一种车联网络中多维资源协同管理方法
本技术涉及无线通信,特别是涉及一种车联网络中多维资源协同管理方法。
背景技术:
1、受益于通信感知一体化(integrated sensing and communication,isac)技术使能的网络系统具有结构简化、高干扰抑制、低资源消耗等多种优点,有望成为下一代无线通信网络。在车辆网络(vehicle networks,vnets)中,已经有相应的isac支持的设计可以缓解vnets快速增长的频谱需求,并提供可靠的感知能力。然而,在复杂的城市街道场景中,车辆的感知范围和可靠性限制了全自动驾驶的发展。此外,在目前的研究中,启用isac的正交频分复用(orthogonal frequency division multiplexing,ofdm)雷达的感知范围在60米左右,其感知和通信能力受到其自身机载芯片的处理能力的限制。
2、为了克服分离感知的缺点,协同感知(也被称为分布式感知)最近引起了学术界和产业界的广泛关注。除了利用自感知信息外,协同感知技术通过车用无线通信技术(vehicle-to-everything,v2x)收集附近车辆和路侧单元的感知信息,并提供更广泛的道路环境的全局视图。为了充分利用vnets中广泛存在的计算和存储资源,学术界提出了基于雾的车辆网络(fog-based vehicle networks,车联网络),以有效利用这些层次资源,为协同感知提供低时延的计算结果。此外,国际标准化机构目前也正在通过正式定义其使用场景和相关信息的生成规则来加速协同感知技术的实现。
3、尽管存在上述优点,协同感知仍然面临着一个关键的挑战,即同时交换大容量感知数据可能会使现有的无线频谱和计算资源有限的车联网络不堪重负。此外,现有车辆大多设计为单独感知,其计算资源不支持协同感知,难以保证低时延要求。为此,亟需一种有效的协同感知方法,使得在车联网络中,通过支持isac的设计在海量的上传数据量和有限的无线频谱和计算资源之间取得平衡。
4、在现有技术中,中国发明专利申请号cn202011504314.7公开了一种基于非正交多址的车联网络中资源优化方法,基于noma的动态网络中,在noma协助的车辆边缘计算系统中对车辆任务处理时,以车辆边缘计算系统的总能耗最小化为原则,确定系统的卸载和缓存决策、计算和缓存资源的分配,以此完成车辆边缘计算系统中的资源优化问题,其特征在于,所述车辆边缘计算系统的总能耗最小化过程包括:考虑车辆用户的随机流量到达和队列稳定性,通过联合优化计算卸载决策和内容缓存决策,以及计算和缓存资源的分配,定义为一个随机优化问题;利用李雅普诺夫优化理论,提出求解该问题的动态规划问题;联合计算卸载、内容缓存和资源分配算法,将动态规划问题解耦为计算卸载子问题和内容缓存子问题;解出计算卸载子问题,得出卸载决策和计算资源分配最优解;解出内容缓存子问题,得出缓存决策和缓存资源分配最优解;
5、又例如,中国发明专利申请号cn201910178826.x公开了一种基于smdp的车联云雾系统动态资源优化管理系统,其特征在于,包括云雾一体化的车联网架构,云雾一体化的车联网架构包括中心云、雾服务层和车载云;中心云包括服务器集群,其将车联网的应用服务集中在一起,存储分析终端设备搜集的海量数据,并对车联网大数据进行分析,得到大数据分析结果,对交通信息进行管控,为车载用户提供服务;雾服务层通过接入雾设备将计算能力和数据分析能力拓展到网络边缘,使得车联网中的部分数据转移到本地进行处理,为车载用户提供服务;车载云包括车载节点以及用户移动终端,其将车辆化为不同的区域集合,同一区域集合内的车辆间通过车与车通信形成网络,共享计算存储和频谱资源;车辆终端接入网络后,迅速获取雾服务层的服务。
