一种基于K-means和Softmax逻辑回归模型的机会路由实现方法
本发明涉及机器学习领域和机会网络领域。具体为一种基于k-means和softmax逻辑回归模型的机会路由实现方法。
背景技术:
1、近年来,随着无线通信技术的快速发展(5g技术的兴起)以及智能移动终端设备的广泛普及(例如智能手机、智能联网汽车、智能手表等),移动网络蜂窝流量数据增长迅速,这就给网络基础设施造成了极大的负担。尤其是在高峰时间段的热点地区,短时间内数据流量急剧增多,给蜂窝移动网络基础设施造成了极大的冲击,导致带宽低等。同时,根据蜂窝移动网络的特性,其极其依赖于基础设施的建设普及。这就意味着,若简单对其进行设备升级从而缓解压力,其所需的费用极其昂贵。所以,为了缓解蜂窝移动网络的流量压力,需要进行流量卸载。
2、对于流量卸载,目前主流有三种方法,即通过femtocells的流量卸载、通过wi-fi网络的流量卸载以及通过机会网络的流量卸载。前两种和蜂窝移动网络存在同样的不足,即需要基础设施的支持,但是机会网络对其要求不高。机会网络是一种允许节点在没有建立永久连接,彼此间不存在完整路径的情况下,仅在相互间近距离接触情况下利用低成本的通信建立连接进行信息交流的网络。而车辆间的网络是一种重要的机会网络。由于车辆具有高机动性,并且车辆间近距离通信的技术已经成熟,因此,车辆网络是一个非常合适的选择。
3、对于在车辆网络上进行移动流量卸载,目前已经开展了许多研究。在一个复杂的网络中,为了将信息尽快地传递到目标点,需要关注的主要有初始源选择、后续节点选择、转发策略三大问题。随着人工智能的发展,在优化问题上使用机器学习算法成为了热门的研究方向。在该机会网络问题中引入机器学习算法,从而更好地实现自适应转发消息。目前的已有的算法可以分为两大类,一是使用深度学习模型进行轨迹预测,基于预测结果进行全局效用评估;二是不进行预测,使用机器学习算法对车辆进行特征划分,从而做出更好地选择。对于前者,显然,没有一个预测算法可以做到完美,这就意味着会产生不准确的结果,并且该错误的预测结果将会对系统产生较大的影响。对于后者,虽然其适用于拓扑结构相对稳定的网络,看似与车辆的高机动性相矛盾,但是考虑到现代社会极大部分人的生活具有规律性,这就意味着其所乘坐车辆规律性极强,再加上车辆具有的通信范围并不是很小,因此综合来判断,车辆网络的拓扑结构也是相对有规律的,因此可以选用该种方法。
4、目前k-means算法是一种广泛使用的聚类算法,其较为简单,并且适应性强,但是会受离群点的影响,考虑到多数情况下车辆的聚集性较强,因此问题中的离群点多来自于gps设备数据漂移,产生的错位信号,可以使用lof离群点检测算法去除。而softmax逻辑回归模型则是一种logistic回归模型在多分类问题上的推广,其可以输出目标属于不同类的概率,从而提供不同的选择。因此本发明使用改进后的lof离群点检测算法去除离群点,利用k-means算法划分社区,计算节点的社区契合度以及流通度,结合softmax逻辑回归模型计算“信使节点”,最终实现机会路由最短路径的选择。
技术实现思路
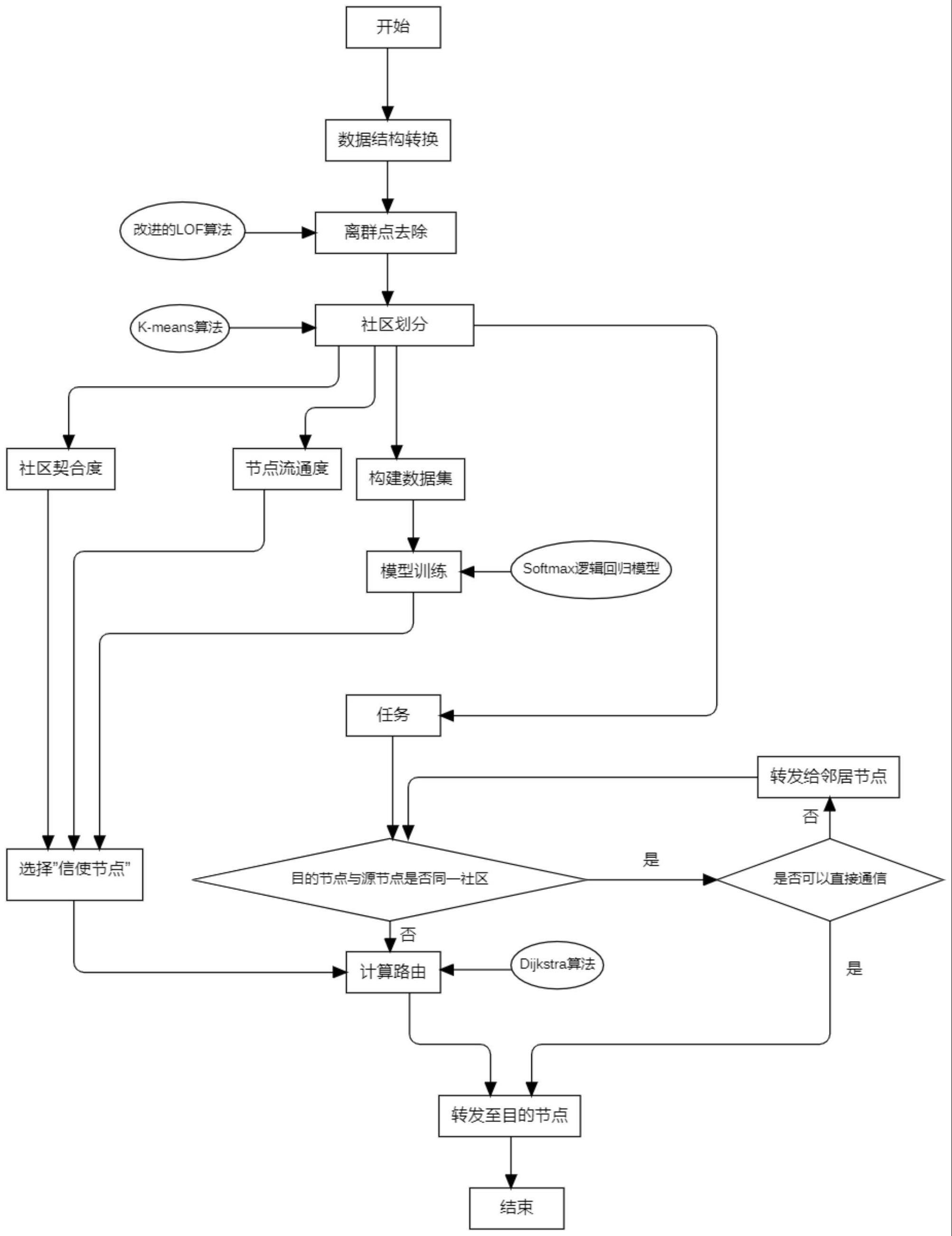
1、本发明提出了一种基于k-means和softmax逻辑回归模型的机会路由实现方法,主要包括以下四大内容:
2、(1)原始gps数据的转化存储和基于lof的离群点去除方法;
