一种结合工作量证明和权益证明的高效Raft领导者选举方法与流程
本发明涉及分布式一致性领域,特别是涉及一种结合工作量证明和权益证明的高效raft领导者选举方法。
背景技术:
1、raft一致性算法在设计之初便以易于实现、原理清晰等特点作为设计原则,短短几年时间便已被广泛应用于各类分布式环境中。同时,作为paxos协议的简化版本,raft算法牺牲了部分性能,对于不同场景中的实际应用,可根据场景特殊性对该算法作出某些方面的具体改进。当分布式系统中的领导者节点因故障无法处理集群服务时,需要进行领导者节点的重新选举,以恢复系统运作。在raft共识算法中,一些节点由于网络故障而无法与其他节点通信,这将大大增加共识时间,此外,raft算法中的领导者节点具有很强的领导能力,一旦领导者节点出现问题,整个分布式系统的共识时间将大大增加。
2、综上所述,现有raft算法领导者选举存在如下缺点:
3、1、raft共识算法随着系统服务器节点的数量增加,在选举领导者的过程中,能够投票参与选举的候选者节点数量也会相应增加,将导致领导者节点的选举速度下降。
4、2、在选举之前,如果跟随者节点由于网络原因无法与其他节点进行通信,就会出现隔离现象,但是这些节点还可以继续触发超时选举,导致term值不断增加,移除隔离后,节点可以继续参与选举,但由于该节点不与其他节点通信,导致日志队列太老,term值大于集群内其他节点,如果这些过时的节点赢得选举,整个系统的共识时间将会增加;
5、3、raft采用强领导者机制来保证数据的一致性,即领导者节点承担的任务比跟随者多得多,不仅承担了系统内全部的日志复制工作,同时还需要周期性的向跟随者节点发送心跳来维持领导者地位,因此领导者节点的性能和网络通信情况是影响系统整体性能的关键部分,一旦领导者节点在一段时间内位于一个慢速节点上,整个系统的性能就会变慢。
6、4、领导者节点如果由于故障导致宕机或者网络通信失败,系统将触发心跳检测重新进行选举,由于raft算法使用的随机超时机制,会出现多个节点同时超时成为候选节点的情况,在极端情况下,由于投票的瓜分,一次选举可能无法成功选出领导者节点,因此系统会经历多次超时选举,这将浪费大量时间。
7、上述现有技术存在的缺点会影响raft一致性算法的共识效率和容错能力。所以本发明提出了一种结合工作量证明和权益证明的高效raft领导者选举方法。
技术实现思路
1、本发明的目的在于解决现有技术存在的缺点会影响raft一致性算法的共识效率和容错能力的问题。
2、一种结合工作量证明和权益证明的高效raft领导者选举方法,包括:
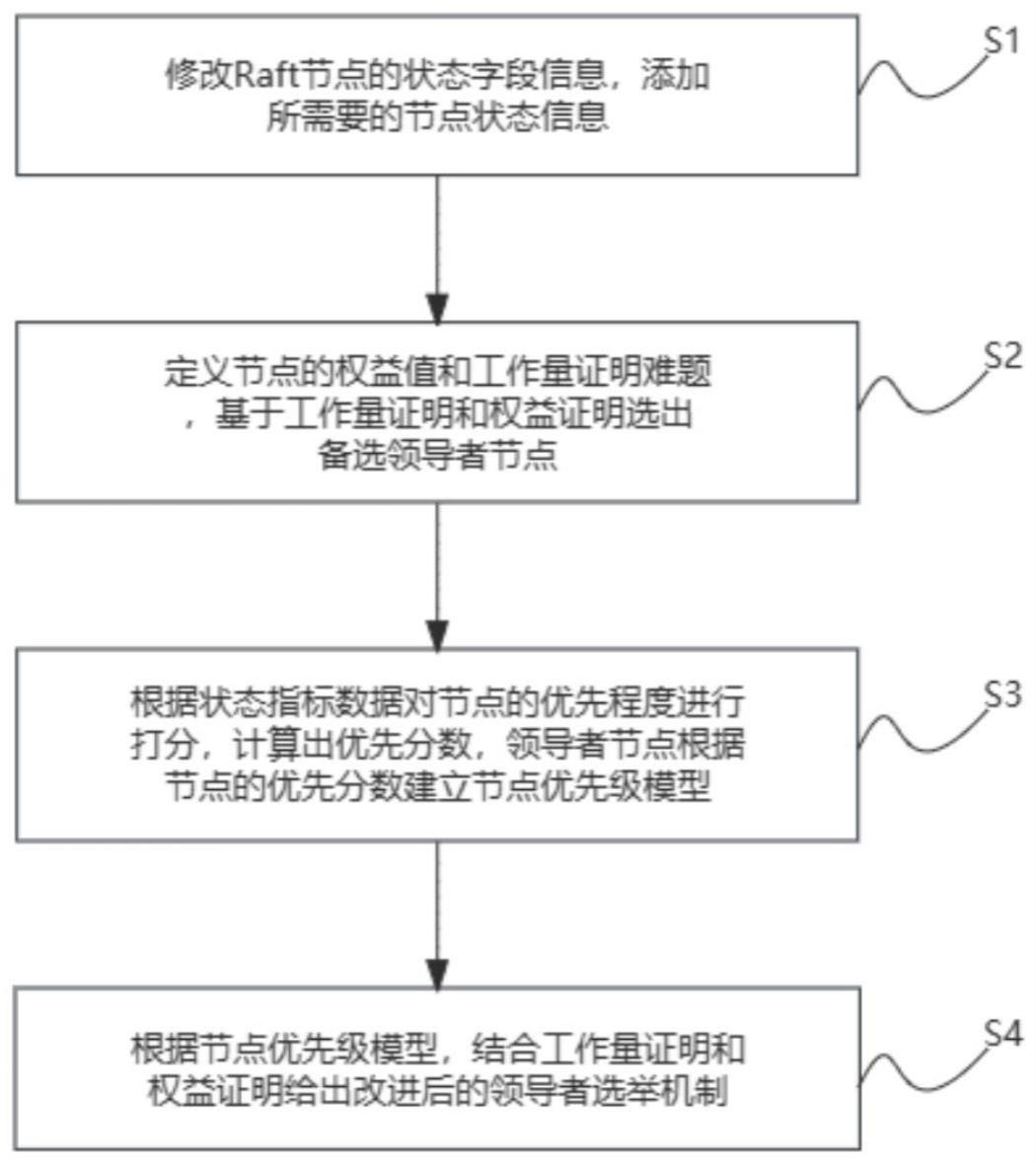
3、步骤s1:添加所需要的raft节点状态信息,raft节点简称节点,修改appendentries请求报文以及响应报文;
4、步骤s2:定义节点的权益证明和工作量证明难题,求解工作量证明难题得到工作量证明,领导者节点基于工作量证明和权益证明从节点中选出备选领导者节点;
5、步骤s3:根据状态指标数据对节点的优先程度进行打分,得到节点的优先分数,领导者节点根据节点的优先分数建立节点优先级模型;(状态指标数据由节点自己更新当前的内存使用率、网络带宽使用率,写入业务请求次数,以及接收到的心跳报文中报文发送时间这些信息,通过公式计算得到。)
6、步骤s4:根据节点优先级模型,结合工作量证明和权益证明给出改进后的领导者选举机制。
