IP特征库生成方法与流程
本发明涉及网络,尤其是ip特征库生成方法。
背景技术:
1、随着互联网的快速发展,互联网的应用发生了翻天覆地的变化,从最初的网页浏览、email、ftp下载,到现在的p2p应用、游戏、视频、移动互联,丰富多彩的应用成为互联网的主流。
2、在局域网中,基于应用识别来进行局域网监管是至关重要的。
3、当前的应用识别技术主要是通过域名进行识别,在识别域名时可以通过识别dst_ip实际访问的域名server_name来实现,或将dns域名解析后,对相应的dst_ip进行识别来实现。
4、但在应用产生的流量中存在大量dst_ip无对应的server_name以及不通过dns(域名系统)域名请求进行dst_ip访问,而是直接访问某dst_ip的情况。
5、这就造成人工提取dst_ip时,难以辨别这些dst_ip归属何种应用,进而导致人工提取与应用相关的dst_ip存在较大难度。
技术实现思路
1、本发明的目的就是为了解决现有技术中存在的上述问题,提供一种ip特征库生成方法。
2、本发明的目的通过以下技术方案来实现:
3、ip特征库生成方法,包括如下步骤:
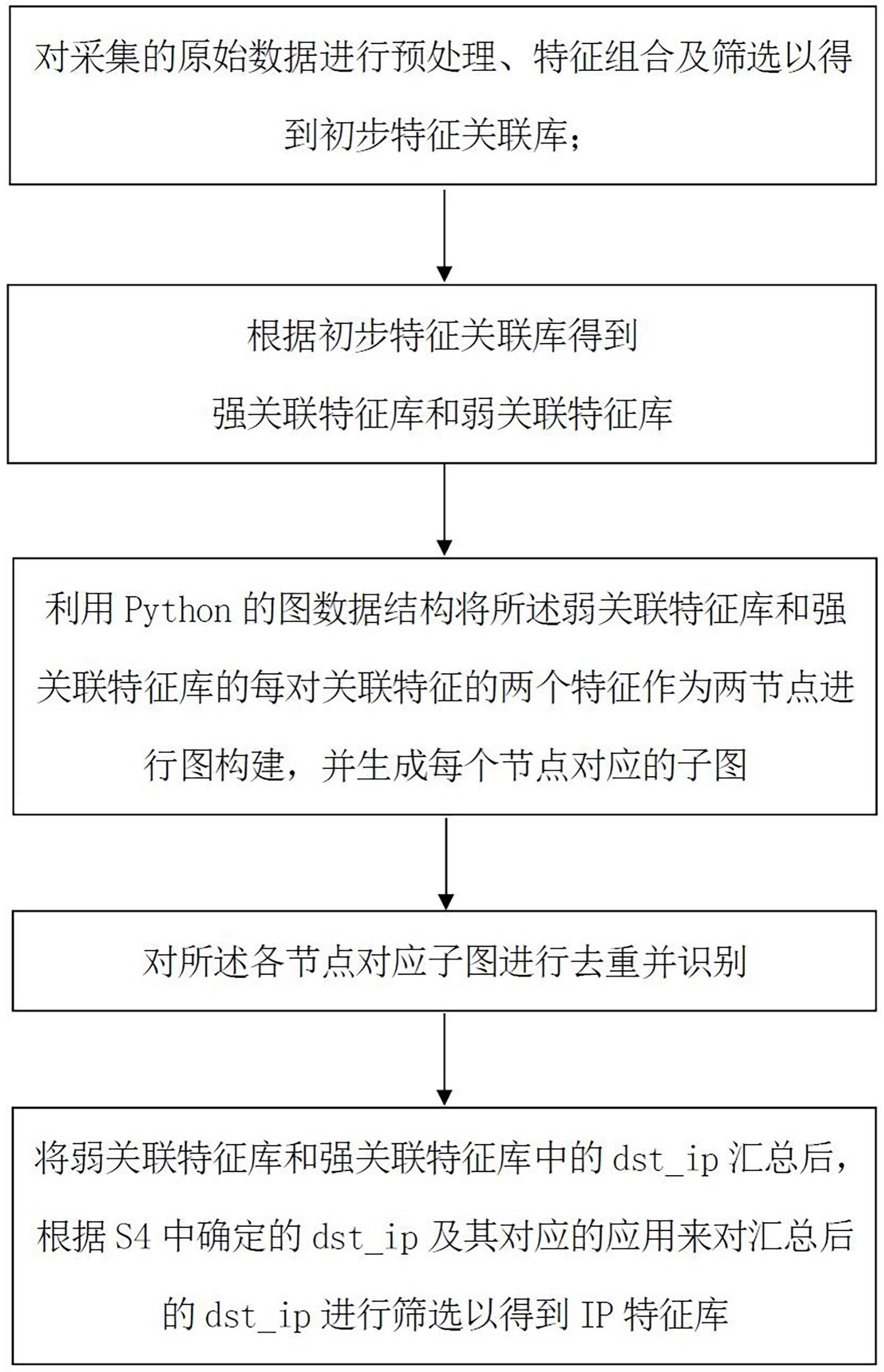
4、s1,对采集的原始数据进行预处理、特征组合及筛选以得到初步特征关联库;
5、s2,根据初步特征关联库得到强关联特征库和弱关联特征库;
6、s3,以所述弱关联特征库和强关联特征库的每对关联特征的两个特征作为两节点进行图构建,并生成每个节点对应的子图;
7、s4,对各节点对应子图进行去重并识别;
8、s5,将弱关联特征库和强关联特征库中的dst_ip汇总后,根据s4确定的dst_ip及其对应的应用来对汇总后的dst_ip进行筛选以得到ip特征库。
9、优选的,所述s1包括如下步骤:
10、s11,对原始数据进行清洗过滤;
11、s12, 对清洗过滤后的数据按时间分割成多个时间段的数据;
12、s13,将同一设备下产生的数据中的特征两两组合得到一组特征组合;
13、s14,确定每个所述特征组合对应的命中次数,所述命中次数是所述特征组合的两个特征出现在同一时间段的次数;
14、s15,根据s14的结果确定与每个特征cn相关的两个相关特征,将每个特征cn及其相关特征的数据存储得到初步特征关联库。
15、优选的,在所述s14之后,s15之前,将低于动态筛选条件的命中次数对应的特征组合的数据过滤掉,所述动态筛选条件是所有所述命中次数的平均数、中位数或分位数中的至少一个。
16、优选的,所述s15中,两个相关特征与所述特征cn构成的两个特征组合对应的命中次数是包括所述特征cn的所有特征组合对应的命中次数中最大的两个。
17、优选的,所述s15中,两个相关特征中,一者与所述特征cn构成的特征组合对应的命中次数大于所有命中次数的中位数,另一者与所述特征cn构成的特征组合对应的命中次数大于所有命中次数的四分位数。
18、优选的,所述s2包括如下步骤:
19、s21,根据初步特征关联库的数据确定附加特征;
20、s22,根据附加特征对初步特征关联库的数据进行过滤;
