一种物联网边沿网关机器学习故障诊断方法
本发明涉及网关机器学习故障诊断方法,具体涉及一种物联网边沿网关机器学习故障诊断方法。
背景技术:
1、目前很多城市,正在推进基于路灯杆向城市综合杆箱体系的演化。具体而言综合杆箱包括主杆、副杆、横臂、设备综合箱及灯臂等地上结构件,以及地下综合管廊、设备井和设备基础等组成。在上述背景下,综合杆箱将承载更多的社会公共安全角色。在长期运行中,各类智能化设备长期处于道路环境下的恶劣工况中,如车辆撞击、狂风冲击、洪水浸泡设备腐蚀等病害。这些因素综合起来后,对于单一照明设备检修和维护将引发颠覆性的挑战,如必须24小时全天候供电,设备故障更加复杂以及彼此耦合影响更加显著等。
2、与精密工业设施的维护必须及时排除故障不同,道路设备没有条件及时维护轻微病害。相反,从经济和实际状态出发,还应该允许道路上众多综合杆箱带病服役运行。只要这些设备上的病害不在进一步恶化,这些对轻微故障必须长期容忍。也就是说,必须允许设备的长期带病运行。当然,当出现非常严重的异常时,比如综合杆严重倾斜时,哪怕采样超过限制只有一次,那也要引起足够重视,并形成报警迅速推送给值班人员。因为在这样的工况下,监测指标的严重超限会迅速引起相关的设备损坏和环境破坏。
3、因此,监测综合杆箱设备的传感器采样数据,不能对超过阈值的全部报警实施第一时间的维护和检修。在面对城市级众多的道路综合杆箱设备数据,需要提出一种能合理过滤带缺陷设备引发的异常采样数据,但又能及时响应真正灾害的判断方法。从而达到越严重的病害,响应越及时,有限而宝贵的维护资源能更精准的配置;而常规病害和使用中正常病害引发的报警,反而不应过于响应灵敏,从而不至于对维护人员产生决策干扰。如何在灵敏度和平缓之间取得平衡,将是本研究的重要目标和任务。
4、目前广泛使用的云平台解决方案,受限于ip延迟、流量费用、决策响应耗时等因素,很难解决上述问题。云平台模式需要多次采样复核后,再由云平台做出疑似报警决策,最后分别提交值班人员和现场硬件分别采取硬件动作。于此同时,综合杆箱分布于环境复杂的城市道路环境中,地域广泛且工况复杂,道路环境中的信号干扰、设备带缺陷的扰动、微气候环境变化等不可控因素,很难简单加快采样频率来获得对真实病害较为理想的响应速度。
5、在云平台中,时间序列{t0、t1、t2、t3、……ti、ti+1、……tm}为采样周期。当出现设备硬件异常时,也就是异常0出现的t0时刻,异常状态数据上传到云平台开始第0次采样。为了剔除偶发因素造成误判,云平台侦测到硬件异常采样参数立即下发采样指令核实参数,此时硬件开始第1次采样,再次上传数据异常1至云平台;如的确设备端发生了异常,则如此完成第n次异常复核后,云平台即可判断异常的真实性;上述流程是一个典型监测异常的复核流程,可以看出,其基本性能由(硬件内部响应+云平台与硬件之间双向通讯延迟+云平台内部决策耗时)*n所决定;显然,云平台与硬件之间的双向通讯延迟,将比硬件和云平台内部的延迟显著大很多。而且云平台与硬件之间频繁的通讯也将显著增加通讯流量的开支。
6、具体而言,目前较为常见的物联网设备云平台管理方案的基本原理有两个主要方案,一是在物联网管理云平台和物联设备之前构建一个数据传输网关间接接入云平台,二是将物联设备直接与云平台链接的两种形式;但是受市场方向引导,上面两个模式更多是服务于智能家居和集中化应用的工业物联网工况下,对基于城市照明的大面积稀疏市政物联网应用优化较少,在网络质量、流量消耗、防灾减灾、安全供电和其它智能化应用方面,缺乏足够的针对性优化,对于道路环境下复杂工况对物联设备资产状态的蜕变估计不足。
