盖的测试用例,构造出更高质量的测试用例。
3、现有基于语法生成与覆盖信息引导的协议模糊测试方法利用协议规范事先定义会话模型,以此表示协议实体程序状态转换的条件。但是,由于协议实体程序是复杂的系统,用会话模型表示协议实体程序的状态转换条件,粒度过粗,不能准确表示协议实体程序内部状态转换细节,导致模糊器对协议实体程序的状态探索能力较弱,进而限制了模糊器对协议实体程序的代码覆盖能力与漏洞挖掘能力。
技术实现思路
1、本发明提出了一种基于细粒度状态引导的协议漏洞挖掘测试方法。以一种细粒度的方式表示协议实体程序的状态转换,在触发新状态时,生成与之对应的前缀消息链列表,用以保存到达此状态的报文序列信息,通过前缀消息链列表生成报文序列的同时,能够将协议实体程序引导到对应的细粒度状态,并且在每个细粒度状态上进行充分的模糊测试工作,以探索更深层次的分支路径。
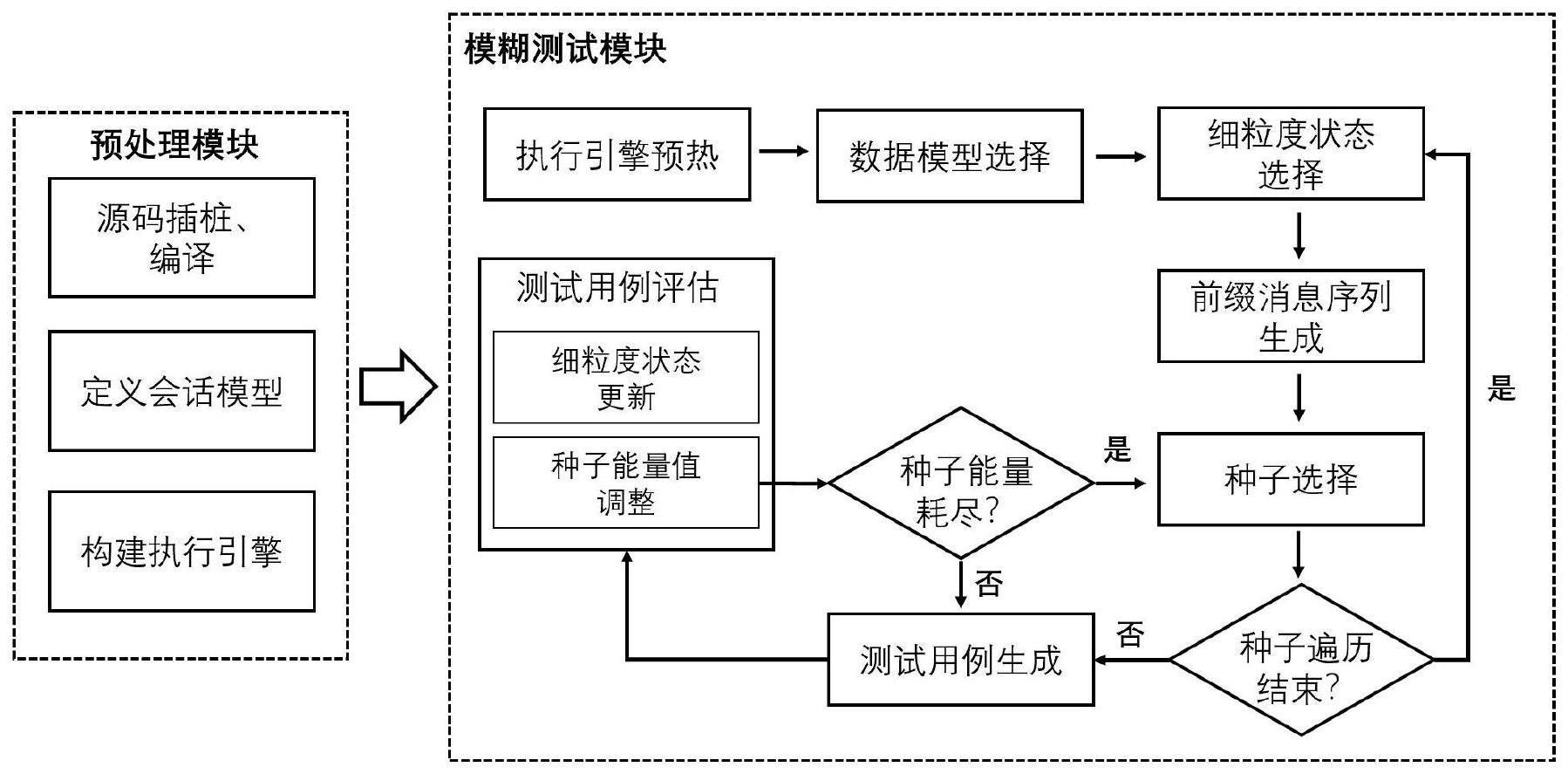
2、该方法分为预处理阶段、模糊测试阶段和结果信息反馈阶段。在预处理阶段,对待测协议实体程序进行插桩编译,得到对应的二进制可执行程序;定义待测协议的会话模型作为模糊测试阶段的输入;根据二进制可执行程序构建执行引擎。模糊测试阶段包含细粒度状态选择、前缀消息序列生成、种子选择、测试用例生成、测试用例评估过程。
3、在模糊测试阶段,利用前缀消息链列表保存触发新状态的测试用例序列信息,利用前缀消息链列表生成异常报文序列的同时准确地定位到该状态,进而在每个状态上进行充分的模糊测试。
4、通过细粒度状态选择过程选择出现阶段测试的状态后,生成与之对应的前缀消息序列,进而通过前缀消息序列将协议实体程序定位到该状态,然后利用种子选择过程所选的种子模板生成测试用例,对该状态进行充分的模糊测试。
5、在结果信息反馈阶段,将模糊测试过程中触发待测协议实体程序崩溃的次数与覆盖信息进行实时的反馈;并且将触发待测协议实体程序崩溃的测试用例加以保存,便于后期对崩溃的重现与分析。
6、本发明提出了一种基于细粒度状态引导的协议漏洞挖掘测试方法,包括三个主要阶段:预处理阶段、模糊测试阶段和结果信息反馈阶段;其中模糊测试阶段包含细粒度状态选择、前缀消息序列生成、种子选择、测试用例生成、测试用例评估过程。
7、在详细介绍本发明之前,先对本发明涉及的名词进行定义:
8、细粒度状态:与传统的程序状态不同,本发明将待测协议实体程序的分支覆盖情况等价为协议实体程序的细粒度状态,如果在模糊测试过程中触发了新的分支覆盖,则认为触发了协议实体程序的新细粒度状态。本发明所指的状态都为细粒度状态。
9、1.预处理阶段:
10、1-1.对协议实体程序源码的插桩编译
11、在模糊测试过程中,为了获取到待测协议实体程序的分支覆盖情况,需要对协议实体程序源码利用aflfast自带的gcc编译工具进行插桩和编译,生成二进制的可执行程序。
12、1-2.定义数据模型集合
13、通过分析待测协议对应的请求数据包并且结合待测协议规范,使用boofuzz模糊测试框架提供的数据模型定义函数来定义协议的数据模型集合modelset={model1,...,modeli,...,modeln},i=1,...,n,其中n为待测协议数据模型总数,所定义的数据模型用以作为生成对应测试用例的协议规范模板。
14、1-3.定义会话模型
15、结合待测协议规范对会话报文序列的要求,使用boofuzz测试框架提供的会话模型定义函数,将modelset中的数据模型连接成会话模型sessionmodels={sessionseq1,...,sessionseqj,...,sessionseqm},j=1,...,m,其中sessionseqj代表会话模型sessionmodels中的一个会话序列,会话序列由数据模型集合modelset中若干个数据模型以一定的前后顺序关系组成,m为会话模型中会话序列的数量。