21、s23,根据所述附加特征将经过s22的初步特征关联库的数据划分为弱关联特征库和强关联特征库。
22、优选的,所述s21中,所述附加特征包括:
23、relation_prio,其表示一对关联特征是否为server_name与其对应的dst_ip,若是,则relation_prio为1,若否,则relation_prio为00;
24、node_count,其表示该对关联特征中的预定特征出现在不同设备的个数;
25、node_relation_count,其表示该对关联特征出现在不同设备的个数;
26、hit_rate=node_relation_count/node_count。
27、优选的,所述s22中,将node_relation_count小于5的每对关联特征的数据清除和/或将hit_rate小于整体hit_rate标准差的每对关联特征的数据清除。
28、优选的,所述s23中,将relation_prio为0的每对关联特征标记为弱关联特征并存入到弱关联特征库;将relation_prio为1的每对关联特征标记为强关联特征并存入到强关联特征库。
29、优选的,所述s4中,根据如下原则对去重后的每个子图进行识别:
30、当子图中的特征全为server_name时,丢弃该子图;
31、当子图中的特征有server_name和dst_ip时,通过域名识别确定server_name对应的应用,若其中全部server_name识别出的应用为同一款,则将对应的dst_ip归入该应用;反之,丢弃该子图;
32、当子图中的特征全为dst_ip时,将每个子图按序号进行标记。
33、优选的,所述s5中,将强关联特征库和弱关联特征库的所有dst_ip进行汇总形成ip特征库;
34、根据s4中确定的dst_ip及其对应的应用来对汇总后的dst_ip进行筛选;
35、若同一dst_ip识别出的应用相同,则将该dst_ip保留在ip特征库中并将该dst_ip对应的应用的特征字段存储在ip特征库中;
36、若同一dst_ip识别出的应用不同,则根据以下原则进行筛选:
37、若所述同一dst_ip均属于强关联特征库或均属于弱关联特征库,则丢弃ip特征库中的所述dst_ip;
38、若所述同一dst_ip中的部分属于强关联特征库,部分属于弱关联特征库,则将属于强关联特征库的所述dst_ip保留在ip特征库中并将所述dst_ip对应的应用的特征字段存储在ip特征库中,删除ip特征库中属于弱关联特征库的所述dst_ip。
39、本发明技术方案的优点主要体现在:
40、本发明的ip特征库生成方法是基于用户访问应用的行为,根据数据统计的原则及图分类的方法将dst_ip识别为某个应用,能够将无对应server_name以及不通过dns域名请求进行dst_ip访问的dst_ip识别到一个具体应用,使得人工难以进行特征提取的dst_ip也能够进行应用标签建立,提高了局域网内的应用识别能力,大大提高了识别率。
