基于可编程交换机的分布式图计算网内聚合方法及系统
本发明涉及可编程交换机和分布式图计算系统,并特别涉及一种基于p4可编程交换机的分布式图计算网内聚合方法及系统。
背景技术:
1、随着互联网基础设施的高速发展,互联网服务提供商采集到的服务数据和用户数据日益增多。为了挖掘数据中的潜在价值、充分利用这些数据,将大量的半结构化数据组织成图数据,并在图数据上进行图计算成为一种重要趋势。分布式图计算系统作为实现这一目标的基础计算设施,成为互联网服务提供商进行大规模图计算必不可少的重要系统。然而随着分布式集群和图计算数据集规模的扩大,分布式图计算系统面临着任务分配不均衡、计算负载过重、通信开销过大、网络资源浪费等挑战。
2、因此,在大规模图数据上进行图计算成为一种重要趋势,针对图数据在存储、访存、计算和通信等方面的特性进行优化成为学术界和工业界一个新的研究热点。
3、为了搭建大规模图数据的高效计算系统,研究人员一方面不断优化单机内存和计算上的资源利用,提升单机图计算的性能。例如,一些研究工作提出基于三位堆叠、pcm等提升内存存储空间利用效率的改进方法;bulu搭建的高性能图计算引擎,则是利用图数据结构和稀疏矩阵在数学上的等价关系,将图计算问题转化为矩阵计算问题,再应用高性能计算领域已有的诸多矩阵计算优化技巧进行优化;或是基于存上计算(pim,process-in-memory)的新型体系结构直接在内存上进行预处理提升系统的效率。这些基于单机的研究工作限制在较小规模的图计算场景,能够更加高效地探索出新的图计算特性加以利用。
4、另一方面,适合大规模图数据计算的分布式图计算系统也吸引了学术界和工业界的大量关注。在pregel解决了大规模图计算系统的扩展性和易用性后,越来越多的研究开始关注分布式图计算过程中的资源利用问题。微软提出cost(configurationthatoutperformsasinglethread)用于判别一个分布式系统对硬件资源的利用率。一个分布式系统的cost值为c意味着该系统只有在横向扩展到c个计算节点后性能才能超过一个经过仔细人工优化的单线程实现。根据测试,很多常用的分布式图计算系统的cost值都高达上百,如graphx、graphlab、x-stream等。这意味着基于集群的分布式图计算方案尽管能够通过横向扩展的方式增加计算的规模,但是也因分布式计算过程中存在大量的协同、通信成本,而导致在运行效率方面存在非常大的优化空间。针对这一问题,有大量研究工作着力于提升分布式图计算系统的效率。powergraph提出基于定点的图切分方案,更适合服从幂律分布的图数据计算。powerlyra进一步研究偏斜分布,提出组合顶点分割和边分割的混合方案。graphx基于spark设计了通用的流式图计算方案。gemini基于mpi多核编程和numa存储优化了分布式图计算的并行度。总体上来看,由于图计算的高访存计算比,相关研究工作主要集中在改善计算过程中计算任务分配的均衡性,以及通过缓存、存储优化等方式改进计算的局部性。
5、伴随可编程网络的蓬勃发展,交换机等网络中间件具备了通信功能之外的灵活计算能力。通过将部分依赖通信的计算任务卸载到网络中,能够进一步释放计算终端上的宝贵资源。同时网内聚合能够实现通信和计算的叠加,改善分布式计算的整体性能。iswitch、switchml、atp等采用可编程交换机的方案,直接通过将聚合逻辑在交换机上硬件化,实现高吞吐的线速度聚合。但是这些工作的应用场景是分布式机器学习中的梯度聚合任务。在按照数据并行的梯度聚合任务中,不同机器上的数据是一致的,在每一轮迭代中所有的数据都会发送到中间节点进行聚合。不同于该数据并行场景下聚合任务较为规整,分布式图计算将图数据按照以点划分或者以边划分的方式放到不同计算节点上,不同计算节点负责不同的数据。由于不同机器上划分的是图上不同部分的节点,连接不同节点的边是随机出现的,因此每轮聚合任务依赖的机器和节点都是动态变化的。
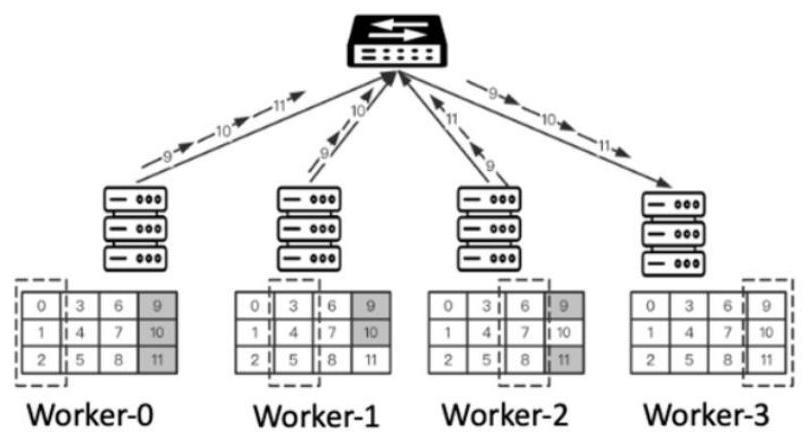
6、如图1举例来看,分布式图计算场景下,含有6个图节点的完整图数据被切分到3个计算节点上并行计算。本地节点维护白色图节点的状态,灰色节点为需要发送待聚合消息的目标图节点,如图1,图节点3由计算节点node1维护,图节点3消息的更新需要来自node0的图节点1和来自node2的图节点5上的待聚合消息。所谓聚合任务以来的机器和节点的动态性是指节点依赖的待聚合消息来自的图节点是随机的,并且这些图节点在机器上的分布也是随机的,因此每个节点状态的更新以来的图节点和机器是动态变化的。