16、1-4.构建执行引擎
17、运行步骤1-1生成的可执行程序,并且开辟大小为xm字节的共享内存sharemem(xm的大小为经验值,一般设为64k字节),用以实时的统计待测协议实体程序的覆盖信息。
18、2.模糊测试阶段:
19、2-1.系统预热。根据所定义的会话模型中的会话序列依次生成未经过变异的原始报文序列,输入到执行引擎中,完成系统的预热。
20、2-1-1.遍历会话模型sessionmodels,依次遍历取出其中的会话序列sessionseqj;如果会话模型已经遍历结束,则已完成系统预热工作,转向步骤2-2。
21、2-1-2.依据会话序列sessionseqj中数据模型的顺序关系,遍历会话序列sessionseqj得到数据模型modeli,转向步骤2-1-3;如果针对会话序列sessionseqj的遍历工作已完成,重置协议实体程序为初始状态并且转向步骤2-1-1。
22、2-1-3.根据数据模型modeli生成未经过变异的测试用例输入到执行引擎中,将其作为数据模型modeli的种子库seedbanki中的初始种子seedi0(代表种子库seedbanki中的0号种子)。如果当前数据模型modeli不是会话序列sessionseqj中最后一个数据模型,则创建当前数据模型modeli在同一会话序列sessionseqj中下一数据模型modeli+1的初始前缀消息链列表prechainslisti+1={[seedno10,...,seednoi0]},其中seedno10代表当前会话序列sessionseqj中第一个数据模型的初始种子seed10的标号,seednoi0代表当前会话序列sessionseqj中数据模型modeli初始种子seedi0的标号。转向步骤2-1-2,进行下一数据模型的种子库初始化工作。
23、2-2.数据模型选择
24、2-2-1.遍历会话模型sessionmodels,依次取出其中的会话序列sessionseqj;如果会话模型已经遍历结束,则结束模糊测试工作。
25、2-2-2.依据会话序列sessionseqj中数据模型的顺序关系,遍历会话序列sessionseqj得到数据模型modeli,作为当前模糊测试阶段使用的数据模型,转向步骤2-3;如果针对会话序列sessionseqj的遍历已完成,则转向步骤2-2-1。
26、2-3.细粒度状态选择
27、如果数据模型modeli为会话序列sessionseqj中的首个数据模型,则该数据模型modeli不具有前缀消息链列表,直接转向步骤2-5,当前所选的细粒度状态为初始状态,在初始状态上对该数据模型进行模糊测试工作。否则,向下执行步骤2-3-1。
28、2-3-1.遍历数据模型modeli所对应的前缀消息链列表prechainslisti={[seedno10,...,seednoi-10]1,...,[seedno1ki,...,seednoi-1ki]a,...,[seedno1ki,...,seednoi-1ki]b}(a=l,...,b,其中b为前缀消息链列表prechainslisti的行数;其中ki代表对应种子中的种子标号),得到prechainslisti中的前缀消息链行数组[seedno1ki,...,seednoi-1ki]a。如果前缀消息链列表prechainslisti已经遍历结束,则代表已经对当前数据模型modeli所对应的所有状态完成了充分的模糊测试,转向步骤2-2-2,选择会话序列sessionseqj中的下一数据模型modelu+1。
