一种基于智能体交互深度强化学习的室内定位方法与流程
本发明属于室内定位,具体涉及一种基于智能体交互深度强化学习的室内定位方法。
背景技术:
1、近年来,随着物联网技术的发展,各种基于智能终端设备的个性化服务层出不穷,尤其是以位置服务为基础(lbss)的服务需求不断增长,而其中室内环境下的位置服务也是受到了越来越多的关注与研究。
2、像北斗、gps、gnss这样传统的室外位置服务技术应用到室内环境中会存在诸多问题,如室内环境的信号弱度通常比室外弱,这会影响定位精度;室内定位需要通过物理障碍,因此其信号会受到干扰;室内环境存在多径效应;遮挡问题;室内环境通常有大量的电子设备,如手机、笔记本电脑等,这可能对定位信号造成干扰;算法适应性问题,室外定位技术通常基于gps和全球定位系统,但这些算法在室内环境下并不适用,室内环境需要更高精度的定位方法,例如wi-fi定位、蓝牙定位等。因此,在室内环境中使用室外定位技术可能导致定位精度不够高,无法满足室内环境的定位需求;此外,室外定位技术的设备成本较高,不太适合室内环境。
3、总之,在室内环境中使用室外定位技术存在很多问题,因此专门针对室内环境的定位技术是更加理想的选择。例如,基于rssi指纹信号的室内定位技术因其价格低廉、不受室内复杂环境的影响以及无需携带繁杂的传感设备的优势,可以广泛应用于各种室内环境,被众多学者关注。
4、在室内定位领域,rss指纹是一种常用的技术,可以通过采集一定数量的rss信号和位置信息建立rss指纹数据库,然后在需要定位的时候通过当前位置的rss值与数据库进行匹配定位。然而,rss信号在室内环境中容易受到干扰和衰减,导致定位误差较大。同时,室内环境中存在复杂的障碍物和多个rss信号源,这些因素都会影响rss信号的强度和分布。并且,基于信号强度rss的指纹室内定位技术通常需要事先构建带标签的指纹数据库,需要对环境划分网格后并对采集到的rss指纹信息人工打上标签,这一过程需要花费的时间成本和人力成本是巨大的。
5、近年来,随着人工智能技术的发展,强化学习在室内定位领域的应用日益增多,基于强化学习的室内定位也成为了一种新兴的定位技术。它具有以下几个方面的优势:1.高精度:强化学习算法能够在不断地学习过程中,通过改变策略来适应室内环境的复杂性,从而提高定位的精度;2.自适应性:基于强化学习的定位系统可以根据室内环境的不断变化来自动调整策略,以提高定位效果;3.鲁棒性:强化学习算法可以适应环境中的干扰,如强干扰、遮挡等,提高室内定位的鲁棒性;4.智能性:强化学习算法可以通过不断学习,提高室内定位系统的智能水平,使其能够在复杂环境中进行定位。