7、特别是如此巨量的物联设备,分布安装在以道路照明杆箱为核心的智慧综合杆系统中,各自资产属性蜕化千差万别;现有以公益属性为主的维护资源,不能实现对全部设备的以旧换新式的故障检修业务。而只能以有限的维护资源,以容忍大量设备带缺陷运行的代价,完成对严重故障设备的定期更换及重点节点灾害抢修任务。但是,由于云平台通讯延迟较大、物联节点工况复杂、网络流量带宽以及通讯并发等数据网络固有特点,很容易导致物联设备执行动作并行同步差、错漏严重故障、前端初审不准、报警复核量大等一系列严重阻碍应用顺利开展的矛盾。
技术实现思路
1、发明目的:为了克服现有技术中存在的不足,本发明提供一套能够以合理的带宽消耗,提供尽可能精准的故障预报的方法。
2、技术方案:本发明采用以下技术方案:
3、一种物联网边沿网关机器学习故障诊断方法,在计算机中实现以下步骤:
4、1)获取传感器传输的json格式数据流;
5、2)读取设备id列表;
6、3)初始化队列池长度n;
7、4)队列元素初始化赋值;
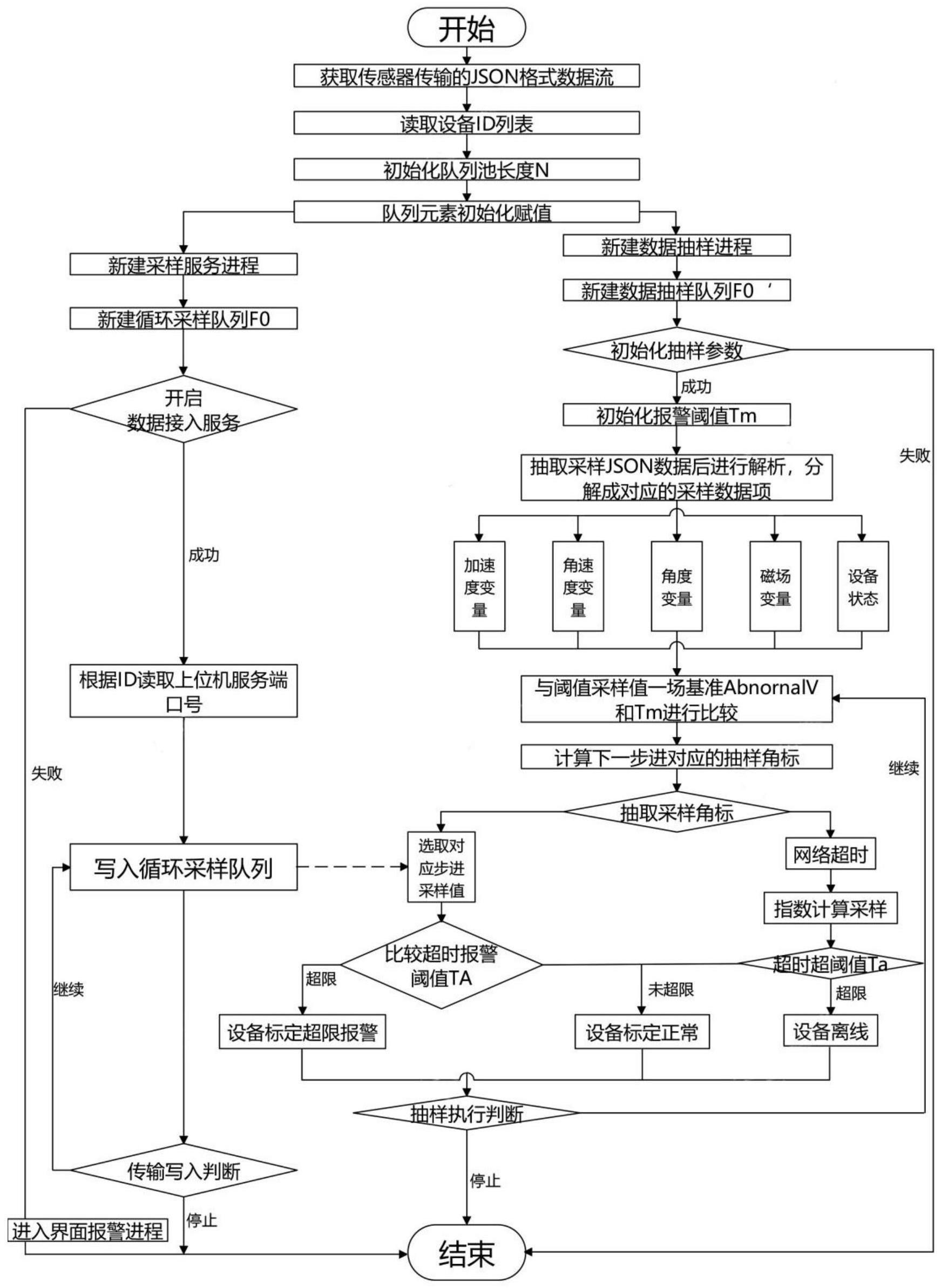
8、5)完成初始化赋值后,分别新建采样服务进程和新建数据抽样进程。
9、进一步地,所述步骤3)中,队列池的长度n取决于读取设备id列表后所需获取的传感器数量。
10、进一步地,所述步骤4)中,初始化过程包括以下步骤:
11、第一步,初始化赋值队列元素,包括设备采样上限阈值超时阈值ta,采样报警阈值tm,报警指示器初始值alarmindex,超时报警指数ta,采样间隔周期下限值basemark,采样间隔周期上限值fastmark,采样值异常基准abnormalv,采样正常数据值basev取值为采样序列中最小值,以及由业务所决定的基矩阵(其中p∈n+,n+为正整数集,取值为设备序列id的个数);
12、第二步,定义元数据,假定有1个传感器d0,全部有n个数据项,形成下式:
13、d0=[s0,s1,s2,…,si,si+1,…,sn]
14、引入时间的概念,则i=0时刻的采样数据帧f0可以记为:
15、
16、如果有多个传感器m,此时数据帧f0还可以包括[0,…,k,…,m],0≤k≤m个元素,如下式2所示:
17、
18、第三步,转置构建采样数据矩阵:
19、将上述向量转置后为和后,形成采样矩阵:
20、
21、进一步地,所述步骤5)中,采样服务进程的实现,具体包括以下步骤:
22、a)新建循环采样队列f0;
23、b)开启数据接入服务;
24、c)数据接入成功完成则进入步骤d),数据接入未完成则判定为失败,配合进入界面报警进程并显示报警;
25、d)根据id读取上位机服务端口号;
26、e)采样服务进程开启tcp/ip下的指定id号服务监听端口,对传感器传入的json数据流迅速存入对应id号的循环采样队列中,按行依次序写入,并生成采样角标记录当前写入的队列位置,为数据抽样处理进程提供定位标识;
27、f)当传输写入判断转换为停止标志时,采样服务进程停止队列写入循环。
28、进一步地,所述步骤5)中,数据抽样进程具体包括以下步骤:
29、a)新建数据抽样队列f0′;
30、b)初始化抽样参数,包括机器学习函数、抽样角标、正常采样步进和数据采样定位标识变量;
31、c)初始化抽样参数成功,则进入步骤d),否则结束进程并更新程序;
32、d)初始化报警阈值tm;
33、e)抽取采样json数据后进行解析,分解成对应的采样数据项;