29、2-3-2.以前缀消息链行数组[seedno1ki,...,seednoi-1ki]a作为当前测试的细粒度状态的标记,设为statea=[seedno1ki,...,seednoi-1ki]a(其中seednoi-1ki代表数据模型modeli-1的种子库seedbanki-1中种子seedi-1ki的唯一标号),向下继续执行,生成细粒度状态statea所对应的前缀消息序列。
30、2-4.前缀消息序列生成
31、初始化前缀消息序列为premesssequea=[],根据步骤2-3中所选择的细粒度状态statea=[seedno1ki,...,seednoi-1ki]a,遍历该状态statea所对应的前缀消息链行数组[seedno1ki,...,seednoi-1ki]a,根据种子标号seedno1ki检索数据模型model1的种子库seedbank1,从中取出种子seed1ki,并且将检索种子库得到的种子seed1ki,添加到前缀消息序列premesssequea中;最终遍历到的种子标号为seednoi-1ki,同理,根据种子标号seednoi-1ki检索数据模型modeli-1的种子库seedbanki-1,从中取出种子seedi-1ki,并且将其添加到前缀消息序列中。状态statea所对应的前缀消息链行数组遍历结束后,状态statea所对应的前缀消息序列premesssequea=[seed1ki,...,seedi-1ki]。
32、2-5.种子选择
33、2-5-1.遍历当前数据模型modeli的种子库seedbanki={seedi0,...,seedik,...,seedit},k=1,...,t,其中t为种子库seedbanki中种子的数量,从中依次选择出一个种子seedik。如果种子库中的所有种子已经被遍历结束,则针对当前所选细粒度状态statea的模糊测试工作结束。结束细粒度状态statea的模糊测试工作时,如果当前数据模型modeli为会话序列sessionseqj中的首个数据模型,则转向步骤2-2-2选择新的数据模型;否则,转向步骤2-3-1选择数据模型modeli所对应的其他细粒度状态。
34、2-5-2.对于种子seedik,初始化该种子的能量值seedenergyik=sc,sc的取值为1,初始化该种子的阈值thresholdik=0.0001。
35、2-6.测试用例生成
36、在不破坏所选模板种子seedik有益变异的基础上生成新的测试用例,使用的变异策略为保持种子seedik触发新分支的有益突变,在此基础上依次对其他可变字段进行变异,尽量使生成的新测试用例在仍然触发原有分支的基础上,探索更新的分支。具体步骤如下:
37、2-6-1.获取当前种子seedik对应的数据模型modeli中所有的可变字段在种子seedik中的值fields={field1,...,fieldp,...,fieldq},p=1,...,q,其中q为数据模型modeli中可变字段的总数量。并且初始化变异到的字段位置标记位indexb=0。
38、2-6-2.遍历所有可变字段在种子中的值fields,假设当前遍历到的字段值为rieldp。如果在遍历fields的过程中,已经遍历到了种子的最后字段所在位置,则重置标记位indexb为0,重新开始遍历,使下一轮变异从第一个未变异的字段开始变异。
39、2-6-3.如果遍历到的字段值fieldp是种子seedik中未经过变异的值,并且该字段是处于标记位indexb后面的字段,则利用epf的变异引擎对该字段fieldp进行变异,得到当前字段fieldp的变异结果mutated_rieldp,并且将标记位indexb置为p;否则转向步骤2-6-2继续遍历fields。
