一种光伏组串装配车间内的网络目标定位方法与流程
本发明涉及一种光伏组串装配车间内的网络目标定位方法,属于工厂车间监测领域,具体涉及一种光伏组串装配车间内三维无线传感器网络目标定位方法。
背景技术:
1、随着光伏电站快速建设的需求,面向有序生产和安全管理的需要,工作人员、机器人或智能小车在车间内位置的准确性至关重要,需要采用机器人、物联网、智能制造技术来加速光伏组串的装配效率,因此形成了光伏组串自动化装配车间,为了提高工作效率,光伏组串装配车间实行了智能化管理模式,车间内只需要少量工作人员,采用机器人、智能小车等工具给车间内的生产线送料。
2、传统的定位方式通常是在目标上装配gps定位系统,然而在车间这类室内环境,由于gps信号弱,所以定位精度很低,不能满足实际需求。目前,随着物联网底层技术,即无线传感器网络技术的发展,为光伏组串装配车间内的目标定位技术提供了新的解决方案,将无线传感器网络通过将廉价的节点部署到光伏组串车间内,通过无线传感器节点之间的协同作用形成一个自组织的网络并覆盖整个车间,利用这些节点形成的网络可以定位车间内的任意目标,这些需要定位的目标只需要配置一个传感器节点就可被定位,这样既节约了成本,又提高了目标的定位精度。但由于车间内电磁干扰,且存在生产线、机器等障碍物,导致无线传感器节点与目标之间的距离与真实距离之间存在一定的误差,目标在车间内的定位问题是一个非线性优化问题,传统的数学求解方法不能精确的求解出目标的位置。
3、因此如何设计一种光伏组串装配车间内三维无线传感器网络目标定位算法以提高目标的位置精度是需要解决的一个问题。
技术实现思路
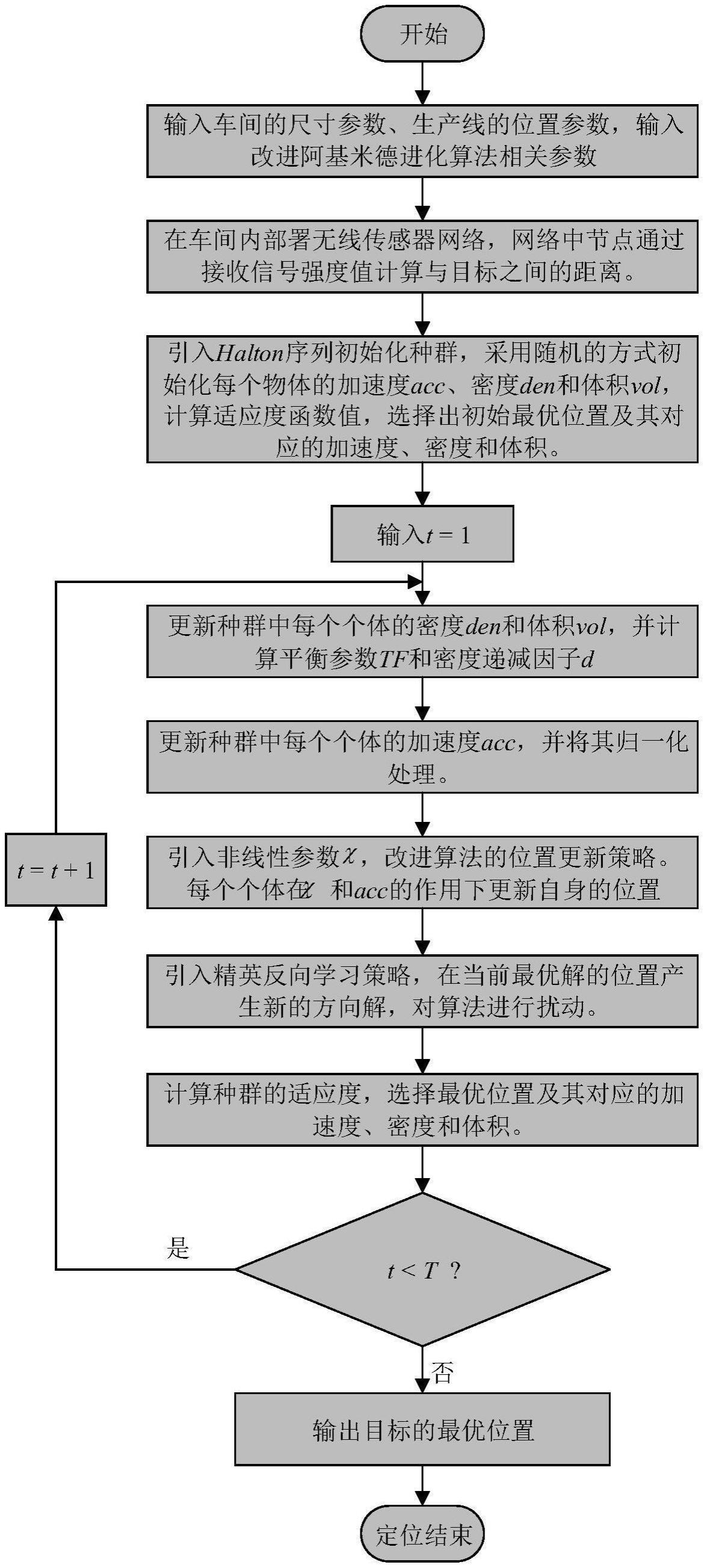
1、为解决上述技术问题,本发明提供了一种光伏组串装配车间内的网络目标定位方法,该光伏组串装配车间内的网络目标定位方法针对光伏组串装配车间内的目标定位存在非线性优化的问题,采用改进阿基米德优化算法,以光伏组串装配车间待定位目标的定位精度作为优化目标来解决上述问题。
2、本发明通过以下技术方案得以实现。
3、本发明提供的一种光伏组串装配车间内的网络目标定位方法,包括以下步骤:
4、①输入车间的尺寸参数、生产线的位置参数和改进阿基米德优化算法的参数;
5、②在车间内部署无线传感器网络,构建三维无线传感器网络定位模型;
6、③在原始阿基米德优化算法中引入halton序列初始化种群,采用随机的方式初始化种群的加速度acci、密度deni和体积voli,计算适应度值,选择最优个体及其对应的加速度accbest、密度denbest和体积volbest;
7、④输入迭代次数t=1;
