面向异构车辆的量子集体学习车辆选择和资源分配方法及系统
本发明涉及车联网和量子集体学习,更具体涉及一种面向异构车辆的量子集体学习车辆选择和资源分配方法及系统。
背景技术:
1、随着通信和计算技术的快速发展,近来,车联网(internet of vehicles,iov)、联网和自动驾驶汽车(connected and autonomous vehicle,cav)和自动驾驶已经成为研究热点。cav依靠人工智能、视觉计算、雷达、监控装置和gps协同合作,从传感器收集数据并通过人工智能(ai)技术建模来感知环境,让电脑可以在没有任何人类主动的操作下,自动安全地操作机动车辆,提高交通系统的运输效率。因此,ai模型的准确性和效率对于cav自动做出决策至关重要。从技术层面,自动驾驶的实现路线可分为单车智能自动驾驶与网联智能自动驾驶。
2、单车智能自动驾驶依靠车辆自身传感器进行环境感知,并通过ai模型进行计算决策和控制执行,给现有车载设备的通信能力和计算能力带来了很大的挑战。目前,基于网联智能自动驾驶,应用集体学习,cav可以弥补单车有限的观察和计算能力。集体学习是一种分布式训练范式,通过在智能体之间共享智能资源,可以在保证隐私的前提下弥补单个智能体的经验和计算资源不足。在集体学习中,多个cav参与者可以通过彼此共享智能资源来提高ai模型的泛化能力。由于不同cav拥有不同的智能资源、面临不同的信道状态,因此,如何选择合适的车辆参与集体学习至关重要,并且如何在cav间分配有限的频谱资源对系统性能影响很大。
3、现有方案往往采用集中式的参与车辆选择算法,此类算法首先构建系统整体的效用函数,并以该整体效用函数作为优化目标,实现集体学习中的车辆匹配。由于此类算法的优化目标是整体效用函数,而系统整体效用的最大化并不意味着每个车辆的效用最优,因此基于集中式的参与车辆选择算法得到的车辆选择结果不稳定,并且,现有的集中式的参与车辆选择算法并未给出频谱资源分配方案。
4、目前,现有方案往往采用基于传统强化学习的频谱资源分配算法,这类算法频谱资源分配问题的状态空间、动作空间会随着车联网络的规模增长以指数级速度增长,在状态空间和动作空间很大的情况下,算法的收敛速度很慢。因此,基于传统强化学习的频谱资源分配算法难以适应大规模车联网络。再次,基于传统的强化学习频谱资源分配算法必须为每个状态-动作对存储完整的q表,而这些表难以在移动设备上维护;此外,基于传统强化学习的频谱资源分配算法往往采用ε-greedy方法来平衡开发和探索,而该方法的参数在实际中难以设置。
5、因此,如何快速、稳定地实现异构集体学习的车辆选择和频谱资源分配,是一个有待解决的问题。
技术实现思路
1、有鉴于此,本发明提出了一种面向异构车辆的量子集体学习车辆选择和资源分配方法及装置,以解决现有技术中存在的至少一个技术问题。