7、上述技术方案中,步骤s1中,添加的节点状态信息包括以下步骤:
8、s11:节点的状态信息用来衡量其作为领导者节点的优先程度,综合节点的性能、当前的工作情况、网络通信情况因素,状态信息包括:节点的剩余计算资源、节点的网络通信情况、节点收到写入业务请求次数、节点优先值;
9、s12:在向跟随者节点发送append entries rpc请求报文的同时,在涉及到状态信息的地方,跟随者节点首先更新自身的状态信息计算节点优先值,并将结果返回给领导者节点,领导者节点在收到日志已提交消息后,开始更新自己的状态信息并计算优先值,最后得到节点优先分数;
10、s13:在append entries rpc请求报文和append entries rpc响应报文中添加相关的节点状态信息,并在报文处理算法中添加与添加的节点状态信息对应的策略对其进行决策,具体实现如下:(对应的就是报文的接收接方,例如接收心跳请求报文的就是跟随者节点,接收心跳响应报文的就是领导者节点;这些决策再s4里面有提到)。
11、s131:修改append entries rpc请求报文,添加报文发出的时间戳,用于测算跟随者节点与领导者节点间的心跳报文时延,添加网络通信情况nnetwork,用于领导者节点的优先值计算。
12、s132:修改append entries rpc响应报文,添加节点优先值字段;
13、s133:跟随者节点在收到来自领导者的append entries rpc请求报文后,更新计算自身状态信息,根据状态信息计算优先值nvalue;
14、s134:领导者节点收到跟随者节点的append entries rpc响应报文后,记录节点的优先值。
15、上述技术方案中,s2中,基于工作量证明和权益证明从节点中选出备选领导者节点包括以下步骤:
16、s21:定义节点的权益值logvalue,节点的权益值越大成为备选领导者节点的难度就越低,在相同的计算能力下,成为备选领导者节点的概率就越高,权益值logvalue的计算公式如(1)所示:
17、logvalue=logterm*10k+logindex (1)
18、其中logterm是节点最后一条日志条目的任期号,longindex是节点最后一条日志条目的索引值,k代表了不同的logterm相差的数量级,k的计算公式如(2)所示:
19、k=m-leaderterm+logterm (2)
20、其中leaderterm表示此时的领导者任期号,m表示所有节点的最后一条日志条目任期号之间的最大差值,即最大任期号减去最小任期号;
21、s22:定义工作量证明难题,工作量证明难题是用于实现可验证的计算任务,求解工作量证明难题包括证明者和验证者两个角色,证明者向验证者提供工作量证明,工作量证明用于证明所述的证明者在一段时间内完成了规定数量的计算任务,计算任务的数量的大小取决于节点的权益值以及预设的目标值,每个节点完成解题成为备选领导者节点的概率可以由其计算资源决定;
22、s221:节点通过不断地尝试将随机数值nonce进行哈希计算,来寻找满足条件的随机数值nonce,使得节点计算的哈希值nodehash小于预设的目标值target,同时结合权益证明进行改进,将所有节点统一的目标值乘以节点的权益值,使得各个节点的哈希难度不同,改进后的工作量证明难题的表达式如(3)所示:
23、nodehash=hash(nonce)<target*logvalue (3)
