一种规则匹配与预训练语言模型相结合的威胁知识抽取方法和系统
本发明涉及一种规则匹配与预训练语言模型相结合的威胁知识抽取方法和系统,属于计算机、网络安全、智能知识抽取领域。
背景技术:
1、随着网络信息技术的飞速发展,网络空间规模与复杂性与日俱增,网络攻击技术不断发展变化,各种类型的网络安全事件规模层出不穷,网络安全面临严峻的威胁与挑战。手动或自动生产威胁情报进行威胁知识抽取,并在第一时间用于威胁攻击的监测、分析与预警,可在攻击的早期阶段有效干扰或阻断网络威胁、网络攻击等行为。由于网络安全事件与威胁信息数量巨大,相关情报信息数量远超人力可解析的数量级,且其中相当大部分威胁情报为自然语言文本,自动化、智能化的威胁情报知识抽取技术成为研究领域的焦点。
2、传统的自动化威胁攻击知识抽取多基于规则匹配方法、传统自然语言处理与信息检索技术。其中,规则匹配技术往往由网络安全专家根据自身经验,基于正则表达式等字符串匹配方式编写形成提取规则;该类方法可以直接利用专家经验知识,但也受限于专家经验知识,无法提取专家经验不能覆盖的知识;此外,对于较深层次的、较隐晦的威胁知识,难以使用规则进行准确描述。传统自然语言处理技术通过tf-idf等技术对文本进行向量化,通过统计机器学习技术进行主题抽取、聚类等,通过信息论相关理论进行关键词抽取等,该类方法具备一定的学习性,随数据量增长效果可逐步得到提升。
3、随着深度学习技术在通用人工智能领域的广泛应用,预训练模型在多领域大展身手,在大规模算力基础设施支持下,应用效能得到大幅度提升,在经验、知识驱动的网络安全领域,其应用前景非常可观。大规模预训练语言模型出现后,由于其充分捕捉了自然语言的深层次模式,在多类自然语言处理任务应用中的成效显著,包括命名实体识别、词性标注、关系抽取等,实践显示,大规模预训练语言模型仅需搭配简单的下游神经网络,即可直接应对多种任务。考虑大规模语言模型训练基于广谱语料,不针对专精领域语料,缺乏对特定领域的深入知识,本发明将规则匹配模型与预训练语言模型相结合,应用于网络安全威胁知识抽取,提出了一种规则匹配与预训练语言模型相结合的威胁知识抽取方法。
技术实现思路
1、为从自然语言型威胁情报中抽取出网络安全领域相关实体,本发明提出了一种规则匹配与预训练语言模型相结合的威胁知识抽取方法和系统。
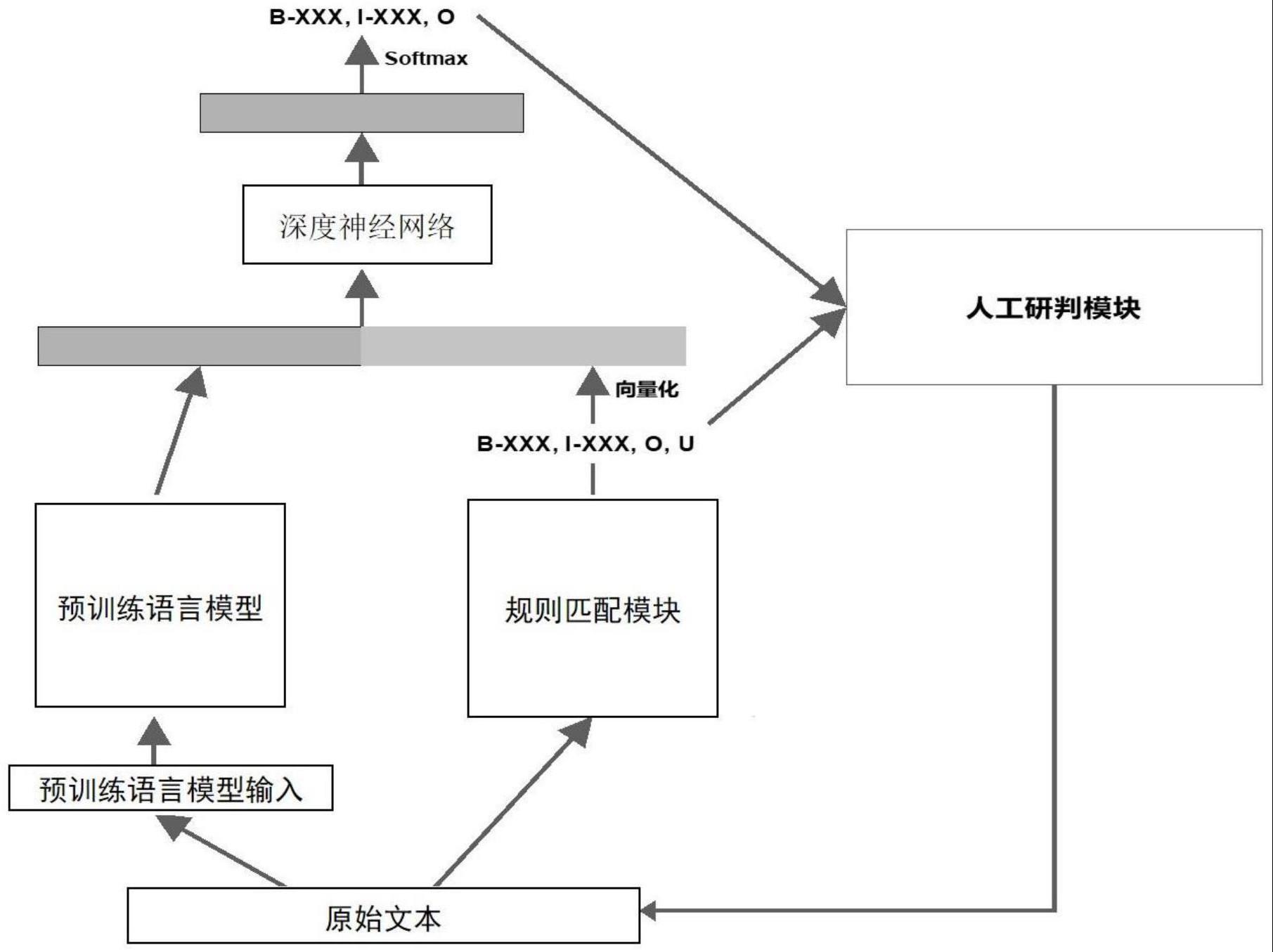
2、本发明的一种规则匹配与预训练语言模型相结合的威胁知识抽取方法,包括以下步骤:
3、确定需要抽取的网络安全实体类型;
4、编制规则匹配过程所需的规则;
5、将非结构化威胁情报文本经过规则匹配过程,得到初步实体标注结果,并将其向量化;
6、将非结构化威胁情报文本输入预训练语言模型,获得文本的向量化表示,
7、将规则匹配过程获取的标注向量与预训练语言模型获得的向量化表示进行拼接后,输入下游深度神经网络,获得最终实体标注结果。