2、本发明的一个方面提供了一种面向异构车辆的量子集体学习车辆选择和资源分配方法,该方法包括以下步骤:
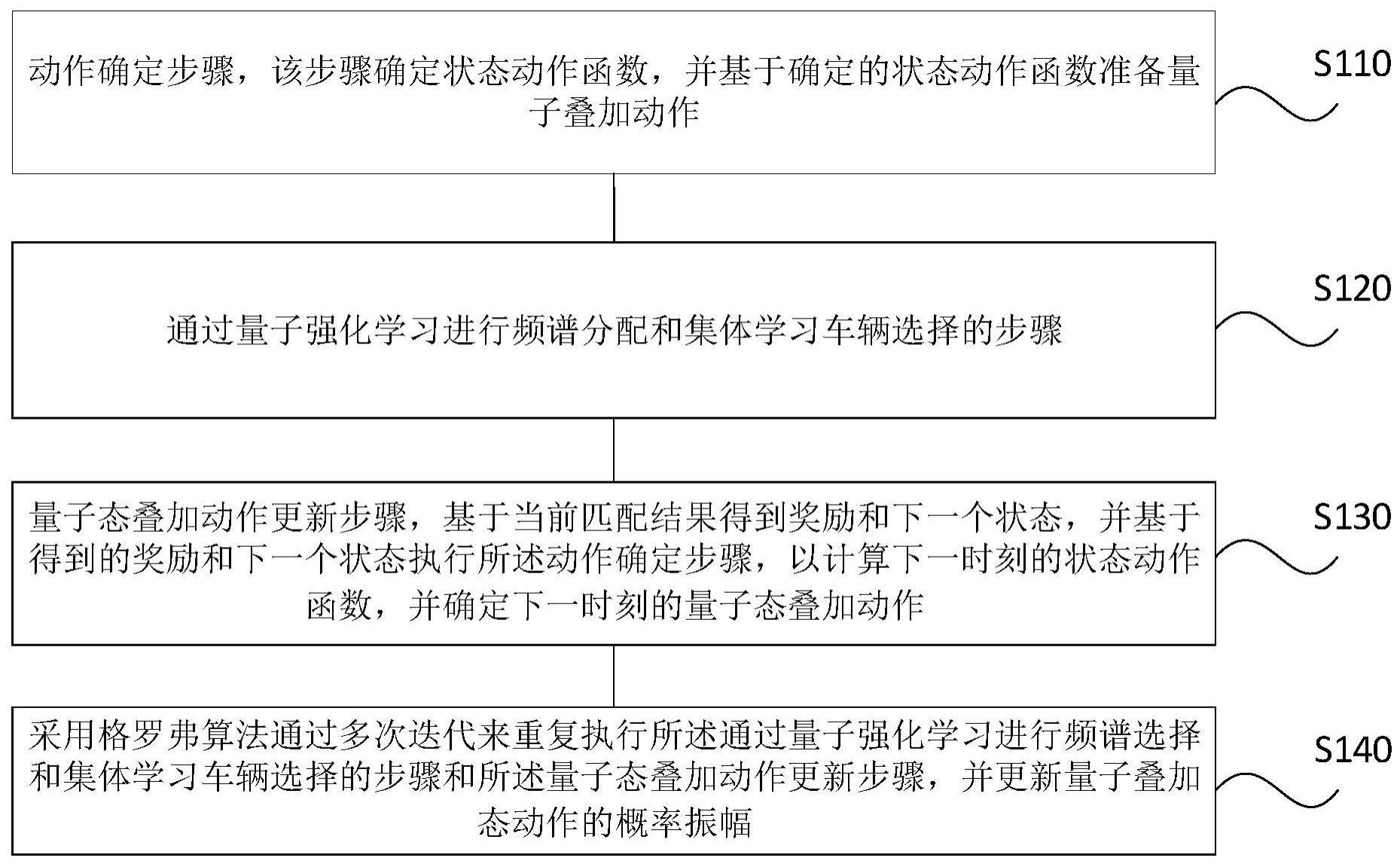
3、动作确定步骤,该步骤确定状态动作函数,并基于确定的状态动作函数制备量子叠加动作;
4、通过量子强化学习进行频谱分配和集体学习车辆选择的步骤,包括:
5、带宽分配步骤,基于当前状态和制备的量子叠加动作按照概率从动作空间选择要执行的动作进行执行,为每个参与车辆分配带宽,所述动作空间内的每个动作表示为参与集体学习的每个参与车辆分配频谱资源,所述参与车辆包括主参与车辆和从参与车辆;
6、集体学习效用计算步骤,计算参与集体学习的主参与车辆和从参与车辆的集合中各主参与车辆与从参与车辆的集体学习效用;
7、车辆选择步骤,基于计算的集体学习效用得到异构车辆偏好列表,所述异构车辆偏好列表包括各主参与车辆的偏好列表和各从参与车辆的偏好列表,并向主参与车辆和从参与车辆分别发送对应主参与车辆的偏好列表和对应从参与车辆的偏好列表,以使得主参与车辆基于接收到的偏好列表向候选的从参与车辆发送匹配请求,以由接收到所述匹配请求的从参与车辆基于其接收的偏好列表和已达到的配额确定是否选择所述主参与车辆,并向主参与车辆和路侧单元发送选择结果;
8、重复执行所述带宽分配步骤、集体学习效用计算步骤和车辆选择步骤,直至从参与车辆接受了预设的最大数量的主参与车辆之后,由路侧单元基于各从参与车辆的选择结果确定主参与车辆与从参与车辆的匹配结果;
9、量子态叠加动作更新步骤,基于当前匹配结果得到奖励和下一个状态,并基于得到的奖励和下一个状态执行所述动作确定步骤,以计算下一时刻的状态动作函数,并确定下一时刻的量子态叠加动作,其中,所述下一个状态来自状态空间,所述状态空间由多元组来表示,所述多元组中的元素包括:每一集体学习参与车辆的特征空间指示信息、时变信道质量、每个从参与车辆的计算能力和每个从参与车辆的可用能量;
10、采用格罗弗算法通过多次迭代来重复执行所述通过量子强化学习进行频谱选择和集体学习车辆选择的步骤和所述量子态叠加动作更新步骤,并更新量子叠加态动作的概率振幅。
11、在本发明的一些实施例中,所述集体学习效用计算步骤包括:基于如下公式来计算参与集体学习的主参与车辆和从参与车辆的集合中各主参与车辆与从参与车辆的集体学习效用:
12、
13、
14、其中,表示主参与车辆u的集体学习效用,tru,v表示主参与车辆u对从参与车辆v的信任度,fdu,v表示主参与车辆u和从参与车辆v间传输的智能质量,τu,v表示主参与车辆u和从参与车辆v间总时延,表示tτ时刻从参与车辆v参与主参与车辆u的集体学习过程的信任度,表示从参与车辆v的集体学习效用,ηu,v表示从参与车辆v参与集体学习的总能量消耗,αm,βm,αs,βs为权重。
