一种基于多智能体联邦学习的车联网边缘缓存决策方法及系统
本发明涉及车联网,具体涉及一种基于多智能体联邦学习的车联网边缘缓存决策方法及系统。
背景技术:
1、随着5g和6g通信技术的应用与发展,实现汽车的智能网联已被提上科研日程,车联网应运而生。在蜂窝网的一般架构中,智能网联汽车通过直接与基站通信来获取所需要的如自动驾驶辅助决策信息,路况信息和影音娱乐信息。然而,由于基站需要同时服务多个车辆且车辆通常拥有一定的移动速度。智能网联汽车从基站下载文件的传输连接通常是不稳定的,传输速率通常是较慢的。基站所能提供的服务质量和用户日益增加的服务质量要求要求是不匹配的。
2、通过将流行度高的即用户访问可能性大的文件缓存至路边单元(rsu)中使智能网络车辆能够以更快的速率和更高的稳定性获取文件。因此,决定应该将什么内容缓存在rsu中就显得格外重要。一方面,传统的缓存算法如先进先出(fifo)和后进先出(lifo)只关注了文件一定时间内的流行度而不能够从长远的视角审视流行度的变化,因此现有研究多采用机器学习方法如长短期记忆网络(lstm)来预测全局流行度变化。然而,以全局的视角预测流行度存在着一定的劣势。其一,对于被分割为多个功能区的城市,每个区域内用户的偏好内容可能有所不同,意味着用户的偏好不仅随时间更会随空间变化,全局流行度预测模型不能准确反映出文件的时空流行度偏好。其二,现有研究中的流行度预测模型构建多由云端完成,这就不可避免的需要用户将其请求上传至云端,造成用户隐私泄露,这与公众日益增强的隐私保护意识不符。另一方面,即便采用了时间序列预测模型,其对于缓存内容决策的灵活性和精确性仍然是不足的。在进行缓存决策时除流行度以外有更多的参数需要考虑,例如,待选的缓存文件有不同紧急程度来标志其传输的最长时延限制;rsu的连接数即带宽占用情况;智能网联汽车请求相应文件的接收情况等。强化学习(rl)作为一种能够针对多维环境参数进行最优决策的机器学习方法,是解决缓存决策问题的不二之选,然而集中式的强化学习通常会遭遇规模极大的状态-动作空间,造成模型不收敛或效果差。此外,随着缓存文件大小的增加,智能网络车辆通常不能完整接收缓存在rsu中的文件,造成缓存空间的浪费。
技术实现思路
1、本发明的目的在于提供一种基于多智能体联邦学习的车联网边缘缓存决策方法及系统,以解决集中式的强化学习通常会遭遇规模极大的状态-动作空间,造成模型不收敛或效果差,此外,随着缓存文件大小的增加,智能网络车辆通常不能完整接收缓存在rsu中的文件,造成缓存空间的浪费的问题。
2、为实现上述目的,本发明采用以下技术方案:
3、第一方面,本发明提供基于多智能体联邦学习的车联网边缘缓存决策方法,包括:
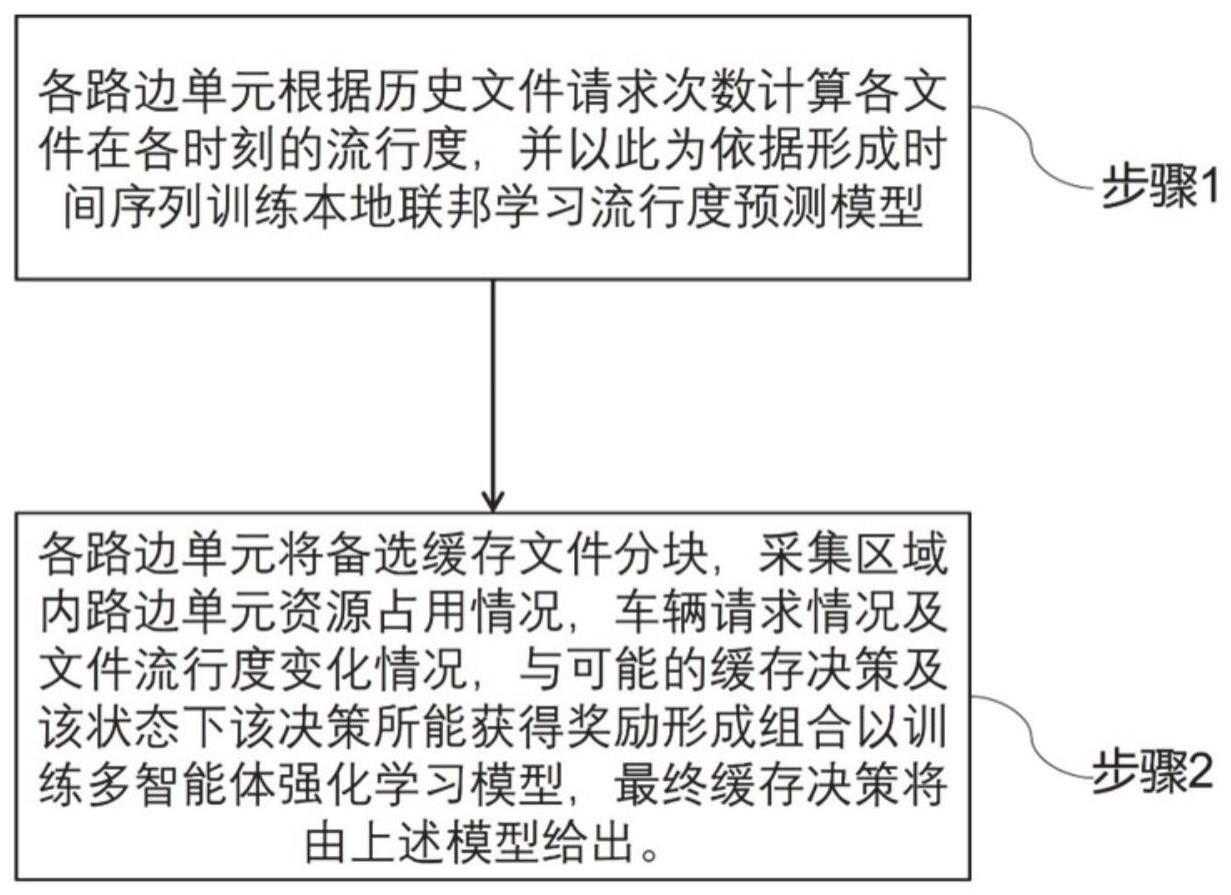
4、获取各个路边单元数据,根据各路边单元的历史数据请求次数计算各数据在各时刻的流行度;
5、根据各数据在各时刻的流行度,形成时间序列训练本地联邦学习流行度预测模型;
6、各路边单元将备选缓存文件分块,采集区域内路边单元资源占用情况,车辆请求情况及流行度变化,与可能的缓存决策及该状态下该决策所能获得奖励形成组合以训练基于深度q网络dqn多智能体强化学习模型,输出缓存决策。
7、可选的,根据各路边单元的历史数据请求次数计算各数据在各时刻的流行度:
8、各个路边单元将统计历史各时刻各区域内各个文件被请求的次数并将其按升序排列并记录其顺序编号,将各个文件编号通过齐夫分布进行规范化,计算出确切的文件流行度;将各区域各时刻的文件流行度形成时间序列作为本地基于lstm的联邦学习模型的训练集。
9、可选的,各区域内的路边单元将采集仿真环境中的具体参数与进行相应缓存决策后的奖励指标作为多智能体强化学习的训练集,具体过程如下:
10、车辆所请求的文件包含能够辅助驾驶决策的摄像头画面文件,路况信息导航文件,娱乐与商业信息文件;部署在各路边单元中的强化学习模型将以文件分块作为最小缓存单元,文件分块具有和其所属文件相同的流行度和紧急程度;在仿真环境中,车辆将以固定的速度行驶,遇到十字路口时以相同的概率从左转、右转和直行选择行进方向并将以实际文件流行度请求文件,车辆同时只能请求一个文件分块,在文件成功传输后或超时后才能请求新的文件且车辆同时只能与一个设备进行通信;若路边单元未缓存相应的文件分块,则相应的车辆将会选择直接与基站进行通信进行文件传输;在各个时刻,各个路边单元将收集包括各服务范围内正与自身通信的车辆数量,当前时刻由训练完成的本地联邦学习模型预测出的各个文件的区域流行度,当前时刻服务范围内车辆正在请求分块,各车辆的传输任务还有多长时间超时以及各车辆已经接收了多少个文件分块的状态集合,并根据所设定的dqn的贪婪因子选取本地强化学习所认为的当前状态下的最优策略或随机从可能的缓存决策中选取一个作为当前动作并记录采取该动作后进入到的新的状态;进而,各个路边单元计算出当前状态-动作组合下所能获得的奖励,此处的奖励定义为各传输任务在成功接收时实际使用时间和对应文件最大传输时延要求之间的差值;最终,各个路边单元汇总其统计到的状态-动作-奖励-下一状态至公共的dqn经验池中;强化学习模型将从记忆池中抽取统计的经验进行学习,并在得到充分学习给出相对各时刻各区域相对最优的缓存决策。
11、可选的,共用价值网络和经验池的dqn从各区域内统计获取经验并学习,最终给出缓存决策,其过程如下:
12、s1,初始化全局时刻t=0,步骤1中各本地基于lstm的联邦学习模型给出预测流行度
13、s2,若仿真场景中总驶入车辆数小于考虑的最大车辆数,则车辆依据泊松分布驶入仿真场景,驶入的车辆初始化其请求的文件f;各路边单元j统计各自服务范围内的状态集合st,根据所设置贪婪因子κ选取缓存决策at;
14、s3,车辆于仿真道路中行驶根据所属范围内的路边单元j的缓存情况at决定其是与路边单元j通信还是与基站m通信,并向所决定的请求设备接收文件分块kf,n,记录该时刻接收该文件已用的时间
15、s4,各路边单元j根据s2中所统计的st和at计算出所能获得的奖励r(st,at),记录在st状态下执行at,若总驶入场景中的总车辆小于考虑的总车辆数目则新的车辆依据泊松分布驶入场景并初始化请求文件f,全局时刻t=t+1;本地联邦学习模型给出新的流行度预测结果各车辆更新其位置若其文件接收已结束则重新初始化其请求的文件f;此时仿真环境进入到的新的状态st+1,各路边单元将<st,at,r(st,at),st+1>储存至公共经验池b中若此时仿真环境中仍存在车辆,转至s2;
