一种三维视频帧内深度图编码单元划分方法及装置与流程
本发明属于基于神经网络的视频编码,具体涉及一种三维视频帧内深度图编码单元划分方法及装置。
背景技术:
1、近年来,随着三维(three dimensional,3d)视频服务的快速发展,3d视频进入千家万户。3d视频提供了一种立体沉浸式的观看体验,通过3d眼镜将不同的视频呈现给观看者,来实现3d场景感知。同时,3d视频也给视频编码技术提出了更高的要求。为了应对这一挑战,国际联合视频编码小组(the joint collaborative team on video coding,jct-vc)开发了三维高效视频编码标准(3d-high efficiency video coding,3d-hevc)。3d-hevc一般包含2~3个视点,每个视点都有一个纹理图(texture map)和一个对应的深度图(depth map)。深度图是由灰度图像表示,它捕获了摄像机与实际物体之间的距离,能够利用基于深度图的虚拟视点合成技术(depth-image-based rendereing,dibr)合成虚拟图像。不同于纹理图,深度图存在大量的平坦区域以及十分陡峭的边界,为区别于纹理图的特征,3d-hevc提供了众多复杂的深度图编码技术,导致3d-hevc编码复杂度提升。
2、帧内预测是视频编码标准hevc/av1/avs中最核心的组成部分。在3d-hevc深度图帧内编码中采用的hevc中基于四叉树的编码树单元结构。编码树单元是一个基本单元,它被分成若干个编码单元,这些编码单元可以用递归的四叉树结构表示。这些编码单元可以表示为64×64(dl=0)到8×8(dl=3)的不同正方形大小或深度级别(dl)。3d-hevc测试模型(htm)将视频序列的每一帧分割成最大编码单元(64×64),然后利用递归的方式将每一层的编码单元分区成4个子单元,直至dl为3。为了决定出当前编码树单元最优的分区结构,从根节点开始,需要比较未分割的编码单元率失真代价和分割成4个编码单元后的率失真代价总和,如果率失真代价中,“rd-cost(dl=n)>rd-cost(dl=n+1),n=0,1,2”,则“深度=n”的编码单元需要分割成4个子编码单元,反之则终止分割。这将造成深度图编码复杂度的大量增长,因此,有必要降低3d-hevc中深度图编码单元分区的复杂度。
技术实现思路
1、为解决现有技术的不足,实现提升视频编码中帧内预测编码效率的目的,本发明采用如下的技术方案:
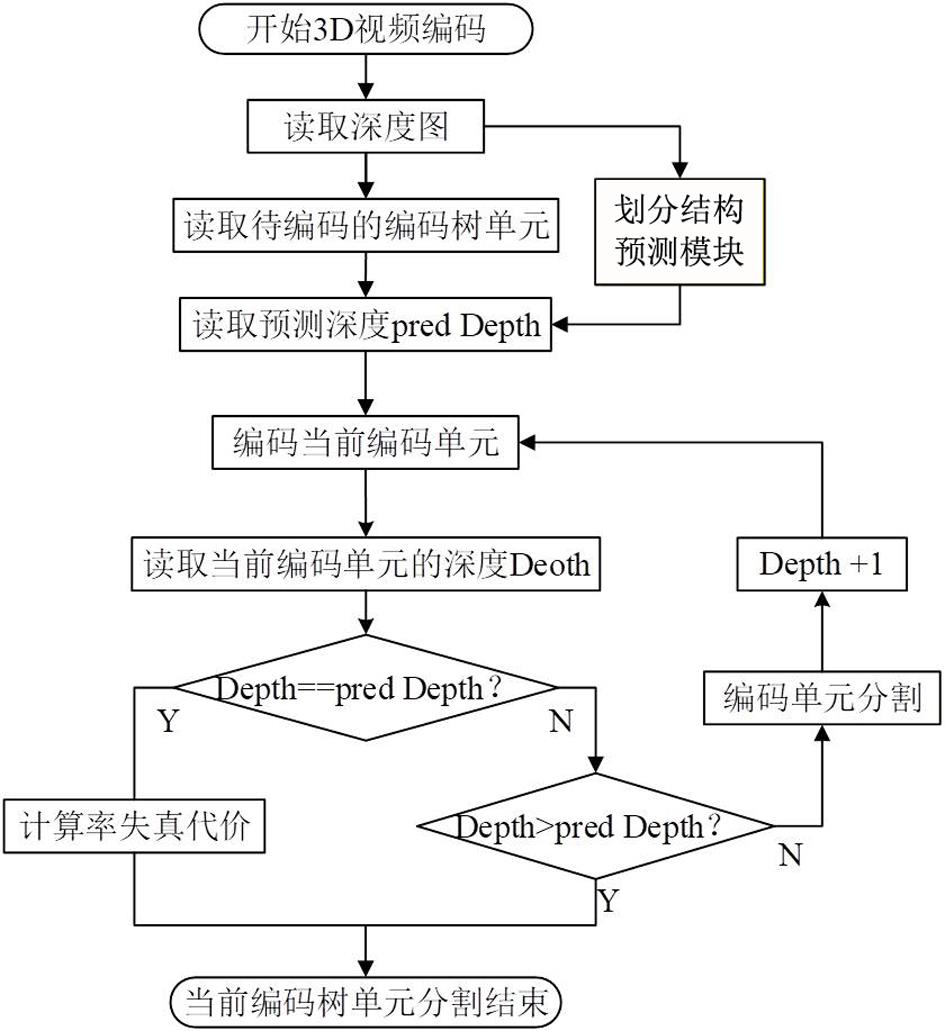
2、一种深度图编码单元划分方法,包括如下步骤:
3、步骤s1:构建划分结构预测网络,对深度图编码单元进行分区预测;
