隐私数据聚合方法与流程
本发明涉信息安全技术,尤其涉及一种隐私数据聚合方法。
背景技术:
1、随着互联网技术及传感器的发展,大量的数据被传感器收集并用于后续的分析、计算。在这样的场景中,数据聚合也得到了越来越多的关注。数据聚合可以在执行确切的计算之前事先对收集的数据进行处理,提高通信和计算的效率。但是,在数据被收集的过程中,数据提供者的隐私可能会被同时收集,这会给数据提供者带来安全隐患,数据提供者也会因此放弃参与数据聚合过程。
2、现有的隐私数据聚合技术主要包含:秘密分享、安全聚合、多方安全计算、差分隐私等方法,大部分技术方案需要依赖可信第三方,用户数据全部暴露给可信服务器,其隐私泄漏风险较大,且攻击者可以从聚合结果中推断用户信息。本地化差分隐私技术不需要依赖可信第三方,可以保护聚合结果的隐私性,但是每个用户均需要对本地数据进行扰动,会造成数据可用性低。
技术实现思路
1、有鉴于此,本发明提供一种隐私数据聚合方法,用以克服现有技术需要依赖可信第三方服务器,从而造成聚合结果存在泄漏用户隐私信息风险,且数据可用性低的问题。
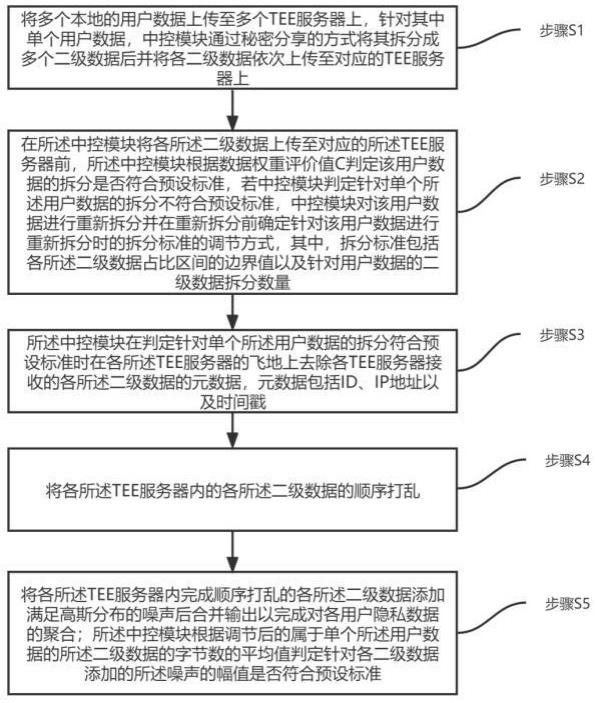
2、为实现上述目的,本发明提供一种隐私数据聚合方法,包括:
3、步骤s1,将多个本地的用户数据上传至多个tee服务器上,针对其中单个用户数据,中控模块通过秘密分享的方式将其拆分成多个二级数据后并将各二级数据依次上传至对应的tee服务器上;
4、步骤s2,在所述中控模块将各所述二级数据上传至对应的所述tee服务器前,所述中控模块根据数据权重评价值c判定该用户数据的拆分是否符合预设标准,若中控模块判定针对单个所述用户数据的拆分不符合预设标准,中控模块对该用户数据进行重新拆分并在重新拆分前确定针对该用户数据进行重新拆分时的拆分标准的调节方式,其中,拆分标准包括各所述二级数据占比区间的边界值以及针对用户数据的二级数据拆分数量;
5、步骤s3,所述中控模块在判定针对单个所述用户数据的拆分符合预设标准时在各所述tee服务器的飞地上去除各tee服务器接收的各所述二级数据的元数据,元数据包括id、ip地址以及时间戳;
6、步骤s4,将各所述tee服务器内的各所述二级数据的顺序打乱;
7、步骤s5,将各所述tee服务器内完成顺序打乱的各所述二级数据添加满足高斯分布的噪声后合并输出以完成对各用户隐私数据的聚合;所述中控模块根据调节后的属于单个所述用户数据的所述二级数据的字节数的平均值判定针对各二级数据添加的所述噪声的幅值是否符合预设标准。
8、进一步地,在所述步骤s2中,所述中控模块根据所述用户数据的字节数和该用户数据的保密等级确定该用户数据的数据权重评价值c并在判定针对单个所述用户数据的拆分不符合预设标准时根据各所述二级数据的字节数或权重评价值c与第二预设数据权重评价值的差值确定该用户数据重新拆分时的拆分标准。
9、进一步地,所述中控模块在第一权重评价值比较条件下根据所述字节数确定所述拆分标准,以及,在第二权重评价值比较条件下根据所述差值确定所述拆分标准,其中,第一权重评价值比较条件为所述数据权重评价值大于等于第一预设数据权重评价值且小于第二预设数据权重评价值,第二权重评价值比较条件为所述数据权重评价值大于等于所述第二预设数据权重评价值。
10、进一步地,所述中控模块设有在所述第二权重评价值比较条件下增加针对单个所述用户数据进行重新拆分时该用户数据的拆分数量的若干数量调节方式,其中,使用每种调节方式拆分用户数据后得到的二级数据的数量均不相同。
11、进一步地,所述中控模块在第一权重评价值比较条件下设置有针对单个二级数据的判定结果的若干处理方式,包括在第一字节数比较条件下根据拆分后的二级数据的最大字节数与最小字节数之间的差值确定针对所述单个二级数据的调节方式,在第二字节数比较条件下根据单个二级数据的字节数与第一预设字节数之间的差值减小占比区间的右边界的边界值,以及,在第三字节数比较条件下根据测得的单个二级数据的字节数与第二预设字节数之间的差值将所述单个用户数据的拆分数量增加至对应值。
12、进一步地,所述第一字节数比较条件为单个二级数据的字节数小于第一预设字节数;所述第二字节数比较条件为单个二级数据的字节数大于等于所述第一预设字节数且小于第二预设字节数;所述第三字节数比较条件为所述单个二级数据的字节数大于等于所述第二预设字节数。