16、s5,部署在各路边单元中的dqn从经验池b中抽取一定量s3中储存的组合进行学习,若训练未达到指定的轮数则转向s1;达到要求的轮数后则输出最终缓存决策强化学习模型。
17、可选的,在s2中,车辆根据泊松分布驶入仿真场景中,各路边单元j收集各自服务范围内文件属性情况及车辆接收情况,执行相应的缓存决策并初步观测奖励情况并更新仿真场景状态,其各处理步骤如下:
18、s201,各路边单元j观测正与自身通信的车辆集合
19、s202,各路边单元j观测中的车辆正在请求的文件分块集合
20、s203,各路边单元j观测当前各文件流行度集合
21、s204,各路边单元j计算中各车辆传输任务距超时剩余时间集合
22、s205,各路边单元j统计中各车辆的分块接收情况
23、s206,各路边单元j生成一个随机数,若该随机小于等于贪婪因子κ则转入s207,否则转入s208;
24、s207,路边单元选择目前强化学习认为最优的缓存决策,转入s209;
25、s208,路边单元随机选择缓存决策,转入s209;
26、s209,各路边单元生成状态-动作组合<st,at>;
27、各路边单元选定缓存决策后,仿真场景中的车辆将根据其信号覆盖范围内路边单元的缓存情况选定通信设备,接收文件分块;具体步骤如下所示:
28、s301,若车辆请求的文件分块被相应的路边单元缓存,则转入s302,否则转如s303;
29、s302,车辆选择与所属的路边单元以速率rj→i进行通信,转入s304;
30、s303,车辆选择与基站以速率rm→i进行通信,转入s304;
31、s304,各车辆记录接收整个文件的已用时间
32、自s3后,各路边单元已取得了状态st和动作at的组合数据。
33、可选的,s4给出在此组合下奖励的计算方法并更新全局系统状态,其步骤如下:
34、s401,各路边单元计算在<st,at>组合下服务范围内各个车辆的文件请求情况,初始化各路边单元的奖励值r(st,at);
35、s402,如果车辆在时延要求内完成传输任务,则转入s403;若某个车辆请求文件超时,则转入s404;
36、s403,该组合下该车辆处于的路边单元的r(st,at)加入该车辆请求该文件的最大时延要求和实际使用时间之间的差值,转入s405;
37、s404,全部服务过该车辆的路边单元的r(st,at)加入与文件紧急程度ωf相关的惩罚因子δf,转入s405;
38、s405,若仍有车辆未被统计则转入s402,否则转入s406;
39、s406,各路边单元形成<st,at,r(st,at)>;
40、s407,全局时刻t=t+1,场景内的车辆更新其位置若其文件请求已结束,重新初始化其请求文件f;
41、s408,若驶入仿真中的场景车辆未达到所考虑的最大数量,则由泊松分布生成新的车辆,初始化其请求文件f;
42、s409,各路边单元储存<t,t,(st,t),t+1>于公共经验池b中。
43、可选的,在s1中,各区域各时刻的文件流行度由各候选文件的流行度排序序号齐夫分布以及该分布的系数μ所决定;的计算公式如下
44、
45、设定道路为双向四车道且有两个十字路口的城市道路,路边单元的总数为j,每个路边单元j分管1个区域,且j∈{1,2,…,,…,};车辆的总数量为i,其中每个车辆的编号为i,且i∈{1,2,…i,…i},车辆可能请求的文件集合是f∈{1,2,…,,…f},文件f将被分割为若干个分块kf,n其中n为该文件的第n个分块;文件分块与其对应的文件具有相同的流行度和紧急程度ωf;全局时刻t从0时刻开始且t∈{0,1,…,,…,};