3、(2)基于k-means的子社区划分;
4、(3)节点社区契合度和节点流通度计算方法;
5、(4)基于softmax逻辑回归模型的“信使节点”计算及机会路由实现方法;
6、具体内容如下:
7、(1)原始gps数据的转化存储和基于lof的离群点去除方法。
8、在进行社区划分前,需要对数据进行清洗处理,从而提升使用效率。
9、最初从gps设备获取到的数据是十分密集的“点”数据,即,正常情况下间隔几分钟就发送一条gps数据,即使是停车情况下也是这样。这就意味着,如果一辆车在停车场停止数个小时,就会产生非常多的相同坐标的gps信号,所以,首先要对这些“点数据”进行整合,设计了一种数据结构,除了常规的坐标和设备编号外,更改了时间的存储方式,改为存储段时间,即,记录当前坐标第一次报点的时间,记录当前坐标最后一次报点的时间,采用这样的方法可以极大的减小存储的空间,甚至可以将数据文件缩小数十倍。
10、因为k-means对于离群点是敏感的,并且gps信号会因为一些偶然原因导致信号偏移,所以必须进行数据清洗去除离群点。去除离群点的方法有很多,经常使用的是基于统计学方法和基于距离的方法。这些方法对于车辆gps信号来说是不适合的,这种gps信号点不能简单的使用拉依达准则来进行去除,因为,就现实情况而言,gps信号往往具有一定的聚集性,例如在停车场、信号灯路口等地,gps信号非常集中。这样就会导致聚类的质心偏向于该处,如果简单的使用基于统计学、距离等方法来去除,则会导致属于某大聚类的小聚集点被去除,这是不正确的,所以,需要采用基于密度的方法来实现离群点去除。
11、lof离群点检测算法是breunig在2000年提出的一种基于密度的局部离群点检测算法,其核心点如下:
12、reach-distk(o,a)为点o到点a的第k可达距离,若点o到点a的距离d(o,a)小于点o的第k距离dk(o),则reach-distk(o,a)的值为dk(o),若大于,则为d(o,a);
13、lrdk(o)表示点o的第k局部可达密度,即点o的第k距离邻域nk(o)中所有的点到点o的第k可达距离reach-distk(o,a)的平均数的倒数,即:
14、
15、定义lofk(o)表示点o的第k局部离群因子,其将点o的局部可达密度lrdk(o)和nk(o)邻域内所有点的局部可达密度的平均数作比较,即:
16、
17、若比值接近于1,则说明此处点的密度较为平均,即周围点的密度差别不大,意味着这些点是离群点的概率不高,若比值远大于1,则说明此处点o的密度远小于周围其他点,意味着点o是离群的概率非常之大。
18、根据公式(2),离群点判断标准是比值,这就意味着对于一些具有一定密度的离群点,其比值也是接近于1的,所以不会被去除,如果仅通过调整第k邻近距离的k值从而解决该问题,这是不现实的,因为这意味着对于每个数据文件,都需要单独计算其最佳的第k,这样是十分繁琐的,所以,需要一个通用的方案来解决此问题。
19、鉴于以上问题,做出改进。注意到这些特殊的离群点虽然具有一定的密度,但是其第k局部可达密度与那些不是离群点的第k局部可达密度相差较大,造成误判的原因在于公式(2)的比值计算,所以,需在使用公式(2)前进行筛选。基于统计学的规律,使用拉依达准则对其进行判断,进行筛选,将不符合的点去除,接下来再使用公式(2)进行计算即可。
20、(2)基于k-means的子社区划分。