34、f)与阈值采样值异常基准abnormalv和tm进行比较,计算下一步进对应的抽样角标。
35、进一步地,所述数据抽样进程中,步骤f)中,当采样值大于abnormalv或tm则alarmindex++;采样值小于abnormalv或tm则意味着未超限,则alarmindex--,直至为0,若则意味着已经累计足够多次数超过采样报警阈值tm的采样值,可以给该数据项对应的传感器定性为设备故障。
36、进一步地,所述数据抽样进程中,当出现网络超时采样数据停止,通过以下步骤计算虚拟传感器采样值,
37、将转置后的数据帧f0与基矩阵相乘,得到i=0时刻临时数值t0:
38、
39、此时计算点乘后,将t0中元素不进行求和计算,而是进行相关元素的截断,还原成为断网工况下的虚拟采样数据,并以此计算采样延时函数中:
40、
41、其中:
42、
43、元素截断操作:
44、构建一个循环,分别对上式[t0,t1,t2,…,tp,tp+1,…,tn]进行截断操作,分别令:
45、
46、
47、
48、…
49、…
50、
51、…
52、
53、…
54、
55、…
56、
57、…
58、
59、于是得到一个采样值矩阵:
60、
61、该采样值矩阵即为对应的虚拟传感器采样值,将虚拟传感器采样值代入机器学习函数得到下一步进的抽样角标,具体地,机器学习sigmoid函数如下式:
62、
63、其中,x属于集合{x|-1,|v|},|v|为传感器采样值,通过式(7)计算得到最新一次的实际抽样步进,实际抽样步进四舍五入后,再加上上一次的抽样角标,即得到新的抽样角标,计算完成抽样角标后,超时阈值ta++,直至大于超时报警ta,则意味着网路超时,可以生成一个断网报警推送给值班人员进行进一步审核。
64、进一步地,所述步骤5)中,所述循环采样队列f0的长度以能存储l小时的采样数据为基准,由此除以采样频率h,得到单个循环队列长度为n=l*3600/h。
65、有益效果:本发明与现有技术相比:
66、本方法提出了一套能够以合理的带宽消耗,提供尽可能精准的故障预报的方法,本技术基于神经网络学习函数,提出了一套基于sigmoid机器学习机制,可以实现越严重的故障反应越快的成果,在wit综合杆箱姿态传感器采样示例数据上,较为理想的实现了预定目标,相比现有较为普遍应用的云平台方式,机器学习的方法只需要约25%的有效带宽,实现38.57%报警带宽使用率、报警及时性能4.5倍、故障误报率的107.14%、异常采样排除率的102.22%。
67、同时,本技术还在alarmindex报警阈值次数与经济损失之间的权重,以及阈值步进散布规则,对云平台模式和机器学习方法进行了性能分析和对比。本技术的这些研究不但可以应用在综合杆箱体系中的设备状态监测,还能应用于同类型的其它工业物联网应用场景中。
68、随着大量传统路灯陆续被改造成为综合杆箱系统,大量的智能硬件将加增挂载。此时这些设备的维护,将成为设备单位新挑战。在道路环境下,各种错综复杂的工况因素,将对设备监测状态产生不同的病害和蜕化影响。受制于分布的广泛性和运营的长期性,城市运维部门有限的维护资源,必须容忍这些设备的带缺陷条件下的长期使用。本方法提出一种以有限的带宽消耗但能对带缺陷设备长期容忍的机器学习数据摘取方法,能保证对严重故障的迅速响应,一般病害故障定周期巡查,而越严重故障响应越及时的运行效果。同时其计算过程未采样复杂的逻辑判断,便于部署与性能和功耗较底的边沿网关硬件中。
- 还没有人留言评论。精彩留言会获得点赞!