46、在s2中每个时刻将有num量车的驶入,且num服从参数为λ的泊松分布,其表达式如下所示
47、
48、在s3中,假设路边单元和进展均使用非正交多址接入,即通信的带宽将被平均分配且通信的内部干扰将被忽略,车辆i与基站m在时刻t的传输速率被表达为
49、
50、其中,bm,pm,hi,m,σ2分别为基站m的带宽,基站m在t时刻的连接数量,基站m的传输功率,与车辆i之间的信道增益,在t时刻与车辆i的距离和环境噪声功率;具体的,由欧式距离所计算,即
51、
52、路边单元j与车辆i的传输速率被计算出;在s304中,车辆i接收文件f实际使用时间di,f与接收该文件每一个分块kf,n所用的时间tf,n之间的关系是
53、
54、文件分块大小与tf,n的关系被表示为
55、
56、其中是t时刻路边单元j对文件分块kf,n的缓存决策1表示缓存,0表示未缓存;相对的为的共轭或布尔取非;
57、在s406中,r(st,at)被具体定义为
58、
59、其中,用来指示车辆i接收文件f的传输任务是否在t时刻完成,完成取1,未完成取0。用来指示传输任务是否超时,未超时取1,超时取0。δf是与文件紧急程度相关ωf的惩罚因子。
60、第二方面,本发明提供基于多智能体联邦学习的车联网边缘缓存系统,包括:
61、数据获取模块,用于获取各个路边单元数据,根据各路边单元的历史数据请求次数计算各数据在各时刻的流行度;
62、流行度预测模块获取模块,用于根据各数据在各时刻的流行度,形成时间序列训练本地联邦学习流行度预测模型;
63、输出模块,用于各路边单元将备选缓存文件分块,采集区域内路边单元资源占用情况,车辆请求情况及流行度变化,与可能的缓存决策及该状态下该决策所能获得奖励形成组合以训练基于深度q网络dqn多智能体强化学习模型,输出缓存决策。
64、第三方面,本发明提供一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现基于多智能体联邦学习的车联网边缘缓存决策方法的步骤。
65、第四方面,本发明提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现基于多智能体联邦学习的车联网边缘缓存决策方法的步骤。
66、与现有技术相比,本发明有以下技术效果:
67、本发明提供了一种基于多智能体联邦学习的车联网边缘缓存决策方案,通过将某些文件缓存在路边单元上,大幅提高车辆请求文件的速率和稳定性,解决了直接与基站通信造成的基站服务压力大,服务质量差的问题。本发明首先利用区域历史数据在保证用户隐私的情况下训练本地区域流行度联邦学习模型以预测文件区域流行度。其次,本发明联合使用了多智能体强化学习,通过考虑文件的紧急程度,流行度;车辆接收文件的情况以及路边单元的连接数即带宽占用情况,灵活智能的实现了缓存决策。本发明相较于传统的缓存算法fifo和lifo,在缓存命中率上平均提升了10%,达到了60%左右;在平均传输时延上减少了约2s,达到了每个传输任务耗时14s,缓存性能优越。
- 还没有人留言评论。精彩留言会获得点赞!