24、其中hash表示哈希计算,哈希值前n位为零,n的大小等于难度值的大小,不同的节点所计算的难度不同,权益值越大计算难度就越低;
25、s222:将领导者节点作为验证者,跟随者节点作为证明者,领导者节点在成功选举并开始工作后,不断地广播工作量证明难题,包括开始解题消息以及所有节点统一的目标值target,跟随者节点在收到工作量证明难题后进行解题,在完成解题后回复领导者节点,返回随机数值nonce;
26、s23:当领导者节点收到跟随者节点的解题完成回复后,进行验证,如果满足表达式(3)并且备选领导者节点为空,那么将通过验证的节点设置为备选领导者节点,并且告知所有的跟随者节点备选领导者的节点的身份,跟随者节点停止解题。
27、上述技术方案中,s3中,建立节点优先级模型的详细描述如下。
28、s31:更新节点的剩余内存大小rn,计算节点的剩余计算资源ncalculate;
29、s311:计算第n个节点的剩余内存在总内存sn中的百分比zn,其公式如(4)所示:
30、
31、s312:计算每个节点的剩余计算资源ncaculate,其计算公式如(5)所示:
32、
33、s32:更新网络带宽占用率pn,计算节点的网络通信情况指标nnetwork;
34、s321:计算跟随者节点与领导者节点间第i次心跳报文时延di,计算公式如(6)所示:
35、di=fi-li (6)
36、其中li是领导者节点第i次的发送时间,fi是跟随者节点收到的时间;
37、s322:计算心跳报文时延变化vn,计算公式如(7)所示:
38、vn=|dlast-dnew| (7)
39、其中dlast是前一次的心跳报文时延,dnew是这一次的心跳报文时延。
40、s323:计算每个节点的网络通信情况指标nnetwork,计算公式如(8)所示:
41、
42、其中bn是节点的带宽;
43、s33:更新节点收到的写入业务请求次数nrwtimes,根据上述状态数据指标计算节点优先值nvalue,计算公式如(9)所示:
44、nvalue=α*ncalculate+β*nnetwork+γ*nrwtimes (9)
45、其中α,β,y系数表示对不同的节点性能指标的比例系数,可根据实际情况调整不同指标的比例系数,其中α+β+γ=1。
46、s34:领导者节点在收到来自跟随者的append entries rpc响应报文后,记录节点的优先值,建立节点优先级模型;
47、s341:领导者节点收到客户端发来的写入业务后,将指令追加到自己的本地日志中,此时日志为未提交状态,然后领导者向所有跟随者节点发送append entries rpc请求报文,等待半数成功消息,本地日志将变为提交状态;
48、s342:一条日志变为已提交状态后,表示超过半数的跟随者节点的优先值更新完毕,此时领导者更新自己的优先值,领导者的网络通信情况nnetwork计算公式如(10)所示:
49、
50、其中ninetwork表示第i个跟随者节点的网络通信情况,m为跟随者节点数;
51、s343:将第i个节点的优先值换算为对应的优先分数niscore,计算公式如(11)所示:
52、niscore=nivalue/nmaxvalue*100 (11)
53、s344:节点按照优先分数划分为四个优先级,建立起节点优先级模型。
54、上述技术方案中,s4中,改进后的raft领导者选举机制的详细描述如下。
