用于声学透传的方法和系统与流程
本公开的方面涉及一种音频系统,该音频系统用于透传所选择的声音以由设备的用户听到。还描述了其他方面。
背景技术:
1、头戴受话器是包括一对扬声器的音频设备,当头戴受话器配戴在用户头部上或围绕用户头部配戴时,每个扬声器被放置在用户的耳朵上。类似于头戴受话器,耳机(或入耳式头戴受话器)是两个分开的音频设备,每个音频设备具有插入到用户耳朵中的扬声器。头戴受话器和耳机两者通常有线连接到单独的回放设备诸如mp3播放器,该回放设备以音频信号驱动设备的每个扬声器以便生成声音(例如,音乐)。头戴受话器和耳机提供用户可用以单独收听音频内容而不必将音频内容广播给附近其他人的一种方便的方法。
技术实现思路
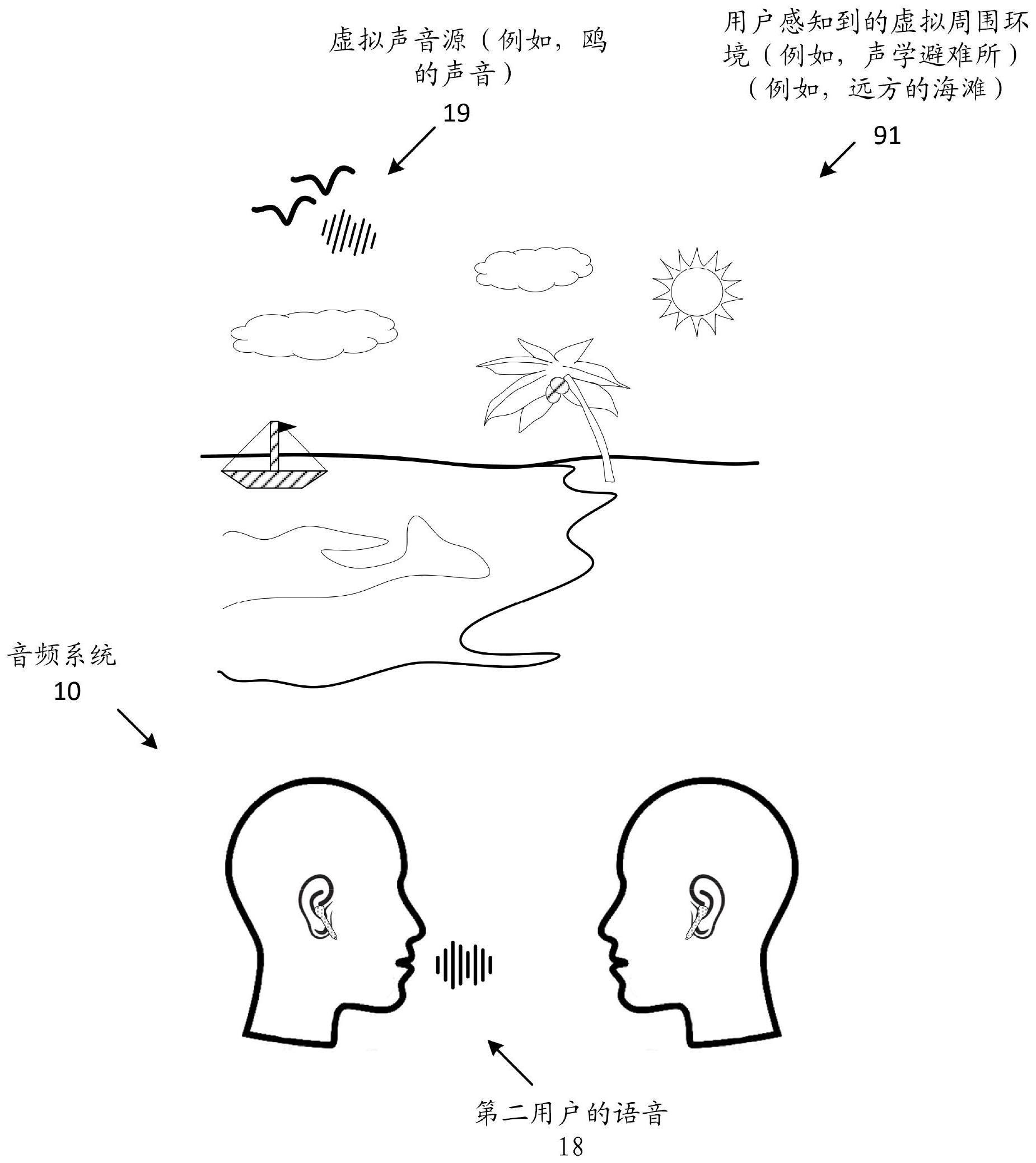
1、本公开的方面是由第一用户所穿戴的第一头戴式耳机(例如,入耳式头戴受话器)执行的方法。第一头戴式耳机对由第一头戴式耳机的麦克风捕获的麦克风信号执行降噪,该麦克风被布置成捕获第一用户所位于的周围环境内的声音。例如,头戴式耳机可从麦克风信号生成抗噪声信号,该抗噪声信号在用于驱动头戴式耳机的一个或多个扬声器时减少(或消除)用户对源自周围环境内的一个或多个周围声音的感知。头戴式耳机从由位于周围环境中的第二用户正穿戴的第二头戴式耳机并且通过无线通信链路(例如,蓝牙链路)接收由第二头戴式耳机的至少一个传感器产生的至少一个声音特性。例如,该特性可包括第二用户的话音的话音配置文件。第一头戴式耳机基于所接收的声音特性来透传来自麦克风信号的所选择的声音。具体地,第一头戴式耳机可执行周围声音增强(ase)过程,该ase过程使用第二用户的话音配置文件来从麦克风信号生成第二用户语音的声音再现(例如,作为音频信号),并且使用音频信号来驱动第一头戴式耳机的扬声器。因此,第一头戴式耳机生成声学避难所,在该声学避难所中用户不太感兴趣或不感兴趣的声音(例如,周围噪声)被减少(或消除),而感兴趣的其他声音(例如,在第一用户附近的第二用户的语音)被第一用户听到。
2、在一个方面,第一头戴式耳机在透传所选择的声音时空间再现虚拟声音源。在一些方面,虚拟声音源与虚拟周围环境相关联,第一用户和第二用户正通过其相应的头戴式耳机加入该虚拟周围环境。在另一方面,第一头戴式耳机进一步基于第一用户对第一头戴式耳机或第二用户对第二头戴式耳机的用户输入来从多个虚拟周围环境选择虚拟声音源将被第一用户感知为源自的虚拟周围环境。在一个方面,所空间再现的虚拟声音源被第一用户和第二用户感知为源自虚拟周围环境内的同一位置。在另一方面,第一头戴式耳机进一步确定周围环境内第一用户和第二用户之间的空间关系,其中虚拟声音源根据空间关系被空间渲染。在一个方面,确定空间关系包括基于第一用户的第一位置和第二用户的第二位置以及第一用户相对于第二用户的取向来限定第一用户和第二用户之间的共同坐标系,其中所空间再现的虚拟声音源根据共同坐标系定位和取向。