4、步骤s2:获取待划分的深度图编码单元,通过划分结构预测网络,得到预测的最优划分结构,比较深度图编码单元的当前深度与预测的最优划分结构的深度,当深度相同时,对当前深度图编码单元的率失真代价进行计算,否则,不进行计算,基于计算的率失真代价,确定当前深度图编码单元的最优划分结构。
5、进一步地,所述步骤s2中,若当前深度小于预测深度,则跳过当前深度的率失真代价计算,继续进行下一深度的搜索;若当前深度大于预测深度,则跳过当前深度的率失真代价计算的同时,停止进一步的深度搜索,完成当前深度图编码单元划分。
6、进一步地,所述步骤s1包括如下步骤:
7、步骤s1.1:特征提取,获取深度图编码单元原始像素灰度图并进行分块,对每个像素的通道数据进行线性变换,然后通过swin transformer移位窗口变换器提取特征,基于特征对应的分块进行合并,得到第一特征;对深度图编码单元原始像素灰度图基于卷积组进行特征提取,得到第二特征;将第一特征与第二特征进行融合;
8、步骤s1.2:将融合的特征进行分区预测,得到预测的分区图。
9、swin transformer移位窗口变换器通过多层自注意力机制和前馈神经网络层,能够在输入特征图中捕捉全局和局部的上下文信息,从而有效地提取深度图中的边缘信息,以便在后续的步骤中进行更精确的预测。
10、进一步地,所述步骤s1中,构建多尺度l1损失函数ms-l1,用于划分结构预测的训练,预测出的分区图像素在0-3之间:
11、
12、
13、其中,maxpoolk=i和minpoolk=i分别表示内核大小为i的最大池化和最小池化,y表示网络输出和训练的划分结果,表示真实的划分结果,由于深度图具有局部一致性的特点,最大和最小池化的目的是为了加强本地一致性,对l1进行了定义,ak=i、bk=i分别表示l1损失函数中对应的maxpoolk=i(y)、或minpoolk=i(y)、
14、一种三维视频帧内深度图编码单元划分方法,基于所述的一种深度图编码单元划分方法,其中所述步骤s2包括如下步骤:
15、步骤s2.1:基于预编码通测标准提供的视频序列,提取深度图编码单元和最优划分结构作为训练数据,用于训练所述划分结构预测网络;
16、步骤s2.2:从深度图视频中逐帧读取需要编码的深度图,将其划分为深度图编码单元,并通过训练好的划分结构预测网络,得到预测的最优划分结构;
17、步骤s2.3:从深度图中获取待编码的深度图编码单元及其预测的最优划分结构的深度,比较深度图编码单元的当前深度与预测的最优划分结构的深度,当深度相同时,对当前深度图编码单元的率失真代价进行计算,否则,不进行计算;
18、步骤s2.4:基于计算的率失真代价,得到当前深度图编码单元的最优划分结构,返回步骤s2.3,直至得到所有深度图视频对应的深度图编码单元最优划分结构。