55、s41:领导者节点为空并且备选领导者节点也为空,开始raft领导者选举流程,获得多数选票的节点成为领导者,如果领导者节点为空但是备选领导者节点不为空,备选领导者节点直接成为领导者;
56、s42:选出领导者节点后,领导者节点开始向所有跟随者节点发送append entriesrpc请求报文,作为心跳消息,维护自己的领导者地位,同时向跟随者节点追加日志;
57、s43:备选领导者为空,领导者节点开始选取备选领导者节点;
58、s431:领导者节点广播结合权益证明改进后的工作量证明难题nodehash;
59、s432:收到工作量证明难题的跟随者节点开始解题,在解题成功后向领导者节点返回解题成功消息;
60、s433:领导者节点收到回复消息进行验证,如果回复消息通过验证,领导者节点广播告知所有跟随者节点备选领导者身份并告知停止解题;
61、s44:跟随者节点在收到来自领导者的心跳消息后,更新计算自身状态信息,根据状态信息计算优先值nvalue;
62、s441:跟随者节点收到心跳报文,判断报文是否包含日志条目,如果包括则复制日志信息,继续下一步,否则将超时选举计时器重置为0,继续等待心跳报文;
63、s442:跟随者节点复制日志信息;
64、s443:按照s2计算优先值,并将选举超时定时器重置为0,返回append entriesrpc响应报文;
65、s45:领导者节点收到跟随者节点的append entries rpc响应报文后,记录节点的优先值;
66、s46:当一条日志的状态变为已提交后,领导者计算优先分数,建立节点优先级模型,并进行主动让位判断,如果存在比领导者节点优先级更高的节点,主动让位给优先级更高的节点,将节点优先级模型交给新的领导者维护;
67、s47:当领导者节点出现故障导致宕机或者网络通信失败,跟随者节点在选举超时时间内未收到领导者节点的心跳消息,开始新一轮领导者选举;
68、s471:如果备选领导者节点不为空,则备选领导者节点直接成为领导者,
69、开始执行步骤s42;
70、s472:否则开始执行步骤s41,如果在一轮任期内成功选出领导者,则结束当前领导者选举;
71、s473:当集群中存在两个及以上候选者节点,造成投票出现瓜分的局面时,比较两节点优先级,优先级高的当选。
72、综上所述,由于采用了上述技术方案,本发明的有益效果是:
73、1.本发明定义了新的“备选领导者”状态,通过提前解题的方式选出,当领导者出现故障时,直接成为新任期的领导者,解决了随着系统节点数目增加,能够参与选举的候选者节点数目增加,导致选举时间过长的问题。
74、2.本发明创新性的定义了节点的权益值和工作量证明难题,将工作量证明与权益证明相结合,综合考虑了节点的计算能力和节点的日志更新程度,大大降低了过时节点赢得选举概率,减少了整个系统的共识时间。同时工作量证明机制保证了节点的计算能力由解题的速度决定,一定程度防止了节点恶意行为。
75、3.本发明创新性的提出了一种打分策略,该打分策略可以综合考虑节点一段时间内的性能、剩余计算资源,网络通信情况,评估出更适合成为领导者的节点,通过主动让位尽可能让领导者位于快速的节点上,保持整个系统的性能稳定。
76、4.本发明考虑了选举过程中可能出现的选票瓜分,系统多次重选领导者的解决方案,基于节点优先级模型,实现在最多一次超时选举中选出领导者节点。
- 还没有人留言评论。精彩留言会获得点赞!