8、⑤根据最优个体的密度denbest和体积volbest更新种群中每个个体的密度和体积并计算平衡参数tf和密度递减因子d;
9、⑥根据tf的值更新种群中每个个体的加速度并将其归一化处理;
10、⑦在原始阿基米德优化算法中引入非线性参数χ,改进原始阿基米德优化算法的位置更新公式;
11、⑧在原始阿基米德优化算法中引入精英反向学习策略,在当前最优解的位置产生新的方向解,对原始阿基米德优化算法进行扰动;
12、⑨计算种群的适应度值,选择当前的最优位置xbest及其对应的加速度accbest、密度denbest和体积volbest;
13、⑩判断t是否满足终止条件,如满足,则t=t+1,并返回⑤,若不满足,则输出目标的最优位置。
14、所述步骤②中,车间内的无线传感器网络覆盖整个车间的三维空间。
15、所述步骤⑦中,每个个体i在其对应的归一化加速度和非线性参数χ的作用下更新自身的位置。
16、所述步骤⑩中,终止条件为:t<最大迭代次数。
17、所述步骤③具体分为以下步骤:
18、(3.1)利用halton序列生成一个初始种群的位置:
19、x=lb+halton(n,d,p)·(ub-lb)
20、式中,x表示种群的初始位置;n和d分别表示种群的数量和搜索空间的维数;p表示halton的基数,为大于1的质数;ub和lb分别表示搜索空间的上限和下限;
21、(3.2)选取两个质数作为基数,通过不断切分基数,获得一组均匀分布且不重复的数据,其切分公式如下:
22、
23、x(a)=b0·p-1+b1·p-2+…+bm·p-m-1
24、h(a)=[x1(a),x2(a)]
25、式中,a表示[1,n]之间的任意整数,n表示点的个数;b为[0,p-1]之间的常数,p表示halton的基数;x(a)为序列函数,h(a)为最终得到的halton序列;
26、(3.3)采用随机的方式初始化种群的加速度acci、密度deni和体积voli:
27、acci=lbi+rand×(ubi-lbi);i=1,2,...,n
28、deni=rand(n,d);
29、voli=rand(n,d);
30、(3.4)构建适应度函数:
31、
32、式中,fitnessi表示第i个个体的适应度函数值;(xi,yi,zi)表示第i个个体的位置;na表示参与定位的信标节点数量;(xk,yk,zk)表示第k个信标节点的位置;dk表示目标与信标节点k之间的估计距离,根据适应度函数依次计算每个个体的适应度函数值,选出当前最优位置及其对应的加速度accbest、密度denbest和体积volbest。
33、所述步骤⑤具体分为以下步骤:
34、(5.1)根据最优个体的密度denbest和体积volbest更新种群中每个个体的密度和体积公式为:
35、
36、
37、式中,分别表示第i个个体的密度和体积,denbest、volbest分别表示算法当前最优个体的密度和体积;rand是一个维数服从标准均匀分布(0,1)的随机矩阵;
38、(5.2)计算参数tf和密度递减因子d,公式为:
39、
40、
41、式中,t表示最大迭代次数,t表示当前迭代次数,tf随着迭代次数的增加而变大,直到tf=1;d随着迭代次数t的增加而减少,将搜索转到已经识别的有界区域内。
42、所述步骤⑥中,更新种群中每个个体的加速度的公式为:
43、
44、
45、式中,mr表示[0,n]之间的随机个体;u和l分别是常数0.9和0.1;表示第i个个体的归一化加速度,如果对象i远离最优位置,则的值最大。
46、所述步骤⑦中,位置更新公式为:
47、χ=0.25×sin((t/t-0.5)×π)+0.75
48、
49、
50、式中,t表示最大迭代次数,t表示当前迭代次数,rand是一个维数服从标准均匀分布(0,1)的随机矩阵;c1和c3均是一个等于2的常数,c2是一个等于6的常数;tf为平衡参数,tk为控制当前最优位置对位置更新的影响的参数,tk=tf,tk随着迭代次数的增加而增加;f是一个改变运动方向的参数,xrand表示任意个体的位置,表示第t次迭代时第i个个体的位置,表示第t次迭代时的最优位置;p为控制参数,调节个体的运动方向,d表示密度递减因子。
51、所述步骤⑧中,方向解的公式如下:
52、
53、
54、b1=0.4*sin(((t-t)/t-0.5)*π)+0.5
55、式中,表示在当前最优解处利用精英反向学习策略产生的方向解,表示扰动后的种群最优解;rand是一个维数服从标准均匀分布(0,1)的随机矩阵,上下边界分别用ub和lb表示,b1表示信息交换控制参数;t表示最大迭代次数,t表示当前迭代次数。
56、所述步骤⑨中,种群的适应度的计算公式为:
57、
58、式中,fitnessi表示第i个个体的适应度函数值;(xi,yi,zi)表示第i个个体的位置;na表示参与定位的信标节点数量;(xk,yk,zk)表示第k个信标节点的位置;dk表示目标与信标节点k之间的估计距离。
59、本发明的有益效果在于:对阿基米德优化算法引入了halton序列,使初始化种群更加均匀,有利于算法的寻优;引入了非线性参数改进算法的位置更新公式,提升了算法的收敛速度与寻优精度;引入了精英反向学习策略,在算法当前最优解解的位置产生对反向解,对算法进行扰动,提升算法跳出局部最优值的能力。
- 还没有人留言评论。精彩留言会获得点赞!