技术实现思路
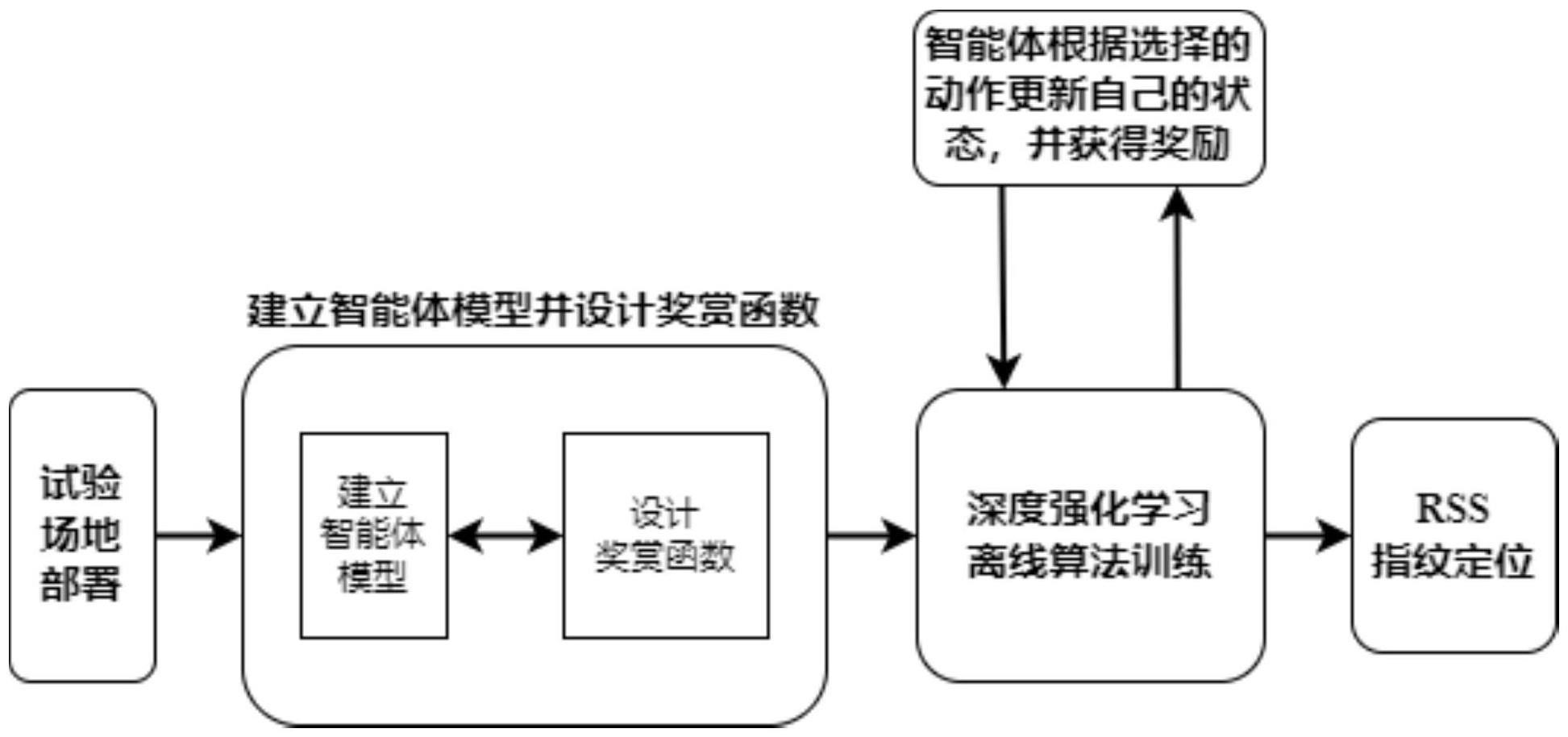
1、本发明的目的是为了提高室内定位精度,因此结合多智能体技术和深度强化学习算法来提高非参数化室内定位精度,从而提出一种基于智能体交互深度强化学习的室内定位方法。基于智能体交互的强化学习室内定位方法考虑从强化学习的角度进行高精度目标定位,实现智能体在动态环境下的自学习。强化学习不需要掌握先验知识,而是通过不断地从室内环境中的rss值中学习并做出反馈的方式,依靠不带标签的指纹数据就能实现定位,降低了对标签数据的依赖;并在此基础上解决上述提到的关键性问题;再者,强化学习的过程也是不断优化模型的过程,通过持续采集信号强度值来更新自身模型,对于复杂多变的室内环境具有更高的稳定性。强化学习与深度学习相结合的深度强化学习(deepreinforcement learning,drl)技术可以解决高维的“状态空间-行动空间”问题,同时能够在没有先验知识的情况下进行端到端学习;即智能体通过不断地与环境进行交互来寻找最优的行动策略,从而达到精确定位的目的。
2、本发明所采用的技术方案为:
3、一种基于智能体交互深度强化学习的室内定位方法,利用多个智能体协同学习,通过深度强化学习算法获取rss指纹信息并实现室内定位;包括以下步骤:
4、s1、在定位区域设置l个rss信号基站,l>3;在定位区域选择一点作为原点,建立空间三维坐标系,在定位区域环境中采集带标签的rss指纹数据以及无标签rss指纹数据组成指纹数据库,选择一部分带标签数据集作为测试集;
5、s2、在室内环境中设置多个智能体,每个智能体通过收集周围的rss信号强度值和位置信息来更新自己的状态;每个智能体可以看作是一个有限马尔可夫决策过程(markovdecision process,mdp),定义每个智能体的状态包括当前位置和周围rss信号,智能体的动作是移动到周围的一个位置,并观察该位置处的rss信号和位置信息,从而更新自己的状态;对每个智能体接收到的每个ap的rss值设置一个信号阈值θrss并对每个ap的距离设置一个距离阈值θd,用cij∈{0,1}表示第i个智能体接收到第j个ap的信号强度值,i=1,2,…,k,j=1,2,…,l,定义向量ci=[ci1,ci2,…,cij,…,cim]t代表第i个智能体接收信号强度阈值指示向量,‖ci‖代表向量ci中非0元素个数,dij表示的是以智能体前一时刻t-1估计的坐标信息(xt-1,yt-1)作为当前位置得到的与第j个ap之间的距离,从而设置奖赏函数为:
6、