40、2-6-4.使用当前字段rieldp的变异结果mutated_fieldp替换种子seedik对应的字段值,得到新生成的测试用例testcase。
41、2-6-5.将新生成的测试用例testcase连接到步骤2-4中所得到的当前状态statea所对应的前缀消息序列premesssequea=[seed1ki,...,seedi-1ki]后部,得到完整消息序列messseque=[seed1ki,...,seedi-1ki,testcase]。并且将报文序列messseque注入执行引擎。
42、2-7.测试用例评估
43、根据执行引擎的分支覆盖反馈信息newbranch,决定是否将本轮模糊测试中生成的新测试用例testcase作为种子添加到当前数据模型的种子库seedbanki中,并且对当前种子seedik的能量值进行动态的调整;根据执行引擎的分支覆盖反馈信息newbranch,决定是否对会话序列sessionseqj的下一数据模型modeli+1的前缀消息链列表prechainslisti+1进行更新。
44、2-7-1.评估是否触发新分支
45、遍历全局共享内存sharemem,判断当前执行过的测试用例testcase是否触发了新的分支。如果全局共享内存sharemem中出现了新的非零字节,则代表触发了新的分支。如果触发了新分支,置评估结果result=true,把当前的测试用例作为新的种子seedix,将新种子seedix添加到步骤2-2-2中所选择的当前数据模型modeli的种子库seedbanki中。
46、2-7-2.更新下一数据模型的前缀消息链列表
47、如果评估结果result为真,表示触发了协议实体程序新的细粒度状态,则将该状态所对应的消息序列种子标号保存到下一数据模型modeli+1的前缀消息链列表prechainslisti+1中。
48、设将要添加到前缀消息链列表prechainslisti+1中的前缀消息链行数组为premesslinearr=[]。遍历步骤2-6-5中输入到执行引擎的报文序列messseque=[seedlki,...,seedi-1ki,seedix],依次将其中种子在对应数据模型种子库中的标号添加到前缀消息链行数组premesslinearr中,遍历结束后得到premesslinearr=[seedno1ki,...,seednoi-1ki,seednoix]。前缀消息链行数组premesslinearr即代表新的细粒度状态,最后将premesslinearr添加到前缀消息链列表prechainslisti+i中。
49、2-7-3.更新检查种子能量值
50、如果评估结果result为真,则设置能量值seedenergyik为初始值sc;否则,将种子seedik的能量值seedenergyik更新为seedenergyik×α(a为衰减因子,取值小于1,并且大于0,取值越小,种子能量值衰减幅度越大,为了均衡起见,本方法默认取值为0.92);
51、如果现阶段模板种子seedik的能量值seedenergyik<thresholdik,则代表该种子seedik的性能已不佳,转向步骤2-5-1,从种子库seedbanki中选择新的种子,作为现阶段的模板种子;如果该种子能量值seedenergyik>=thresholdik,则转向步骤2-6-2,继续利用该种子生成新的测试用例。
52、3.结果信息反馈阶段:
