基于Q学习的多目标路由规划方法及装置与流程
本发明涉及路由规划,尤其涉及一种基于q学习的多目标路由规划方法及装置。
背景技术:
1、在本地通信网中,通存算业务的复杂性不断增加,不同类型的业务交织存在。对于本地通信典型场景的业务路由传输而言,在网络资源紧张的状态下,为了保证网络可靠性,需要基于节点网络业务状态,在网络中的路由器、交换机等路由转发设备和主机之间合理地进行路由规划。
2、本地通信网中通存算业务对服务质量(quality of service,qos)的需求各不相同,如时延、带宽、时延抖动、丢包率等,在进行路由规划时需要根据不同业务的差异化需求来自适应分配路由,保障网络效益及可靠性。在保证服务质量的同时,路由成本也是本地通信网中一个很重要的关注点,需要平衡好服务质量和路由成本之间的关系。现有的研究大多只考虑服务质量或以加权的形式将成本纳入服务质量中,难以满足本地通信不同业务对服务质量和路由成本的同时考量。
技术实现思路
1、有鉴于此,本发明实施例提供了一种基于q学习的多目标路由规划方法及装置,以解决现有路由规划方法不能同时考量服务质量和路由成本的技术问题。
2、本发明提出的技术方案如下:
3、本发明实施例第一方面提供了一种基于q学习的多目标路由规划方法,包括:
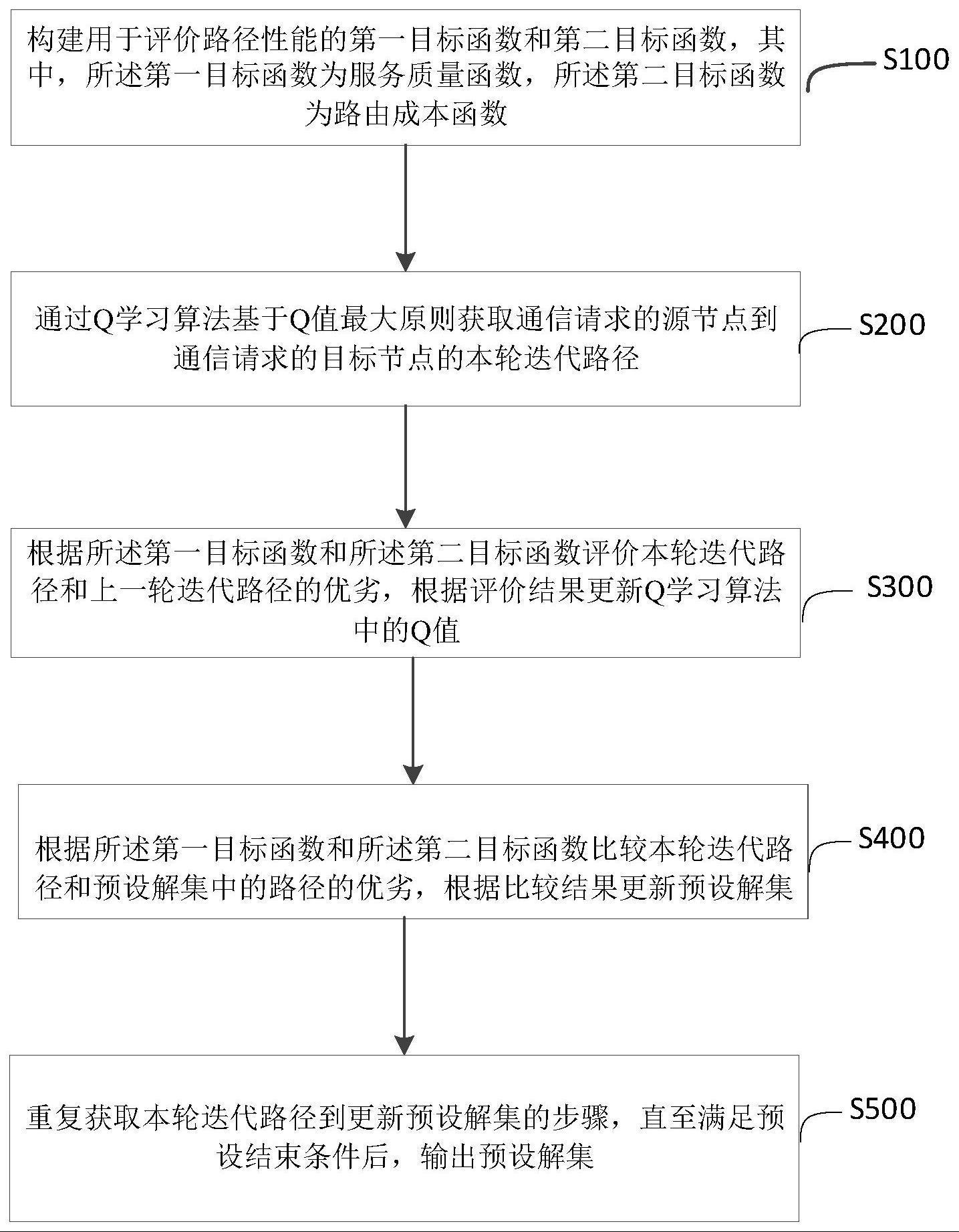
4、构建用于评价路径性能的第一目标函数和第二目标函数,其中,所述第一目标函数为服务质量函数,所述第二目标函数为路由成本函数;
5、通过q学习算法基于q值最大原则获取通信请求的源节点到通信请求的目标节点的本轮迭代路径;
6、根据所述第一目标函数和所述第二目标函数评价本轮迭代路径和上一轮迭代路径的优劣,根据评价结果更新q学习算法中的q值;
7、根据所述第一目标函数和所述第二目标函数比较本轮迭代路径和预设解集中的路径的优劣,根据比较结果更新预设解集;
8、重复获取本轮迭代路径到更新预设解集的步骤,直至满足预设结束条件后,输出预设解集。
9、可选地,根据所述第一目标函数和所述第二目标函数比较本轮迭代路径和预设解集中的路径的优劣,根据比较结果更新预设解集,包括:
10、根据所述第一目标函数的值和所述第二目标函数的值将本轮迭代路径和预设解集中的每一个路径分别进行比较;
11、根据比较结果,若预设解集中存在一路径的所述第一目标函数的值和所述第二目标函数的值均劣于本轮迭代路径对应的值,则将对应的路径从预设解集中删除;
12、若预设解集中的任一路径的所述第一目标函数的值和所述第二目标函数的值均优于本轮迭代路径对应的值,则将本轮迭代路径舍弃;
13、若预设解集中的不存在所述第一目标函数的值和所述第二目标函数的值均优于本轮迭代路径对应的值的路径,则将本轮迭代路径加入预设解集。
14、可选地,通过q学习算法获取通信请求的源节点到通信请求的目标节点的本轮迭代路径,包括:
15、从所述源节点开始,根据当前迭代次数动态调整ε-贪婪算法的探索因子,并基于调整后的ε-贪婪算法选择下一跳的路由,其中,当前迭代次数越大,ε-贪婪算法的探索因子越小;
16、重复上述步骤直至到达所述目标节点并获得本轮迭代路径。
17、可选地,在基于调整后的ε-贪婪算法选择下一跳的路由之后,还包括:
18、判断所述源节点到当前路由的路径是否满足预设约束条件,若满足预设约束条件,则继续采用动态调整的ε-贪婪算法选择下一跳的路由,若不满足,则排除所述源节点到当前路由的路径并返回源节点重新选择下一跳的路由。