41、本发明通过对数据进行多次筛选,能够有效地去除活跃度较低的数据,从而提高数据的可信度,有利于提高最终生成的ip特征库的数据精度。
42、本发明的方法可调整数据筛选参数,识别逻辑灵活。
技术特征:
1.ip特征库生成方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的ip特征库生成方法,其特征在于,所述s1包括如下步骤:
3.根据权利要求2所述的ip特征库生成方法,其特征在于,在所述s14之后,s15之前,将低于动态筛选条件的命中次数对应的特征组合的数据过滤掉,所述动态筛选条件是所有所述命中次数的平均数、中位数或分位数中的至少一个。
4.根据权利要求2所述的ip特征库生成方法,其特征在于:所述s15中,两个相关特征与所述特征cn构成的两个特征组合对应的命中次数是包括所述特征cn的所有特征组合对应的命中次数中最大的两个。
5.根据权利要求2所述的ip特征库生成方法,其特征在于:所述s15中,两个相关特征中,一者与所述特征cn构成的特征组合对应的命中次数大于所有命中次数的中位数,另一者与所述特征cn构成的特征组合对应的命中次数大于所有命中次数的四分位数。
6.根据权利要求1所述的ip特征库生成方法,其特征在于,所述s2包括如下步骤:
7.根据权利要求6所述的ip特征库生成方法,其特征在于,所述s21中,所述附加特征包括:
8.根据权利要求7所述的ip特征库生成方法,其特征在于,所述s22中,将node_relation_count小于5的每对关联特征的数据清除和/或将hit_rate小于整体hit_rate标准差的每对关联特征的数据清除。
9.根据权利要求7所述的ip特征库生成方法,其特征在于,所述s23中,将relation_prio为0的每对关联特征标记为弱关联特征并存入到弱关联特征库;将relation_prio为1的每对关联特征标记为强关联特征并存入到强关联特征库。
10.根据权利要求1所述的ip特征库生成方法,其特征在于,所述s4中,根据如下原则对去重后的每个子图进行识别:
11.根据权利要求1-10任一所述的ip特征库生成方法,其特征在于,所述s5中,将强关联特征库和弱关联特征库的所有dst_ip进行汇总形成ip特征库;
技术总结
本发明揭示了IP特征库生成方法,先根据原始数据处理得到初步特征关联库;然后,根据初步特征关联库得到强关联特征库和弱关联特征库;随后,以所述弱关联特征库和强关联特征库的每对关联特征的两个特征作为两节点进行图构建,并生成每个节点对应的子图;接着,对各节点对应子图进行去重并识别;最后,将弱关联特征库和强关联特征库中的dst_ip汇总后,根据确定的dst_ip及其对应的应用来对汇总后的dst_ip进行筛选以得到IP特征库。本发明基于数据统计的原则及图分类的方法,使得人工难以进行特征提取的dst_ip进行应用标签建立,提高了局域网内的应用识别能力。
技术研发人员:陈立,王东泉,张俊安,路皓天
受保护的技术使用者:苏州迈科网络安全技术股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!