6、再例如,中国发明专利申请号cn201910178826.x公开了一种基于smdp的车联云雾系统动态资源优化管理系统,其特征在于,包括云雾一体化的车联网架构,云雾一体化的车联网架构包括中心云、雾服务层和车载云;中心云包括服务器集群,其将车联网的应用服务集中在一起,存储分析终端设备搜集的海量数据,并对车联网大数据进行分析,得到大数据分析结果,对交通信息进行管控,为车载用户提供服务;雾服务层通过接入雾设备将计算能力和数据分析能力拓展到网络边缘,使得车联网中的部分数据转移到本地进行处理,为车载用户提供服务;车载云包括车载节点以及用户移动终端,其将车辆化为不同的区域集合,同一区域集合内的车辆间通过车与车通信形成网络,共享计算存储和频谱资源;车辆终端接入网络后,迅速获取雾服务层的服务。
7、以上发明专利申请技术均存没有考虑车辆间的协同感知的实现,且难以满足车联网络对感知能力和时延要求。
技术实现思路
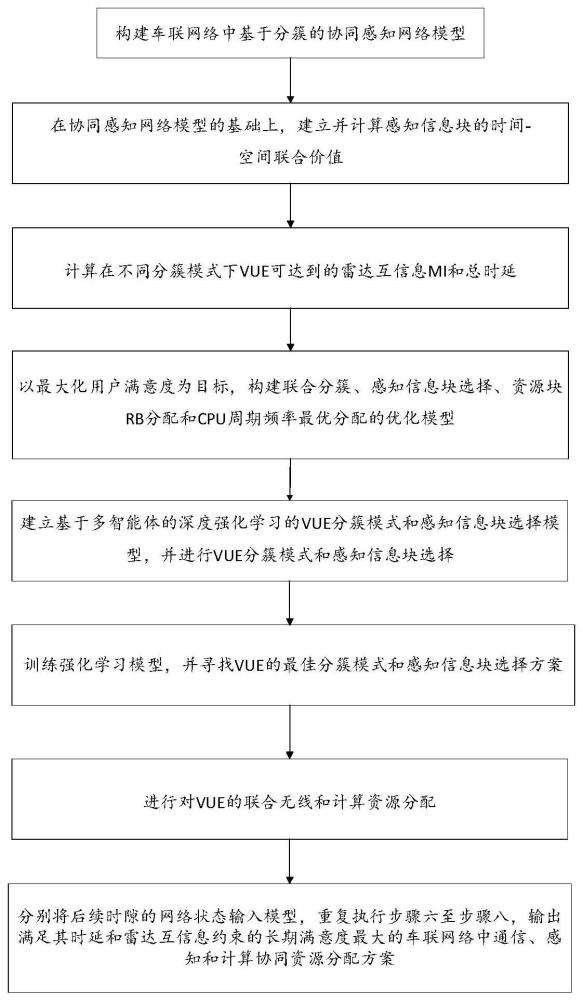
1、有鉴于此,本发明基于深度强化学习、匹配算法和凸优化理论,提供一种车联网络中多维资源协同管理方法,包括以下具体步骤:
2、步骤1,构建车联网络中基于分簇的协同感知网络模型;
3、步骤2,在协同感知网络模型的基础上,建立并计算感知信息块的时间-空间联合价值;
4、步骤3,计算在不同分簇模式下vue达到的雷达互信息mi和总时延;
5、步骤4,以最大化用户满意度为目标,构建联合分簇、感知信息块选择、资源块rb分配和cpu周期频率最优分配的优化模型;
6、步骤5,建立基于多智能体的深度强化学习的vue分簇模式和感知信息块选择模型,进行vue分簇模式和感知信息块选择;
7、步骤6,训练强化学习模型,并寻找vue的最佳分簇模式和感知信息块选择方案;
8、步骤7,进行对vue的联合无线和计算资源分配;
9、步骤8,分别将后续时隙的网络状态输入模型,重复执行步骤6至步骤8,输出满足其时延和雷达互信息约束的长期满意度最大的车联网络中通信、感知和计算协同资源分配方案。
10、进一步的,步骤1中,构建车联网络中基于分簇的协同感知网络模型,包括:
11、协同感知网络模型模型由1个云服务器、n个无线远端射频单元(remote radioheads,rrhs)和n个雾节点(fog access points,f-aps)组成,设定多个车辆用户vues(vehicle user equipment)通过rrh或雾节点与同一个雾节点服务器或云服务器关联,形成协作分簇并上传其本地感知信息块至雾节点服务器或云服务器进行协同计算,称之为一个协同感知任务tk;
12、设定vue k的连接选择为xk,n:如果xk,0=1,vue k通过rrhs与云模式关联;反之,如果xk,n=1,n∈n,vue k选择接入f-apn。
13、进一步的,步骤2中,在协同感知网络模型的基础上,建立并计算感知信息块的时间-空间联合价值,包括:
14、步骤2.1、对网络模型中每一辆vue进行感知信息块的划分:
15、采用四叉树的数据压缩技术,将道路区域划分成不同的二维区域,并将每个二维区域包含的数据压缩成独立的感知信息块,vue的四周为通过自身无线感知能力感知得到的感知信息块记做自我感知信息块,在vue期望的感知距离内,vue不同车辆间无线感知能力相互重叠的感知信息块部分为冗余块,感知信息块为边长固定的正方形二维平面,包含了当前平面内的车辆道路信息,自我感知信息块是指vue通过自身配备的isac一体化装置的感知距离内的感知信息块,期望的感知距离是长度大于vue自我感知信息块边长的长度为d的vue前部区域;
16、步骤2.2、构建感知信息块的时间-空间联合价值:
17、构建感知信息块的时间价值和空间价值,作为vue上传感知信息块的依据,时间价值和空间价值是指感知信息块在时间尺度上和空间尺度上,vue对于感知信息块的兴趣程度:感知信息块距离vue越近、感知信息块的生成时间越新鲜,则vue对其具有更大的兴趣程度,设定t时刻的时间价值公式为:
18、
19、其中,qk,b,0>0是感知信息块的初始价值,τdll是每一个感知信息块的截止时间,tk,b,0是感知信息块的产生时间;
20、设定vue k中块b的空间价值公式为:
21、
22、其中,dk,b(t)为t时刻vue k和感知信息块b之间的欧氏距离,θk,b为vue k移动方向与感知信息块b块之间的角度,为vue期望的感知距离;
23、设定vue k中块信息的时间-空间联合价值公式为:
24、
25、步骤2.3、计算感知信息块的时间-空间联合价值:
26、vue选择性上传时间-空间联合价值最大的感知信息块,每个vue周期性地选择上传时间-空间联合价值最大的自我感知信息块至其关联的雾节点服务器或云服务器,云服务器和雾节点f-ap在收到来自分簇内vue成员的上传感知信息块后,通过对收集到的感知信息块进行重新调整、整合、推断和映射,实现vue之间的协同感知。
27、进一步的,步骤3中,计算在不同分簇模式下vue可达到的雷达互信息mi和总时延:
28、步骤3.1、计算vue处的雷达信号与干扰噪声比sinrrad和可实现的雷达互信息mi,根据雷达信息估计理论建立感知模型,设定每一个vue均能够通过车载配备isac技术的发射机连续发射集成的ofdm波形来进行雷达检测,在vue k处收到的雷达信号与干扰噪声比sinrrad为:
29、
30、其中,pk和pj为vue k和其他的vue j的传输功率,这里ak,s∈{0,1}是资源块rb所有k∈k和s∈s的分配向量,gk,s(f)是gk,s(t)的傅里叶变换,在t时刻,从另一个vue j到vue k的雷达接收机的信道增益记为hj,k,s(t);在时隙t内vue k可实现的雷达互信息mi定义为:
31、
32、步骤3.2、计算vue在不同分簇模式下达到总时延,当vue选择雾节点分簇模式时,达到的通信速率公式为:
33、
34、其中,w为资源块的带宽大小,ak,s为二进制资源块分配向量,pk为vue k的发射功率,pj为与vuek占用相同资源块的vuej的发射功率,为t时刻在资源块s上从vue k到f-ap n的信道增益,为t时刻在资源块s上从其他vue j到f-ap n的信道增益;σ2为噪声功率,当vue选择云服务器分簇模式时,达到的通信速率公式为:
35、
36、其中,gk,s是最小均方误差(minimum mean square error,mmse)检测的向量,是时间t内,从vue k到其关联的rrhs m的信道增益,而是从vue j到与vue k的关联的rrhs的信道增益,在一个分簇中,vuek的通信时延为所有vue成员的上传时延中的最大时延,计算公式为:
37、
38、其中,τfh是前传时延,由实际运营商网络通信能力进行测量得到,i为每个感知信息块的数据大小,单位为bits,ek,b为vuek对感知信息块b的二进制选择变量:ek,b=1表示vuek将上传感知信息块b,反之,ek,b=0则表示vuek不会上传感知信息块b,vuek的计算时延为:
39、
40、其中,f0,max和fn,max分别为云服务器和每个雾节点服务器的最大cpu周期频率,fk,n为分配给vue k的cpu周期频率,vuek的总时延为:
41、
42、其中,和分别为本地压缩时延、通信时延和任务计算时延。
43、进一步的,步骤4中,以最大化用户满意度为目标,构建联合分簇、感知信息块选择、资源块rb分配和cpu周期频率最优分配的优化模型:
44、协同感知优化问题的表述如下:
45、
46、其中,uk(t)是满意度函数,t是总时长,ε1和ε2是满意度权重参数,以平衡感知信息的时空价值和总任务时延对满意度的影响,是最大时延容忍的阈值,mimin是最小雷达互信息容忍的阈值,约束c1是任务时延要求,由任务最大容忍时延决定,约束c2表示每个vue都应该上传不重叠的感知信息以合理利用计算资源,约束c3表示每个vue可以选择一个卸载节点,以使vue之间合理形成分簇,约束c4表示每个vue选择一个资源块rb进行上传,资源块rb能够被不同分簇中的多个vue重用,约束c5限制了雾节点f-ap和云服务器分配的cpu周期频率,约束c6是启用isac的vue的最低感知性能阈值。
47、进一步的,步骤5中,建立基于多智能体强化学习的vue分簇模式和感知信息块选择模型:
48、步骤5.1、将每个vue作为一个智能体,构建注意力辅助的多智能体ddpg算法模型,智能体k的本地状态特征矢量,定义为:
49、
50、其中,为vue k的最大容忍时延,lk为vue k的当前坐标,q′k为t-1时刻vuek的感知消息的时间值,{o′n}n∈0∪n为雾节点n和云服务器在时间t-1时的剩余计算资源,rsat′是在云服务器上用于度量前一个动作影响的前一个全局时延满足比率,智能体k的动作定义为:
51、ak=(n,ek,b),
52、其中,n表示接入的雾节点序号;
53、步骤5.2、构建每个vue的即时奖励函数,每个vue k的奖励函数,定义为:
54、
55、步骤5.3、利用智能体的状态特征矢量构建多智能体马尔可夫博弈模型的状态特征:
56、设定每个智能体马尔可夫博弈模型γ定义为:
57、
58、其中,k是智能体的数量,为状态空间,是动作空间,rk是由所有奖励智能体决定的系统即时奖励函数,γ是探索的折扣因子;
59、步骤5.4、使用多智能体ddpg模型实现智能体之间的协作,然后使用注意力机制的多层感知网络对每个智能体的评论家网络进行调整;注意力多智能体ddpg算法中的每个智能体k都有一个评论家网络负责找到基于本地观测状态的确定性策略,给定随机噪声在时间t所选择的动作ak(t)的公式定义为:
60、
61、其中,θk为行动者网络参数,sk(t)是vuek的本地观测状态,μk(sk(t);θk)是通过输入评论家网络参数θk和vuek的本地观测状态sk(t)后得到的确定性策略,每个行动者网络在梯度方向上调整网络参数θk以最大化奖励函数,公式为:
62、
63、其中,是回放缓存,用来存储所有智能体的经验元组,qk(s,a)是由注意力辅助的评论家网络建立的动作值函数;
64、建立一个多层感知网络,基于对智能体j,智能体k的观测结果,注意力权重αk,j和注意力价值vk,j的计算公式分别为:
65、
66、vk,j=h(vkej),
67、其中,wq和wk构成ek和ej的双线性映射,h(·)是一个relu函数,vk是变换矩阵,设定评论家网络通过最小化以下损失函数进行更新,公式为:
68、
69、其中,δk是评论家网络参数,(s,a,r,s′)是状态值、动作值、即时奖励和下一状态值组成的四元组,s′是下一状态值,q-(s′,a′)是由目标注意力辅助的批评家网络推断出的目标动作值函数,是目标行动者网络得到的目标动作。
70、进一步的,步骤6中,训练强化学习模型,并寻找vue的最佳分簇模式和感知信息块选择方案:
71、步骤6.1、初始化行动者网络、注意力机制评论家网络、目标行动者网络、目标评论家网络、回放缓存和训练批量大小;
72、步骤6.2、在每一个训练回合初始化状态s,观测每一个时隙和智能体的当前状态sk;