19、可选地,根据评价结果更新q学习算法中的q值,包括:
20、根据评价结果更新奖励函数;
21、根据奖励函数更新q学习算法中的q值。
22、可选地,根据评价结果获取奖励函数,包括:
23、若上一轮迭代路径的所述第一目标函数的值和所述第二目标函数的值均优于本轮迭代路径对应的值,则奖励函数的值为第一奖励值;
24、若本轮迭代路径的所述第一目标函数的值和所述第二目标函数的值均优于上一轮迭代路径对应的值,则奖励函数的值为第二奖励值;
25、若上一轮迭代路径的所述第一目标函数的值和所述第二目标函数的值不均优于本轮迭代路径对应的值,且若本轮迭代路径的所述第一目标函数的值和所述第二目标函数的值不均优于上一轮迭代路径对应的值,则奖励函数的值为第三奖励值;
26、其中,所述第一奖励值小于所述第三奖励值,所述第三奖励值小于所述第二奖励值。
27、可选地,构建第一目标函数的过程包括:
28、获取预设服务质量指标并对所述预设服务质量指标进行归一化处理;
29、根据归一化处理后的所述预设服务质量指标构建第一目标函数;
30、构建第二目标函数的过程包括:
31、获取预设路由成本指标并对所述预设路由成本指标进行归一化处理;
32、根据归一化处理后的所述预设路由成本指标构建第二目标函数。
33、可选地,所述预设服务质量指标包括时延、时延抖动、丢包率和带宽;所述预设路由成本指标包括功耗和路径长度。
34、本发明实施例第二方面提供一种基于q学习的多目标路由规划装置,包括:
35、构建模块,用于构建评价路径性能的第一目标函数和第二目标函数;
36、路径获取模块,用于通过q学习算法基于q值最大原则获取通信请求的源节点到通信请求的目标节点的本轮迭代路径;
37、学习模块,用于根据所述第一目标函数和所述第二目标函数评价本轮迭代路径和上一轮迭代路径的优劣,根据评价结果更新q学习算法中的q值;
38、更新模块,用于根据所述第一目标函数和所述第二目标函数比较本轮迭代路径和预设解集中的路径的优劣,根据比较结果更新预设解集;
39、输出模块,用于重复获取本轮迭代路径到更新预设解集的步骤,直至满足预设结束条件后,输出预设解集。
40、可选地,所述更新模块包括:
41、比较模块,用于根据所述第一目标函数的值和所述第二目标函数的值将本轮迭代路径和预设解集中的每一个路径分别进行比较;
42、删除模块,用于根据比较结果,若预设解集中存在一路径的所述第一目标函数的值和所述第二目标函数的值均劣于本轮迭代路径对应的值,则将对应的路径从预设解集中删除;
43、舍弃模块,用于根据比较结果,若预设解集中的任一路径的所述第一目标函数的值和所述第二目标函数的值均优于本轮迭代路径对应的值,则将本轮迭代路径舍弃;
44、加入模块,用于根据比较结果,若预设解集中不存在所述第一目标函数的值和所述第二目标函数的值均优于本轮迭代路径对应的值的路径,则将本轮迭代路径加入预设解集。
45、可选地,所述路径获取模块包括:
46、动作模块,用于从所述源节点开始,根据当前迭代次数动态调整ε-贪婪算法的探索因子,并基于调整后的ε-贪婪算法选择下一跳的路由,其中,当前迭代次数越大,ε-贪婪算法的探索因子越小;
47、重复模块,用于重复上述步骤直至到达所述目标节点并获得本轮迭代路径。