13、进一步地,所述中控模块设有在所述第二字节数比较条件下减小所述占比区间的右边界的边界值的若干边界值调节方式,其中,每种调节方式对减小边界值的调节大小不同。
14、进一步地,所述中控模块在所述第一字节数比较条件下针对单个二级数据的调节方式为在所述拆分后的二级数据的最大字节数与最小字节数之间的差值小于预设均匀性差值条件下将所述占比区间的左边界的边界值增大至对应值,或,在所述拆分后的二级数据的最大字节数与最小字节数之间的差值大于等于所述预设均匀性差值条件下将所述最大字节数的二级数据减小至对应值。
15、进一步地,所述中控模块在所述调节后的二级数据的数量大于所述tee服务器数量时判定将超出服务器数量的二级数据全部上传至单个tee服务器中,或,将超出服务器数量的二级数据按顺序上传至tee服务器中。
16、进一步地,所述中控模块设有若干针对判定所述步骤s5中所述噪声幅值不符合预设标准时增大所述噪声幅值的幅值调节方式,其中,每种调节方式对增大噪声幅值的调节大小不同。
17、与现有技术相比,本发明的有益效果在于,本发明通过将用户的本地数据通过秘密分享的方式上传至tee服务器上,因此不需要可信服务器,同时,在所述tee服务器的飞地上去除所述二级数据的元数据并将所述tee服务器内的二级数据的顺序打乱,数据打乱之后,无法将数据对齐,即使各服务器合谋也不能推断用户的隐私数据,再经过添加符合满足高斯分布的噪声后聚合输出,因此攻击者无法从聚合后的输出数据推断有用信息,同时保证了数据的可用性。中控模块根据拆分后的单个二级数据的字节数确定针对单个二级数据的判定方式,或,根据求得的数据权重评价值与第二预设数据权重评价值之间的差值确定所述单个用户数据的拆分数量的调节方式,以克服现有技术中依赖可信第三方服务器,从而造成聚合结果存在泄漏风险,且数据可用性低的问题。
18、进一步地,中控模块设定所述单个用户的数据的数据权重评价值,从而精准的确定针对单个用户数据的拆分的判定方式,当拆分方式不符合预设标准时通过控制检测模块检所述拆分后的单个二级数据的字节数,中控模块根据测得的字节数确定针对所述单个二级数据的判定方式,或,将所述单个用户数据的拆分数量增加至对应值,从而增强了数据的隐私性。
19、进一步地,当用户数据的保密等级和数据量越大时候,中控模块将单个用户数据的拆分数量增加,从而增加数据的离散程度,使数据在顺序打乱后,增加了数据对齐的难度。
20、进一步地,拆分数据后的单个二级数据的字节数在不满足预设标准时,通过单个二级数据的字节数与第一预设字节数之间的差值减小所述占比区间的右边界的边界值至对应值或增加单个用户数据的拆分数量,从而解决单个单个二级数据的字节数过大的问题。
21、进一步地,为了避免随机选取占比值过大导致用户数据拆分的单个二级数据的信息过多,通过约束占比区间的右边界,降低右边界的边界值,解决了随机选取划分比例导致的单个二级数据的信息过多的问题。
22、进一步地,当中控模块判定单个二级数据的字节数符合预设标准时,进一步计算拆分后的二级数据的最大字节数与最小字节数之间的差值,从而针对性增大占比区间的左边界的边界值或将所述最大字节数的二级数据减小至对应值,并将所述最小字节数的二级数据增大至对应值,以此解决数据的均匀性问题。
23、进一步地,当调节后的二级数据的数量大于服务器的数量时,中控模块通过根据差值确定了待分配二级数据上传至tee服务器中的上传方式,从而解决了调节后数据上传的问题。
24、进一步地,当需要对用户添加噪声时,中控模块根据调节后的二级数据的字节数的平均值确定添加相应幅度的噪声信号,从而有效的提高了数据的隐私性。
25、进一步地,当二级数据字节数平均值过大时,通过增大添加的噪声的幅值,从而提高数据的隐私性。
26、进一步地,本发明还将用户的数据划定了保密等级并将其数字化,引入到数据权重评价值之中,对用户数据进行科学的划分,从而有效的进行数据划分、上传、添加噪声并聚合,最终克服了现有技术需要依赖可信第三方服务器,从而造成聚合结果存在泄漏用户隐私信息风险且数据可用性低的问题。
- 还没有人留言评论。精彩留言会获得点赞!