7、上述在网计算的相关工作由于忽视了图数据天然的稀疏性和幂律分布特性,并不能直接应用到图计算场景。因此在图计算场景下,必须结合图数据特性才能高效利用到网络可编程设备上的计算能力。
8、当前存在针对分布式图计算系统在单机计算优化以及多机并行优化上的改进主要在改进单机上的计算和访存效率、多机上场景下的任务均衡划分、通行和计算的并行,忽略了网络设备的计算能力。可编程交换机等网络中间设备目前具有了一定的计算能力,能够在数据包传输过程中完成计算功能,同时具备高吞吐和低延迟。
9、利用可编程交换机进行网内计算的方案iswitch、switchml、atp等面向的场景是分布式机器学习中全连接网络梯度反向传播的聚合任务,聚合的数据规整,并不适用于图计算场景下参与聚合的机器和待聚合的节点都动态变化场景。因此本发明提出适合分布式图计算场景的新算法,卸载分布式图计算场景下终端上的部分计算任务到可编程交换机上。
10、同时针对非理想网络情况下的丢包和延迟问题,网内聚合算法需要确保可靠性,即能够在丢包和延迟发生时保证任务的计算正确性。现有的iswitch、switchml、atp等方案面向的场景是分布式机器学习中全连接网络梯度反向传播的聚合任务,聚合的数据规整,每个终端发送和等待接收的数据是提前确定的,因此只需要在发送方没有接收到ack确认时重发数据包即可。但是,分布式图计算场景下的每个终端发送和接收的消息都是不确定的,现有的上述方案中的可靠性算法无法保障。因此本发明提出了适合分布式图计算场景的网内聚合可靠性算法。
技术实现思路
1、本发明的目的是优化分布式图计算系统的计算效率,通过在网计算的方式对分布式图计算系统中计算终端上的聚合任务进行卸载,降低计算终端负载和交换机到聚合结果接受方的下行数据通信量,从而提升分布式图计算系统的计算效率。
2、针对现有技术的不足,本发明提出一种基于可编程交换机的分布式图计算网内聚合方法,其中包括:
3、步骤1、获取包含多个图节点的图计算任务,将图计算任务中各图节点计算任务对应划分给分布式图计算系统的计算终端;在该分布式图计算系统内可编程交换机维护一个next[]数组,其大小为该分布式图计算系统中计算终端总数,next[]数组用于记载计算终端需要聚合的图节点id作为当前待聚合id;
4、步骤2、计算终端判断该当前待聚合id是否为计算终端本地需要聚合的节点id,若是则将其负责的当前待聚合id上的消息发送到该可编程交换机;
5、步骤3、该可编程交换机收到来自各计算终端的当前待聚合id上的信息,执行网内聚合操作,得到当前待聚合id的聚合结果,将该聚合结果发送给与其对应的计算终端;
6、步骤4、该可编程交换机维护next[]数组,使next[i]指向下一轮要聚合的图节点id作为该当前待聚合id,并将该当前待聚合id发送给所有计算终端,再次执行该步骤2,直到该图计算任务中最后一个图节点的网内聚合完成,将最后一个图节点的聚合结果发送给与其对应的计算终端,得到图计算任务的计算结果。
7、所述的基于可编程交换机的分布式图计算网内聚合方法,其中该可编程交换机按照图节点id从小到大的顺序进行网内聚合,以确保该可编程交换机每次下发聚合结果数据包中的next_id递增。
8、所述的基于可编程交换机的分布式图计算网内聚合方法,其中该计算终端在每次发送数据给该可编程交换机时开启一个定时器,并在接收到该可编程交换机返回的确认数据包时关闭定时器;如果定时器计数超出阈值后依然没有接收到确认数据包,则该计算终端发送端超时重发数据包;
9、该可编程交换机接收并判断该超时重发数据包是否已经接收过,若是,则该可编程交换机重新发送上一轮的聚合结果,否则根据该超时重发数据包内容执行网内聚合操作。
10、所述的基于可编程交换机的分布式图计算网内聚合方法,其中该步骤2包括计算终端将其下一个要聚合的图节点id发送至该可编程交换机;该步骤4包括可编程交换机根据接收的所有计算终端传来的下一个要聚合的图节点id的最小值,作为下一轮要聚合的图节点id。
11、本发明还提出了一种基于可编程交换机的分布式图计算网内聚合系统,其中包括:
12、模块1,用于获取包含多个图节点的图计算任务,将图计算任务中各图节点计算任务对应划分给分布式图计算系统的计算终端;在该分布式图计算系统内可编程交换机维护一个next[]数组,其大小为该分布式图计算系统中计算终端总数,next[]数组用于记载计算终端需要聚合的图节点id作为当前待聚合id;
13、模块2,用于计算终端判断该当前待聚合id是否为计算终端本地需要聚合的节点id,若是则将其负责的当前待聚合id上的消息发送到该可编程交换机;
14、模块3,用于使该可编程交换机收到来自各计算终端的当前待聚合id上的信息,执行网内聚合操作,得到当前待聚合id的聚合结果,将该聚合结果发送给与其对应的计算终端;
15、模块4,用于使该可编程交换机维护next[]数组,使next[i]指向下一轮要聚合的图节点id作为该当前待聚合id,并将该当前待聚合id发送给所有计算终端,再次调用该模块2,直到该图计算任务中最后一个图节点的网内聚合完成,将最后一个图节点的聚合结果发送给与其对应的计算终端,得到图计算任务的计算结果。
16、所述的基于可编程交换机的分布式图计算网内聚合系统,其中该可编程交换机按照图节点id从小到大的顺序进行网内聚合,以确保该可编程交换机每次下发聚合结果数据包中的next_id递增。
17、所述的基于可编程交换机的分布式图计算网内聚合系统,其中该计算终端在每次发送数据给该可编程交换机时开启一个定时器,并在接收到该可编程交换机返回的确认数据包时关闭定时器;如果定时器计数超出阈值后依然没有接收到确认数据包,则该计算终端发送端超时重发数据包;
18、该可编程交换机接收并判断该超时重发数据包是否已经接收过,若是,则该可编程交换机重新发送上一轮的聚合结果,否则根据该超时重发数据包内容执行网内聚合操作。
19、所述的基于可编程交换机的分布式图计算网内聚合系统,其中该模块2用于计算终端将其下一个要聚合的图节点id发送至该可编程交换机;该模块4用于使可编程交换机根据接收的所有计算终端传来的下一个要聚合的图节点id的最小值,作为下一轮要聚合的图节点id。
20、本发明还提出了一种存储介质,用于存储执行所述任意一种基于可编程交换机的分布式图计算网内聚合方法的程序。
21、本发明还提出了一种客户端,用于任意一种基于可编程交换机的分布式图计算网内聚合系统。
22、由以上方案可知,本发明的优点在于:
23、我们搭建如图12所示的包含四个计算节点的星型拓扑网络。在wiki-vote/email-enron/cit-hepth三个真实数据集上测试pagerank(最短路径算法)/sssp(单源最短路径)/cc(连同分量)三种算法。
24、总体效果:
25、(1)准确性
26、为了验证我们提出的在网聚合算法的准确性,这里选择了三个测量结果与原gemini系统进行比较,它们分别是max节点id、max节点权重和所有节点的权重和。max节点为pagerank算法收敛后权重最大的节点,用以代表图中单个节点的误差情况。所有节点的权重和则用于分析在网聚合算法的整体计算误差。
27、从实验结果看,在三个数据集上,max节点的权重在wiki-vote和cit-hepth数据集上的相对误差绝对值在0.1%以内,在email-enron数据集上,由于误差叠加的放大,相对误差绝对值在1.1%以内。且max节点都判断正确,说明在网聚合算法能够确保pagerank算法得到节点权重顺序的准确性。引入更多节点后,所有节点的权重和相对误差绝对值在三个数据集上都在0.01%以内,符合缩放因子对实验结果影响的预期。
28、
29、(2)高效性
30、图2为第一个图展示了网内图状态聚合算法(srins)成功卸载了计算终端上的负载,将聚合任务卸载到可编程交换机上进行。同时由于释放了计算终端计算资源,加速了其中的计算过程。
31、图3展示了使用网内图状态聚合算法后,边计算时间平均下降了27.7%。
32、图4展示将聚合任务按照block进行划分后,单次传输能够完成block大小的聚合任务,边计算时间随着block的大小增加而减小,网内聚合效率提升。
33、(3)可靠性
34、如图5,在非理想网络条件下,我们重复了之前的准确性实验,可以看到计算结果在误差允许的范围内,验证了可靠性算法的准确性。我们也验证了不同丢包率(0.01%-1%)条件下的计算效率。
35、
- 还没有人留言评论。精彩留言会获得点赞!