15、在本发明一些实施例中,主参与车辆和从参与车辆间总时延包括主参与车辆和从参与车辆之间的总传输时延以及主参与车辆和从参与车辆参与训练期间的总训练时延。
16、在本发明一些实施例中,从参与车辆v参与集体学习的总能量消耗基于以下公式来计算:
17、
18、其中,是从参与车辆v与主参与车辆u以及路侧单元间的传输产生的能量消耗;是指从参与车辆v计算本地参数时产生的能量消耗。
19、在本发明一些实施例中,计算奖励时的约束条件包括:
20、所述主参与车辆不作为从参与车辆帮助其他参与车辆进行集体学习;
21、协助每个主参与车辆集体学习的从参与车辆的数量不超过预设的第一阈值,每个从参与车辆可以协助的主参与车辆的数量不超过预设的第二阈值;
22、主参与车辆和从参与车辆间的总时延不超过最大时延容忍量;以及
23、每个从参与车辆参与集体学习的总能量消耗不超过预设的最大能量消耗值。
24、在本发明一些实施例中,所述奖励是基于全局效用的最大化来基于集体学习对特征空间的扩大程度、集体学习的时延指标和从参与车辆参与集体学习的总能量消耗计算得到。
25、在本发明一些实施例中,所述采用格罗弗算法进行多次迭代的迭代次数由奖励和当前时刻的状态动作函数确定。
26、在本发明一些实施例中,所述由接收到所述匹配请求的从参与车辆基于其接收的偏好列表和已达到的配额确定是否选择所述主参与车辆,包括:如果接收到所述匹配请求的从参与车辆当前达到的匹配车辆数未达到配额,且发送匹配请求的主参与车辆在所述从参与车辆的偏好列表中,则会接受所述匹配请求;如果接收到所述匹配请求的从参与车辆当前达到的匹配车辆数已达到配额,则拒绝所述匹配请求。
27、本发明的另一方面提供了一种面向异构车辆的量子集体学习车辆选择和资源分配系统,该系统包括:处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该系统实现如前所述方法的步骤。
28、本发明的另一方面还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如前所述方法的步骤。
29、本发明的面向异构车辆的量子集体学习车辆选择和资源分配方法和系统,能够快速、稳定地实现异构集体学习的车辆选择和频谱资源分配,并且可以最大化全局效用,提高了ai模型的准确性和泛化能力。
30、本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
31、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
- 还没有人留言评论。精彩留言会获得点赞!