21、k-means聚类算法,英文名称为k-means clustering algorithm,是1967年jamesmacqueen首次在论文中提出的,是一种通过迭代的方式进行聚类分析的算法。步骤是首先选择k个中心点记为k个簇,然后遍历整个节点集合,计算每个节点和中心点间的距离,之后将节点分配至距离其欧氏距离最近的中心点,即分配至簇,接下来计算每个簇的中心点,重复上述过程直至达到循环上限或者是每次变化很小即可。
22、对于k-means算法,需要关注k值的选取,采用“轮廓系数”法,并且进行改进,辅助以sse(误差平方和)进行计算。
23、对与样本点i,定义其凝聚度ai表示其与同聚类的其他点的平均距离,bi表示样本点到距离其所在聚类最近的聚类中的所有点到其的平均距离,最终,轮廓系数计算公式如下:
24、
25、sse的计算公式为:
26、
27、其中,第i簇使用ci来表示,c是ci中的点,而mi表示簇i的质心,则sse表示所有样本点的聚类误差,其大小可以反应k-means聚类效果的好坏。
28、有时单独使用轮廓系数不能达到最优,所以这里使用了sse作为辅助属性,在计算出轮廓系数的同时,计算其sse,最终选择轮廓系数偏大,而sse偏小的k值。
29、基于gps信号的地理性质,k值的选取应符合实际需要。基于实际情况,由于gps数据点分布范围较广,初始数据几乎遍布全国大部分地区,所以,为了提升划分精度,提高划分效率,需要进行自适应的划分。
30、最初的划分范围是全国,此时,根据我国的主要地区的分布情况,将k值设置为10;第二次划分时,范围为省级的,进行划分时,此时该k值将根据此时区域的质心位置,设置为对应省的地级市数量;第三次划分时,此时范围已经精确到了市级,此时,采用前文提到的“轮廓系数”和sse相结合的方法来确定k的值;划分结束后,计算每个簇中距离质心的最远距离,如果该距离大于300米(此为车辆的极限通信距离),则该区域仍然需要进一步划分。
31、在第三次划分开始,需要注意一种特殊情况,区域边境点问题,即,如果某点位于两个簇的交界处,那么这时虽然其会被分到距其最近的簇,但是周围属于另一个簇的点会很多,无论单独划分到哪个簇都是不合理的。所以,此时要进行进一步判断。
32、设有车辆节点a,区域a、区域b,定义distanc(a,a)表示节点a至区域a质心的距离,则distanc(a,b)即表示节点a至区域b质心的距离。设contrast(a,a,b)表示社区a中的点a对社区b的对比度,则:
33、
34、contrast(a,a,b)的值越接近于1,则说明a越靠近a和b的边境。通过该值来判断是否为边境点。
35、设mirror(a,a,b)表示点a关于a和b边境,在b境内的对称点。disn(a,a)表示区域a内的点距离点a第n远的点到点a的距离。设internal(a,a),表示a第n远的点和总数的关系,即:
36、
37、设adaptation(a,a,b)表示区域a中的点和区域b的适配程度,则:
38、
39、若adaptation(a,a,b)越小,即表示与b的适配度程度越低,此时不用进行任何操作,若adaptation(a,a,b)越大,即表示与b的适配程度越高,此时需生成一个完全一致的点,将该点划分给第b簇,以此类推。这样即可实现将某节点划分给不同簇的功能,成功处理区域“边境点”问题。
40、(3)节点社区契合度和节点流通度计算方法。
