基于视频模板的视频生成方法、系统、电子设备及介质与流程
本发明涉及视频合成,尤其是一种基于视频模板的视频生成方法和系统、电子设备及介质。
背景技术:
1、视频内容制作在日常生活中随处可见,用户通过制作视频内容来记录生活、彰显个性以及输出价值。视频制作通常有两种方式,一是自行录制视频并剪辑完善;二是通过上传若干图片生成特定的模板视频。模板视频合成由于操作方便、效果丰富,是视频内容分享的主要方式,各大互联网巨头均有研究并提供相关的模板视频生成能力,如火山引擎、剪映等。
2、随着视频模板效果的丰富和类型的增加,基于视频模板完成视频制作分享的需求和场景会日益增多。目前的视频模板合成主要有两种操作方式:
3、1)用户自主选择模板。用户通过一些标签,找到相关主题的模板,逐个查询并逐个尝试模板合成,查看视频效果,最终选择合适的视频模板。这种方式操作复杂,效率低下,很多用户在使用过程中,需要多次的合成尝试,才能找到最合适的模板,影响了用户的使用体验。
4、2)通用模版一键合成。基于一批通用视频模板进行视频合成,用户上传图片后,找出满足指定数量的模板,图像比例不适配时通过自动裁切或高斯模糊化处理,完成通用模板的比例适配及合成处理。但采用通用视频模板进行合成,经常出现效果不匹配的情况,影响了视频生成的效果和用户的使用体验。
技术实现思路
1、本发明的目的在于至少一定程度上解决现有技术中存在的技术问题之一。
2、为此,本发明实施例的一个目的在于提供一种基于视频模板的视频生成方法,该方法提高了视频的合成效率和用户的使用体验,使得视频生成的效果更好。
3、本发明实施例的另一个目的在于提供一种基于视频模板的视频生成系统。
4、为了达到上述技术目的,本发明实施例所采取的技术方案包括:
5、第一方面,本发明实施例提供了一种基于视频模板的视频生成方法,包括以下步骤:
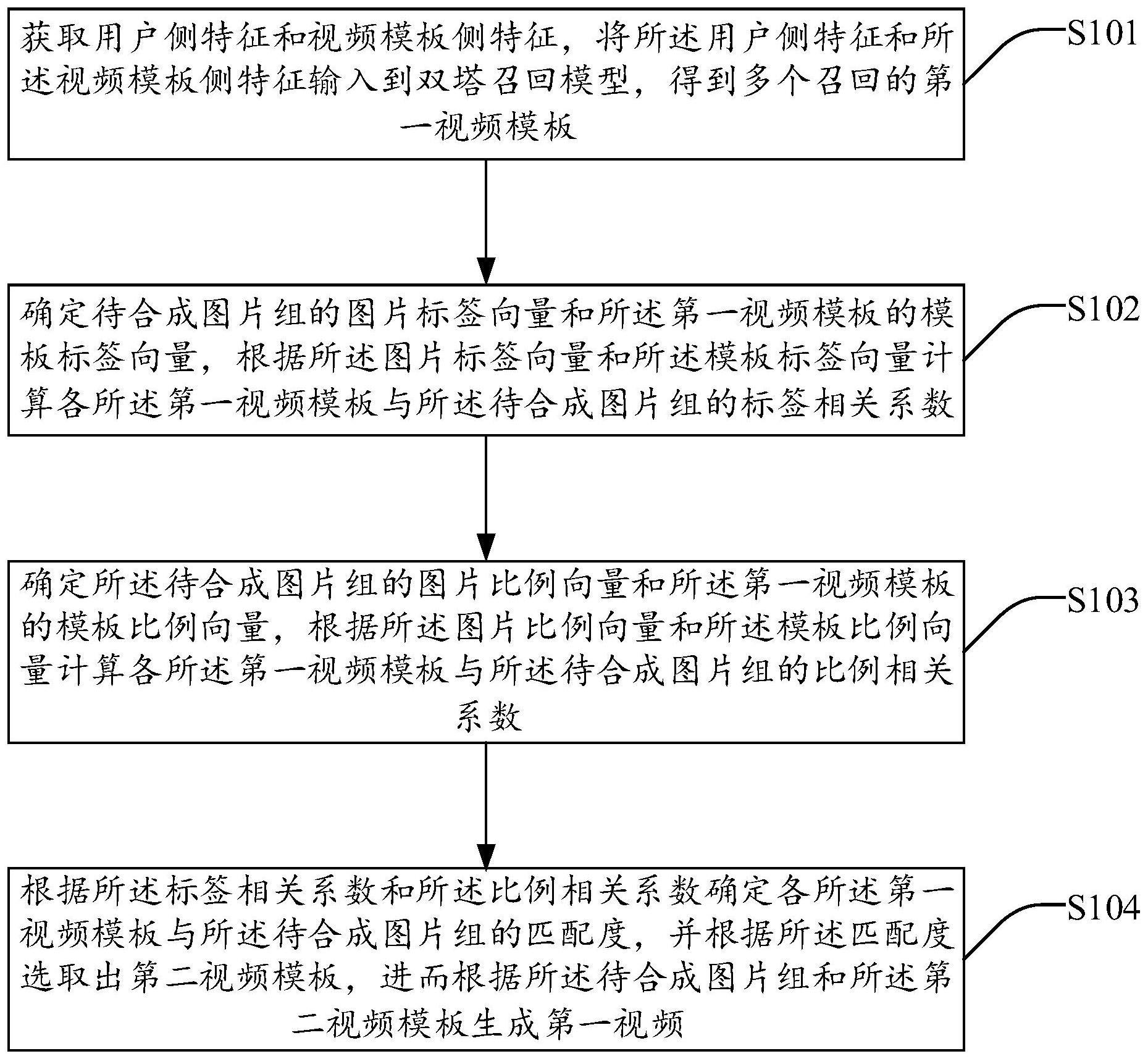
6、获取用户侧特征和视频模板侧特征,将所述用户侧特征和所述视频模板侧特征输入到双塔召回模型,得到多个召回的第一视频模板;
7、确定待合成图片组的图片标签向量和所述第一视频模板的模板标签向量,根据所述图片标签向量和所述模板标签向量计算各所述第一视频模板与所述待合成图片组的标签相关系数;
8、确定所述待合成图片组的图片比例向量和所述第一视频模板的模板比例向量,根据所述图片比例向量和所述模板比例向量计算各所述第一视频模板与所述待合成图片组的比例相关系数;
9、根据所述标签相关系数和所述比例相关系数确定各所述第一视频模板与所述待合成图片组的匹配度,并根据所述匹配度选取出第二视频模板,进而根据所述待合成图片组和所述第二视频模板生成第一视频。
10、进一步地,在本发明的一个实施例中,所述获取用户侧特征和视频模板侧特征,将所述用户侧特征和所述视频模板侧特征输入到双塔召回模型,得到多个召回的第一视频模板这一步骤,其具体包括:
11、获取目标用户的模板使用时间、模板使用频率以及模板使用偏好,根据所述模板使用时间、所述模板使用频率以及所述模板使用偏好确定所述用户侧特征;
12、获取目标视频模板的模板风格、模板类型以及模板节奏,根据所述模板风格、所述模板类型以及所述模板节奏确定所述视频模板侧特征;