53、将步骤2-7中根据共享内存统计的分支覆盖信息在页面中进行实时的反馈;将模糊测试过程中触发协议实体程序崩溃的次数进行实时的反馈;并且将触发协议实体程序崩溃的测试用例加以保存,便于后期对崩溃的重现与分析。
54、本发明的另一个目的是提供基于细粒度状态引导的协议漏洞挖掘测试系统fsgfuzz(fine-grained state guidance fuzzer),如图1所示,包括:
55、预处理模块。预处理模块的主要功能为对待测协议实体程序使用aflfast自带的gcc编译工具进行插桩编译,得到对应的二进制可执行程序;使用boofuzz模糊测试框架提供的数据模型定义函数来定义协议的数据模型集合modelset,结合待测协议规范对会话报文序列的要求,将定义的数据模型集合modelset中的数据模型连接成会话模型sessionmodels,作为模糊测试阶段的输入;最后,构建执行引擎。
56、模糊测试模块。模糊测试模块首先对执行引擎进行预热,在预热过程中,创建每个数据模型所对应的初始种子库和初始前缀消息链列表。预热完成后,从预处理模块定义的会话模型sessionmodels中依次选取会话序列,然后依次选取会话序列中的数据模型,得到现阶段测试的数据模型modeli,最后执行其中的细粒度状态选择器、前缀消息序列生成器、种子选择器、测试用例生成器和测试用例评估器:
57、细粒度状态选择器。主要功能为依据当前模糊测试阶段所选择的数据模型modeli,在该数据模型对应的前缀消息链列表prechainslisti的指导下选择出当前阶段要进行集中模糊测试的状态statea。
58、前缀消息序列生成器。在细粒度状态选择器选择出现阶段需要充分测试的状态后,生成与该状态对应的报文序列,以将协议实体程序引导到该状态。
59、种子选择器。负责从当前数据模型modeli的种子库seedbanki中选择现阶段所使用的种子seed,并且初始化所选种子的能量值seedenergy与阈值threshold。
60、测试用例生成器。负责对种子选择器所选的种子进行变异,利用该种子生成新的测试用例。测试用例生成器使用的变异策略为保持种子触发新分支的有益突变,在此基础上依次对其他可变字段进行变异,尽量使生成的新测试用例在仍然触发原有分支的基础上,探索更新的分支。
61、测试用例评估器。根据执行引擎的分支覆盖反馈信息,决定是否将本轮模糊测试中生成的新测试用例作为种子添加到当前数据模型的种子库seedbanki中,并且更新种子选择器所选当前种子的能量值;根据执行引擎的分支覆盖反馈信息,决定是否更新下一数据模型的前缀消息链列表。
62、结果信息反馈模块。根据共享内存统计的分支覆盖信息在页面中进行实时的反馈;将模糊测试过程中触发协议实体程序崩溃的次数进行实时的反馈;并且将触发协议实体程序崩溃的测试用例加以保存,便于后期对崩溃的重现与分析。
63、本发明的有益效果是:
64、1.本发明采用了基于细粒度状态引导的协议漏洞挖掘测试方法,以一种细粒度的方式表示协议实体程序的状态转换,在触发到新的细粒度状态时,生成与新状态对应的前缀消息链列表,用来保存与此状态对应的异常或正常报文序列,通过前缀消息链列表生成异常报文序列的同时,能够将协议实体程序引导到对应的状态,并且在每个状态上进行充分的模糊测试工作,以探索更深层次的分支路径。
65、2.相对于现有基于语法生成与覆盖信息引导的协议模糊测试工具,本发明提出的基于细粒度状态引导的协议漏洞挖掘测试方法,可以有效的解决现有基于语法生成与覆盖信息引导的协议模糊测试方法不能准确表示协议实体程序细节状态转换的问题,提高了模糊测试过程中对目标程序分支的探索能力与漏洞挖掘能力。
- 还没有人留言评论。精彩留言会获得点赞!