19、进一步地,所述步骤s2.3中,若当前深度小于预测深度,则跳过当前深度的率失真代价计算,继续进行下一深度的搜索;若当前深度大于预测深度,则跳过当前深度的率失真代价计算的同时,停止进一步的深度搜索,完成当前深度图编码单元划分。
20、一种三维视频帧内深度图编码单元划分装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现所述一种三维视频帧内深度图编码单元划分方法。
21、一种深度图编码单元划分装置,包括划分结构预测模块和最优划分结构生成模块;
22、所述划分结构预测模块,用于对深度图编码单元进行分区预测;
23、所述最优划分结构生成模块,获取待划分的深度图编码单元,通过划分结构预测模块,得到预测的最优划分结构,比较深度图编码单元的当前深度与预测的最优划分结构的深度,当深度相同时,对当前深度图编码单元的率失真代价进行计算,否则,不进行计算,基于计算的率失真代价,确定当前深度图编码单元的最优划分结构。
24、进一步地,所述最优划分结构生成模块中,若当前深度小于预测深度,则跳过当前深度的率失真代价计算,继续进行下一深度的搜索;若当前深度大于预测深度,则跳过当前深度的率失真代价计算的同时,停止进一步的深度搜索,完成当前深度图编码单元划分。
25、进一步地,所述划分结构预测模块包括特征提取模块、融合模块、分区预测模块,特征提取模块包括第一特征提取分支和第二特征提取分支,第一特征提取分支包括依次连接的分块层、线性变换层、swin transformer移位窗口变换器,第二特征提取分支包括依次连接的卷积层、归一化层、激活层和池化层,融合模块对两个分支提取的特征进行融合,用于分区预测模块对划分结构的预测。所述swin transformer移位窗口变换器提取的特征,通过卷积层进行降维,以减少计算复杂度。
26、swin transformer移位窗口变换器通过多层自注意力机制和前馈神经网络层,能够在输入特征图中捕捉全局和局部的上下文信息,从而有效地提取深度图中的边缘信息,以便在后续的步骤中进行更精确的预测;通过卷积操作对深度图进行滤波和下采样,同时通过bn层进行归一化操作,relu激活层进行非线性激活以及池化层进行空间降维,这些组件在处理深度图编码树单元时可以提取边缘特征信息;最后,通过这两个分支的组合,网络可以获得丰富的特征信息。
27、本发明的优势和有益效果在于:
28、本发明的一种三维视频帧内深度图编码单元划分方法及装置,在3d视频深度图帧内预测中,利用基于swin transformer的网络模块预测深度图编码树单元的最优划分结构,以跳过冗余的率失真代价计算,在保证编码质量基本不变的情况下,大幅降低了3d-hevc帧内深度图编码时间,降低3d-hevc编码复杂度,提升视频编码中帧内预测编码效率。
- 还没有人留言评论。精彩留言会获得点赞!