13、将所述用户侧特征和所述视频模板侧特征输入到双塔召回模型,输出得到各所述目标视频板的召回率;
14、确定召回率大于等于预设的第一阈值的所述目标视频模板为所述第一视频模板。
15、进一步地,在本发明的一个实施例中,所述确定待合成图片组的图片标签向量和所述第一视频模板的模板标签向量,根据所述图片标签向量和所述模板标签向量计算各所述第一视频模板与所述待合成图片组的标签相关系数这一步骤,其具体包括:
16、获取目标用户上传的待合成图片组,所述待合成图片组包括多个待合成图片;
17、通过卷积神经网络对各所述待合成图片进行标签分类,得到各所述待合成图片的第一图片标签,并根据所述第一图片标签生成所述图片标签向量;
18、通过resnet残差网络对所述第一视频模板进行标签分类,得到所述第一视频模板的多个第一模板标签,并根据所述第一模板标签生成所述模板标签向量;
19、确定所述图片标签向量与所述模板标签向量的余弦相似度,根据所述余弦相似度确定所述各所述第一视频模板与所述待合成图片组的标签相关系数。
20、进一步地,在本发明的一个实施例中,所述确定所述待合成图片组的图片比例向量和所述第一视频模板的模板比例向量,根据所述图片比例向量和所述模板比例向量计算各所述第一视频模板与所述待合成图片组的比例相关系数这一步骤,其具体包括:
21、确定各所述待合成图片的第一图片比例,根据所述第一图片比例生成所述图片比例向量;
22、确定所述第一视频模板中各个模板区域的第一区域比例,根据所述第一区域比例生成所述模板比例向量;
23、将所述图片比例向量与所述模板比例向量进行向量维度比较,当两者的向量维度不一致,通过预设的填充向量对所述图片比例向量/所述模板比例向量进行填充处理,得到维度一致的图片比例向量和模板比例向量;
24、确定维度一致的图片比例向量与模板比例向量的归一化距离,根据所述归一化距离确定各所述第一视频模板与所述待合成图片组的比例相关系数。
25、进一步地,在本发明的一个实施例中,根据下式确定维度一致的图片比例向量与模板比例向量的归一化距离:
26、
27、其中,rpic_k表示图片比例向量vpic中第k个第一图片比例,rvideo_k表示模板比例向量vvideo中第k个第一区域比例,n表示图片比例向量vpic和模板比例向量vvideo的向量维度,dpic_video(vpic,vvideo)表示图片比例向量vpic与模板比例向量vvideo的归一化距离。
28、进一步地,在本发明的一个实施例中,所述根据所述标签相关系数和所述比例相关系数确定各所述第一视频模板与所述待合成图片组的匹配度这一步骤,其具体包括:
29、确定所述第一视频模板的内容属性权重和效果属性权重;
30、将所述内容属性权重作为所述标签相关系数的权重,将所述效果属性权重作为所述比例相关系数的权重,对所述标签相关系数和所述比例相关系数进行加权求和,得到所述第一视频模板与所述待合成图片组的匹配度。
31、进一步地,在本发明的一个实施例中,所述根据所述匹配度选取出第二视频模板,进而根据所述待合成图片组和所述第二视频模板生成第一视频这一步骤,其具体包括:
32、选取匹配度大于等于预设的第二阈值的若干个第一视频模板作为第二视频模板,或,选取匹配度排名小于等于预设的第三阈值的若干个第一视频模板作为第二视频模板;
33、根据所述第二视频模板对所述待合成图片组进行视频合成,生成所述第一视频。
34、第二方面,本发明实施例提供了一种基于视频模板的视频生成系统,包括:
35、视频模板召回模块,用于获取用户侧特征和视频模板侧特征,将所述用户侧特征和所述视频模板侧特征输入到双塔召回模型,得到多个召回的第一视频模板;
36、标签相关系数计算模块,用于确定待合成图片组的图片标签向量和所述第一视频模板的模板标签向量,根据所述图片标签向量和所述模板标签向量计算各所述第一视频模板与所述待合成图片组的标签相关系数;
37、比例相关系数计算模块,用于确定所述待合成图片组的图片比例向量和所述第一视频模板的模板比例向量,根据所述图片比例向量和所述模板比例向量计算各所述第一视频模板与所述待合成图片组的比例相关系数;
38、视频模板选取模块,用于根据所述标签相关系数和所述比例相关系数确定各所述第一视频模板与所述待合成图片组的匹配度,并根据所述匹配度选取出第二视频模板,进而根据所述待合成图片组和所述第二视频模板生成第一视频。
39、第三方面,本发明实施例提供了一种电子设备,所述电子设备包括存储器、处理器、存储在所述存储器上并可在所述处理器上运行的程序以及用于实现所述处理器和所述存储器之间的连接通信的数据总线,所述程序被所述处理器执行时实现如上述第一方面所述的基于视频模板的视频生成方法。
40、第四方面,本发明实施例还提供了一种存储介质,所述存储介质为计算机可读存储介质,用于计算机可读存储,所述存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现如上述第一方面所述的基于视频模板的视频生成方法。
41、本发明的优点和有益效果将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到:
42、本发明实施例获取用户侧特征和视频模板侧特征,将用户侧特征和视频模板侧特征输入到双塔召回模型,得到多个召回的第一视频模板,然后确定待合成图片组的图片标签向量和第一视频模板的模板标签向量,根据图片标签向量和模板标签向量计算各第一视频模板与待合成图片组的标签相关系数,再确定待合成图片组的图片比例向量和第一视频模板的模板比例向量,根据图片比例向量和模板比例向量计算各第一视频模板与待合成图片组的比例相关系数,最后根据标签相关系数和比例相关系数确定各第一视频模板与待合成图片组的匹配度,并根据匹配度选取出第二视频模板,进而根据待合成图片组和第二视频模板生成第一视频。本发明实施例先通过双塔召回模型筛选出符合用户特征的多个第一视频模板,然后基于标签相关系数和比例相关系数确定各第一视频模板与待合成图片组的匹配度,从而可以自动选取匹配度较高的第二视频模板对待合成图片组进行视频合成,避免了视频模板的主题内容或模板比例与待合成图片组不适配,提高了视频的合成效率和用户的使用体验,使得视频生成的效果更好。
- 还没有人留言评论。精彩留言会获得点赞!