41、定义1节点的社区契合度,为最近七天内,该特定时间段内该节点处于该社区的平均时间与该时间段总时间的比值,表示了该节点在某段时间内与某社区的契合程度,该值为一大于等于0小于等于1的百分数。其值越接近于1,则说明这段时间与该社区契合程度越高,这就意味着这段时间内该车辆节点与该区域内其他节点通信的概率越高,并且通信质量也越高。设某车辆为a,社区为a。
42、定义residencei(a,a)表示最近7天第i天该车辆节点处于该社区的时间长度;
43、定义effectivecounts表示最近7天中,记录到该车辆的gps信号的天数;
44、则其7天内在该社区的平均时间为:
45、
46、所以,其某段时间的社区契合度可表示为:
47、
48、一般情况下,以半个小时为分割,所以对于a车辆a社区来将,每日将有48个社区契合度,每日凌晨零点重新计算社区契合度,所以,车辆节点a的a社区契合度可表示为:
49、fitness(a,a)={fitnessi(a,a)|1≤i≤48} (10)
50、定义2节点的社区流通度,为最近七天内,某特定时间段内,该节点在两个特定区域间交流的次数,与这段时间内与其他区域交流的总次数的比值,表示了该节点在某段时间内与某两个社区的交流流通程度。该值越大,表示流通越频繁,这就意味着该段时间内,此车辆在两社区间发生交流的可能越大。设某车辆为a,起始社区为a,目的社区为b。
51、定义counti(a,a,b)表示最近7天内,第i天该车辆节点在特定时间段内由a到b的次数;
52、定义allcounti(a,a)表示最近7天内,第i天该车辆节点在特点时间段内以a为起点,到达其他社区的次数;
53、则,此段时间,车辆a从a社区到b社区的流通度为:
54、
55、社区流通度同样以半小时作为分隔,也就是说一天内有48个社区流通度,所以,车辆节点a的a社区到b社区的社区流通度为:
56、circulation(a,a,b)={circulationi(a,a,b)|1≤i≤48} (8)
57、(4)基于softmax逻辑回归模型的“信使节点”计算及机会路由实现方法
58、softmax逻辑回归模型本质上是logistic逻辑回归模型在多分类问题上的推广,即多元逻辑回归。逻辑回归主要用于解决二分类问题,对目标进行0/1判断,即仅判断是或不是,其主要利用了sigmoid函数:
59、
60、普通的逻辑回归仅仅只能处理二分类问题,如果要处理多分类问题,则需要使用softmax。softmax可以把输入映射为介于0到1之间的实数,并且保证其归一化和为1。简单来说,其可以将一个n维向量映射为一个n维的概率分布,其公式如下:
61、
62、在车辆机会网络中,同一社区内,两辆车进入彼此的通信范围,意味着可以进行通信,进行数据交流。由于社区划分精确度较高,所以处于同一社区的车辆基本都处于彼此的通信范围内,即使超出了通信范围,可以进行泛洪,这样即可快速到达社区内的目标车辆节点。通过k-means进行划分后,如果与目的节点位于同一社区,则直接通信即可,若位于其他社区,则需要一个“信使节点”来进行信息传递,通过“信使节点”实现信息的跨社区传播。但是并不是所有位于该区域的节点都可以视为信使节点,需要使用一些指标来进行判断。
63、一般情况下,使用以下指标来判断节点的“信使”能力:
64、中心度:表示节点的重要程度,该值越高,说明该节点在关系网中的位置越靠近中心,意味着该节点与其他节点的交流越多。在本课题中,该值可以用最近7天内该节点与其他节点的交流次数表示;