3、在一个方面,声音特性包括第二用户的话音的话音配置文件,其中透传所选择的声音包括:使用话音配置文件从麦克风信号选择第二用户的话音作为语音信号;以及利用语音信号驱动第一头戴式耳机的扬声器。在另一方面,声音特性包括指示第二用户的位置的位置数据,其中第一头戴式耳机进一步从第一头戴式耳机的多个麦克风获得多个麦克风信号;并且根据位置数据对多个麦克风信号使用波束成形过程生成包括第二用户的语音的波束成形音频信号,其中透传所选择的声音包括使用波束成形音频信号来驱动第一头戴式耳机的一个或多个扬声器。在一些方面,声音特性由第二头戴式耳机使用由第二头戴式耳机的一或多个麦克风捕获的一个或多个麦克风信号以及由第二头戴式耳机的加速度计捕获的加速度计信号生成。
4、在一个方面,第一头戴式耳机进一步确定第二头戴式耳机是否被授权以将声音特性发射到第一头戴式耳机,其中声音特性响应于确定第二头戴式耳机被授权而接收。在另一方面,确定第二头戴式耳机是否被授权包括基于从第一头戴式耳机的一个或多个传感器接收到的传感器数据来确定第二头戴式耳机在距第一头戴式耳机的阈值距离内;以及作为响应,确定与第二头戴式耳机相关联的标识符在存储于第一头戴式耳机内的列表内。
5、在一个方面,声音特性响应于基于传感器数据来确定第二用户正尝试参与和第一用户的对话而接收。在另一方面,声音特性是第一声音特性,其中第一头戴式耳机进一步从第一头戴式耳机的加速度计接收加速度计信号;并且基于加速度计信号来生成第二声音特性,其中所选择的声音基于第二特性来透传。
6、根据本公开的另一方面,一种由位于周围环境中的第一用户穿戴的第一头戴式耳机,该第一头戴式耳机包括:麦克风,该麦克风被布置成捕获来自周围环境内的声音作为麦克风信号;收发器,该收发器被配置为接收由位于周围环境中的第二用户所穿戴的第二头戴式耳机的至少一个传感器捕获的周围环境的声音特性;以及处理器,该处理器被配置为对麦克风信号执行降噪并且基于所接收的声音特性来透传来自麦克风信号的所选择的声音。
7、根据本公开的另一方面,一种由位于周围环境中的第一用户穿戴的第一头戴式耳机,该第一头戴式耳机包括:收发器,该收发器被配置为将周围环境的声音特性发射到由位于周围环境中的第二用户穿戴的第二头戴式耳机。例如,第一头戴式耳机可包括被布置成基于环境来生成传感器数据的一个或多个传感器,其中第一头戴式耳机可基于传感器数据来生成声音特性。第一头戴式耳机可包括处理器,该处理器被配置为对由麦克风捕获的麦克风信号执行降噪;并且基于声音特性来透传来自麦克风信号的所选择的声音。