8、进一步地,所述确定需要抽取的网络安全实体类型,是由网络安全领域专家根据领域知识确定所有的实体类型,根据b-i-o或b-i-o-e-s规则设计所有实体类型的标记;在b-i-o或b-i-o-e-s标记基础上添加新的标记类型u,表示unknown,即暂时不知道被标记的英文词或中文字属于或不属于实体;在所述规则匹配过程中未命中任何规则的区域均为u标记;u标记只存在于规则匹配的结果中,下游深度神经网络的输出中不存在u标记。
9、进一步地,所述编制规则匹配过程所需的规则,是基于网络安全领域专家知识,通过字符串匹配、正则表达式、依存句法树形式设计的实体抽取规则。
10、进一步地,所述预训练语言模型为bert模型或基于bert的衍生模型。
11、进一步地,所述下游深度神经网络的训练过程包括:
12、获取经过网络安全专家人工标注的数据集作为训练集,训练集通过预训练语言模型得到文本的向量化表示;将训练集通过规则匹配过程得到初步实体标注结果,并将其向量化,得到初步实体标记向量;将文本向量化表示与初步实体标记向量进行拼接,输入下游神经网络中;将下游深度神经网络的输出与标准标注通过交叉熵损失函数计算损失,通过反向传播算法迭代更新下游深度神经网络。
13、进一步地,上述方法还包括对冲突数据进行人工研判的步骤:
14、对于一条数据,如果下游深度神经网络得到的最终标注结果与规则匹配过程得到的标注结果相冲突,则将该条数据报送至网络安全专家进行人工研判,经过研判,确定最终实体标注结果;同时,确定冲突结果原因,即规则匹配过程或下游深度神经网络模型可能有缺陷。
15、进一步地,上述方法还包括对规则匹配和下游深度神经网络进行修正的步骤:
16、经过研判后,若确定错误由规则匹配过程导致,则由网络安全领域专家进行分析后,更新修正规则;
17、若确定错误来自下游深度神经网络模型,则数据量积累至一定数量后,对下游深度神经网络进行进一步训练;并且为进一步提高文本标注结果的准确性,周期性地对下游深度神经网络进行重新训练。
18、本发明还提供一种规则匹配与预训练语言模型相结合的威胁知识抽取系统,其包括:
19、规则匹配模块,用于将非结构化威胁情报文本经过规则匹配过程,得到初步实体标注结果,并将其向量化;
20、预训练语言模型模块,用于将非结构化威胁情报文本输入预训练语言模型,获得文本的向量化表示;
21、深度神经网络模块,用于将规则匹配过程获取的标注向量与预训练语言模型获得的向量化表示进行拼接,并输入下游深度神经网络,获得最终实体标注结果;
22、人工研判模块,用于在下游深度神经网络得到的最终标注结果与规则匹配模块得到的标注结果相冲突时,进行人工研判以确定最终实体标注结果,并确定冲突产生原因;
23、修正模块,用于根据冲突产生原因,对规则匹配模块或深度神经网络模块进行修正。
24、本发明的有益效果是:
25、本发明将规则匹配模型与预训练语言模型相结合,应用于网络安全威胁知识抽取,提出了一种规则匹配与预训练语言模型相结合的威胁知识抽取方案,能够有效地从自然语言型威胁情报中抽取出网络安全领域相关实体。并且,该方案能够通过长期更新迭代,不断保持对新威胁情报实体的敏感性。
技术特征:
1.一种规则匹配与预训练语言模型相结合的威胁知识抽取方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,所述确定需要抽取的网络安全实体类型,是由网络安全领域专家根据领域知识确定所有的实体类型,根据b-i-o或b-i-o-e-s规则设计所有实体类型的标记;在b-i-o或b-i-o-e-s标记基础上添加新的标记类型u,表示unknown,即暂时不知道被标记的英文词或中文字属于或不属于实体;在所述规则匹配过程中未命中任何规则的区域均为u标记;u标记只存在于规则匹配的结果中,下游深度神经网络的输出中不存在u标记。
3.根据权利要求1所述的方法,其特征在于,所述编制规则匹配过程所需的规则,是基于网络安全领域专家知识,通过字符串匹配、正则表达式、依存句法树形式设计的实体抽取规则。
4.根据权利要求1所述的方法,其特征在于,所述初步实体标注结果的向量化过程包括:将向量分为两部分;一部分表征b-i-o或b-i-o-e-s前缀,使用预训练模型中英文词“begin”,“inside”,“outside”,或“begin”,“inside”,“outside”,“ending”,“single”“unknown”的向量化表示;另一部分表征具体的实体类型,包括:人物类,使用预训练模型中词语“people”的向量化表示;组织类,使用预训练模型中词语“organization”的向量化表示,对于o与u标记,该部分重复使用词“outside”与“unknown”;若使用的预训练模型为中文模型,使用对应词语的中文版本。
5.根据权利要求1所述的方法,其特征在于,所述预训练语言模型为bert模型或基于bert的衍生模型。
6.根据权利要求1所述的方法,其特征在于,所述下游深度神经网络的训练过程包括:
7.根据权利要求1所述的方法,其特征在于,还包括对冲突数据进行人工研判的步骤:
8.根据权利要求1所述的方法,其特征在于,还包括对规则匹配和下游深度神经网络进行修正的步骤:
9.一种规则匹配与预训练语言模型相结合的威胁知识抽取系统,其特征在于,包括:
10.一种计算机设备,其特征在于,包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行权利要求1~8中任一项所述方法的指令。
技术总结
本发明涉及一种规则匹配与预训练语言模型相结合的威胁知识抽取方法和系统。该法包括:确定需要抽取的网络安全实体类型;编制规则匹配过程所需的规则;将非结构化威胁情报文本经过规则匹配过程,得到初步实体标注结果,并将其向量化;将非结构化威胁情报文本输入预训练语言模型,获得文本的向量化表示,将规则匹配过程获取的标注向量与预训练语言模型获得的向量化表示进行拼接,并输入下游深度神经网络,获得最终实体标注结果。本发明将规则匹配模型与预训练语言模型相结合,应用于网络安全威胁知识抽取,够有效地从自然语言型威胁情报中抽取出网络安全领域相关实体。
技术研发人员:聂榕,倪彦波,连一峰,张海霞,彭媛媛,韩鹏
受保护的技术使用者:中国科学院软件研究所
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!