7、其中,表示第i个智能体与最大rss值所对应的ap通过该智能体前一时刻估计的坐标信息计算得到的距离值,r(d)定义为:
8、
9、其中,dmin是一个提前设置固定值;
10、s3、利用深度强化学习算法训练多智能体模型,使其能够学习到最优的移动策略,以便在室内环境中实现高精度定位;具体包括:
11、s31、采用double deep q-network算法初始化多智能体模型以及参数;
12、s32、将多个智能体放置在不同的位置,并随机选择一个目标位置;
13、s33、根据智能体在当前位置观察到rss信号强度值和位置信息获得智能体状态,并选择一个动作来移动到周围的位置;
14、s34、智能体根据选择的动作更新自己的状态,并获得奖励;
15、s35、重复s33和s34,直到智能体到达目标位置;
16、s36、记录每个智能体的状态和奖励,将其作为样本用于深度强化学习算法的训练;
17、s37、训练多智能体模型:
18、状态表示:将rss向量作为状态s输入神经网络;
19、行动选择:利用当前的神经网络估计每个动作的q值;对于每个状态,选择具有最高q值的动作;
20、与环境交互:将所选动作a作用于环境,得到下一个状态s'和奖励r;
21、s38、测试并记录下每个智能体的分类器在测试集上的定位精度表现,作为多智能体模型的性能收敛准则:
22、经验存储:将s,a,r,s'作为经验存储在经验回放池中;
23、神经网络更新:从经验回放池中随机采样一些经验,用它们来训练神经网络;目标q值的计算方式如下:
24、
25、其中,r是奖励,γ是折扣因子(用于控制未来奖励的重要性),表示在下一个状态s'下,所有可能动作的最大q值;
26、s39、重复s32到s38,根据梯度下降准则,进行反向传播并逐步优化网络参数:
27、
28、其中,是在经验e=(s,ai,r,s')下的期望值,y表示实际结果、q(s,ai;θi)表示q网络的输出结果、表示q网络的输出对θi的偏导数,直到多智能体模型的性能收敛,完成训练过程;
29、s4、在实际定位过程中,实时收集当前位置处的rss值,并输入到训练好的多智能体模型中,多智能体模型根据该位置处的rss值和状态信息,选择一个最优的移动策略,并输出预测的位置信息。
30、本发明的有益效果为,本发明建立了基于深度强化学习网络的优化定位模型,所提模型不依靠室内环境场的先验信息,可实现nlos环境下的三维定位。实测结果显示:1)与其它强化学习定位方法相比,本发明的方法定位精度更高,对基站布设不敏感;2)对比了改进搜索范围的double dqn优化算法的定位结果,本发明定位方法可通过较少耗时实现更稳定的定位性能。
- 还没有人留言评论。精彩留言会获得点赞!