48、可选地,所述路径获取模块还包括:
49、约束判断模块,用于判断所述源节点到当前路由的路径是否满足预设约束条件,若满足预设约束条件,则继续采用动态调整的ε-贪婪算法选择下一跳的路由,若不满足,则排除所述源节点到当前路由的路径并返回源节点重新选择下一跳的路由。
50、可选地,所述学习模块包括:
51、函数更新模块,用于根据评价结果更新奖励函数;
52、q值更新模块,用于根据奖励函数更新q学习算法中的q值。
53、可选地,所述函数更新模块包括:
54、第一奖励值模块,用于若上一轮迭代路径的所述第一目标函数的值和所述第二目标函数的值均优于本轮迭代路径对应的值,则奖励函数的值为第一奖励值;
55、第二奖励值模块,用于若本轮迭代路径的所述第一目标函数的值和所述第二目标函数的值均优于上一轮迭代路径对应的值,则奖励函数的值为第二奖励值;
56、第三奖励值模块,用于若上一轮迭代路径的所述第一目标函数的值和所述第二目标函数的值不均优于本轮迭代路径对应的值,且若本轮迭代路径的所述第一目标函数的值和所述第二目标函数的值不均优于上一轮迭代路径对应的值,则奖励函数的值为第三奖励值;
57、其中,所述第一奖励值小于所述第三奖励值,所述第三奖励值小于所述第二奖励值。
58、可选地,所述构建模块包括:
59、第一目标函数模块,用于获取预设服务质量指标并对所述预设服务质量指标进行归一化处理;根据归一化处理后的所述预设服务质量指标构建第一目标函数;
60、第二目标函数模块,用于获取预设路由成本指标并对所述预设路由成本指标进行归一化处理;根据归一化处理后的所述预设路由成本指标构建第二目标函数。
61、可选地,所述预设服务质量指标包括时延、时延抖动、丢包率和带宽;所述预设路由成本指标包括功耗和路径长度。
62、本发明实施例第三方面提供一种电子设备,包括:存储器和处理器,所述存储器和所述处理器之间互相通信连接,所述存储器存储有计算机指令,所述处理器通过执行所述计算机指令,从而执行如本发明实施例第一方面任一项所述的基于q学习的多目标路由规划方法。
63、本发明实施例第四方面提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使所述计算机执行如本发明实施例第一方面任一项所述的基于q学习的多目标路由规划方法。
64、从以上技术方案可以看出,本发明实施例具有以下优点:
65、本发明实施例提供的一种基于q学习的多目标路由规划方法及装置,构建用于评价路径性能的第一目标函数和第二目标函数,其中,所述第一目标函数为服务质量函数,所述第二目标函数为路由成本函数;通过q学习算法基于q值最大原则获取通信请求的源节点到通信请求的目标节点的本轮迭代路径;根据所述第一目标函数和所述第二目标函数评价本轮迭代路径和上一轮迭代路径的优劣,根据评价结果更新q学习算法中的q值;根据所述第一目标函数和所述第二目标函数比较本轮迭代路径和预设解集中的路径的优劣,根据比较结果更新预设解集;重复获取本轮迭代路径到更新预设解集的步骤,直至满足预设结束条件后,输出预设解集。本发明实施例通过构建的第一目标函数和第二目标函数实现了对路径的服务质量和路由成本的同时考量,并引入q学习方法进行运算,最终获取满足服务质量和路由成本需求的预设解集,能够满足本地通信业务在服务质量和路由成本方面的差异化需求。
- 还没有人留言评论。精彩留言会获得点赞!