8、在一个方面,声音特性是第一声音特性,并且所选择的声音是第一所选择的声音,其中收发器被进一步配置为从第二头戴式耳机接收周围环境的第二声音特性,其中处理器被进一步配置为基于第二声音特性来透传来自麦克风信号的第二所选择的声音。在另一方面,第二声音特性包括第二用户的话音配置文件,并且第二所选择的声音包括第二用户的语音。
9、在一个方面,处理器被配置为使用麦克风信号产生声音特性,该声音特性包括周围环境内的声音源的识别数据和位置数据中的至少一者。在另一方面,第一头戴式耳机还包括:若干麦克风,其中处理器通过使用包括定向波束方向图的波束成形器信号基于由若干麦克风捕获的多个麦克风信号来产生声音特性,其中将定向波束方向图朝向声音源引导。在一个方面,响应于确定第一用户正尝试参与和第二用户的对话而发射声音特性。
10、以上概述不包括本公开的所有方面的详尽列表。可预期的是,本公开包括可由上文概述的各个方面以及在下文的具体实施方式中公开并且在权利要求书中特别指出的各个方面的所有合适的组合来实践的所有系统和方法。此类组合可具有未在上述
技术实现要素:
中具体阐述的特定优点。
技术特征:
1.一种由第一用户所穿戴的第一头戴式耳机执行的方法,所述方法包括:
2.根据权利要求1所述的方法,还包括:在透传所选择的声音的同时空间再现虚拟声音源。
3.根据权利要求2所述的方法,其中所空间再现的虚拟声音源被所述第一用户和所述第二用户通过其相应的头戴式耳机感知为源自虚拟周围环境内的同一位置。
4.根据权利要求1所述的方法,还包括:
5.根据权利要求4所述的方法,其中确定所述空间关系包括基于所述第一用户的第一位置和所述第二用户的第二位置来限定所述第一用户和所述第二用户之间的共同坐标系,其中所空间渲染的虚拟声音源根据所述共同坐标系定位和取向。
6.根据权利要求1所述的方法,其中所述声音特性包括所述第二用户的话音配置文件,其中透传所选择的声音包括:
7.根据权利要求1所述的方法,其中所述声音特性响应于基于传感器数据确定所述第二用户正尝试参与和所述第一用户的对话而接收。
8.一种第一头戴式耳机,由位于周围环境中的第一用户穿戴,所述第一头戴式耳机包括:
9.根据权利要求8所述的第一头戴式耳机,其中所述第一头戴式耳机被进一步配置为在透传所选择的声音的同时空间再现虚拟声音源。
10.根据权利要求9所述的第一头戴式耳机,其中所空间再现的虚拟声音源被所述第一用户和所述第二用户通过其相应的头戴式耳机感知为源自虚拟周围环境内的同一位置。
11.根据权利要求8所述的第一头戴式耳机,其中所述处理器被配置为:
12.根据权利要求11所述的第一头戴式耳机,其中所述处理器被配置为:通过基于所述第一用户的第一位置和所述第二用户的第二位置以及所述第一用户相对于所述第二用户的取向限定所述第一用户和所述第二用户之间的共同坐标系来确定所述空间关系,其中所空间渲染的虚拟声音源根据所述共同坐标系定位和取向。
13.根据权利要求8所述的第一头戴式耳机,其中所述声音特性包括所述第二用户的话音配置文件,其中所述第一头戴式耳机通过以下方式透传所选择的声音:
14.根据权利要求8所述的第一头戴式耳机,其中所述声音特性响应于基于传感器数据确定所述第二用户正尝试参与和所述第一用户的对话而接收。
15.一种第一头戴式耳机,由位于周围环境中的第一用户穿戴,所述第一头戴式耳机包括:
16.根据权利要求15所述的第一头戴式耳机,其中所述声音特性是第一声音特性,并且所选择的声音是第一所选择的声音,其中所述收发器被进一步配置为从所述第二头戴式耳机接收所述周围环境的第二声音特性,其中所述处理器被进一步配置为基于所述第二声音特性来透传来自所述麦克风信号的第二所选择的声音。
17.根据权利要求16所述的第一头戴式耳机,其中所述第二声音特性包括所述第二用户的话音配置文件,并且所述第二所选择的声音包括所述第二用户的语音。
18.根据权利要求15所述的第一头戴式耳机,其中所述处理器被配置为使用所述麦克风信号产生所述声音特性,所述声音特性包括所述周围环境内的声音源的识别数据和位置数据中的至少一者。
19.根据权利要求18的第一头戴式耳机,还包括:多个麦克风,其中所述处理器通过使用包括定向波束方向图的波束成形器信号基于由所述多个麦克风捕获的多个麦克风信号来产生所述声音特性,其中所述定向波束方向图朝向所述声音源引导。
20.根据权利要求15所述的第一头戴式耳机,其中响应于确定所述第一用户正尝试参与和所述第二用户的对话而发射所述声音特性。
技术总结
本公开涉及用于声学透传的方法和系统。一种由第一用户所穿戴的第一头戴式耳机执行的方法,该方法包括:该第一头戴式耳机对由该第一头戴式耳机的麦克风捕获的麦克风信号执行降噪,该麦克风被布置成捕获该第一用户所位于的周围环境内的声音。该第一头戴式耳机从由处于该周围环境中的第二用户正穿戴的第二头戴式耳机并且通过无线通信链路接收由该第二头戴式耳机的至少一个传感器产生的至少一个声音特性,并且基于所接收的声音特性来透传来自该麦克风信号的所选择的声音。
技术研发人员:P·莫盖,J·D·谢弗,D·M·费歇尔,J·伍德鲁夫,T·S·维尔马
受保护的技术使用者:苹果公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!