65、可靠度:表示节点的可靠程度,该值越高,说明该节点的通信能力越好,选用该节点的成功概率越高。在本课题中,该值可以用最近7天内该节点成功承载传递信息任务的次数与总次数的比值来表示;
66、剩余容量:表示节点可以承担的信息数据的大小。该值越高,表示该节点目前可承受的信息量越高,由车辆的剩余存储空间决定;
67、基于以上属性,构建数据集,训练softmax逻辑回归模型:
68、表1 softmax逻辑回归模型数据集示例表
69、 编号 中心度 可靠度 剩余容量 距离上次通信时间 七天内通信成功次数 七天内通信总数据量 等级 1 78 0.9 556 236 70 1024 5 … … … … … … … … n 10 0.5 77 10005 15 100 1
70、基于流通社区的机会路由实现方法,可以分为三个阶段即社区划分阶段、softmax逻辑回归模型训练阶段、路由选择阶段。社区划分阶段,使用上文中的方法(3),将处理好的数据进行社区划分;softmax逻辑回归模型训练阶段,基于方法(6),构建数据集,训练softmax逻辑回归模型;路由选择阶段,总体使用单源最短路径dijkstra算法,但是在选择前往某区域的路径时,并不是采用基础的距离最近,而是通过一些复杂属性来判断。
71、路由选择阶段,可以分为两种情况,即社区内传播情况和社区间传播情况。
72、社区内传播,指的是源节点和目的节点都位于同一个区域内,此时仅需要在社区内进行短距离通信即可。因为之前的社区划分时,将范围精确到了300米左右,这就意味着大概率两车是可以进行直接通信的,如果不能,仅需要将消息转发给同社区内的节点,再进行判断即可。
73、社区间传播,在本发明中,沟通两个社区的边,通过“信使节点”实现,因此,选择路径,本质上是选择承担任务的信使。首先通过softmax逻辑回归模型,计算出当前在本区域中,最优“信使节点”概率最高的节点,接下来对这些节点进行二次筛选。接下来,若这些筛选出的节点没有提前报告路径,则之后将要前往的区域可以根据方法(5),计算出其流通度最高的区域,视为其目标区域,然后根据方法(4)筛选出社区契合度高的一些节点,这样可以大幅提升社区内传播成功的概率。
74、在转发过程中,两节点需要进行进一步判断,此时,需要一个新的度量,节点互信度。
75、定义3节点互信度。为最近一个月内(即三十天),在某个特定时间段,两车辆节点间平均通信间隔时间的倒数,简单来说,两节点间通信间隔越短,其互信度越高,如果没有进行通信,则互信度为0。设车辆a和车辆b:
76、定义timestarti(a,b)为第i次通信开始时间,timeendi(a,b)为第i次通信结束时间,则intervali为两次通信间隔时间,即:
77、intervali(a,b)=timeendi(a,b)-timestarti(a,b) (9)
78、则counti(a,b)为特点时间段内通信总次数,argintervali即为平均通信间隔时间
79、
80、所以,其互信度为
81、
82、同样,该时间段以半小时做分隔,意味着两车间根据所需的不同时间段,将有48个互信度可供选择,即:
83、trust(a,b)={trusti(a,b)|1≤i≤48} (12)
84、选择互信度最高的节点作为后继节点,之后重复上述操作即可完成选路。
- 还没有人留言评论。精彩留言会获得点赞!