73、步骤6.3、如果当前回合在预训练阶段,使用公式进行vue分簇和消息块选择的探索,返回步骤6.2直至所有时隙和智能体执行完毕;否则,使用公式ak(t)=μk(sk(t);θk)选择动作,以进行vue分簇和消息块选择,返回步骤6.2直至所有时隙和智能体执行完毕;
74、步骤6.4、计算即时奖励r和下一个状态s′,然后将经验元组(s,a,r,s′)存储到经验池中;
75、步骤6.5、对于所有智能体,随机从回放缓存中抽取一个批量元组分别用于更新行动者、注意力机制评论家网络;
76、步骤6.6、通过软更新的方式更新目标的行动者、注意力机制评论家网络,并重复执行步骤6.6直至所有智能体执行完毕;
77、进一步的,步骤7中,进行对vue的联合无线和计算资源分配:
78、步骤7.1、对vue进行基于改进的交换匹配算法的资源块rb最优分配,这里提供一种改进的交换匹配算法对vue的资源块rb进行分配,对于初始匹配,首先对每个vue和资源块rb分别按降序构建偏好列表lk和ls,然后不匹配的vue迭代地向其最优资源块rb提出请求,资源块rb可以接受自己喜欢的vue并拒绝其他vue,直到所有vue匹配,执行步骤如下所示:
79、步骤7.1.1按降序初始化vue k和资源块rb s的偏好列表lk和ls;
80、步骤7.1.2初始化不匹配的vue集合
81、步骤7.1.3当vue的偏好列表和不匹配的vue集合不为空时,对所有存在不匹配的vue集合中的vue,迭代地依照当前资源块rb可实现上行时延和雷达互信息之积降序的顺序,向其还没拒绝过它的资源块rb提出匹配请求;
82、步骤7.1.4对于所有资源块rb,如果rb s接收了vue k的匹配请求,则rb s保持与vue k的匹配并拒绝所有其他匹配请求;否则,资源块rb s接受上行时延和雷达互信息之商最大的vue的匹配请求并拒绝其他vue的匹配请求;
83、步骤7.1.5迭代完成后输出最优的资源块rb分配结果;
84、步骤7.2、对vue进行基于改进的内点法的计算资源最优化分配:
85、基于步骤7.1得出的rb最优分配结果,进一步进行计算资源最优化分配,计算资源最优化分配问题的公式为:
86、
87、这里提供一种基于内点法的计算资源分配改进算法来求解,构造一个惩罚函数,公式如下:
88、
89、其中,f是一个可行解,执行步骤如下所示:
90、步骤7.2.1初始化惩罚因子r、可行解f、最大迭代次数niter、最大容忍误差ε0和更新系数b;
91、步骤7.2.2对每个vue k计算
92、步骤7.2.3如果获得kkt条件下的无约束的计算资源分配结果fk,n;否则,在最大迭代次数和最大容忍误差范围内,获取当前r和f下的惩罚函数ψi,并计算剩余的计算资源
93、步骤7.2.4对于所有vue k,更新vue的梯度值以及分配的计算资源结果
94、步骤7.2.5更新设置r=cr,其中c为下降系数;
95、步骤7.2.6迭代完成后输出最优的计算资源分配结果。
96、进一步的,步骤8中,分别将后续时隙的网络状态输入模型:
97、重复执行步骤6至步骤8,输出满足其时延和雷达互信息约束的长期满意度最大的车联网络中通信、感知和计算协同资源分配方案;协同资源分配方案包含选取最优的资源块、感知信息块、分簇和云服务器或雾节点服务器的cpu频率。
98、本发明所述车联网络中多维资源协同管理方法具有以下有益效果:
99、1.本发明所述车联网络中多维资源协同管理方法,设计了车联网络中基于分簇的协同感知网络模型,提供了一种车联网络中通信、感知和计算性能的衡量方式。
100、2.本发明所述车联网络中多维资源协同管理方法,设计了基于多智能体强化学习的vue分簇模式和感知信息块选择算法,极大地降低了vue上传感知信息块的通信时延并提高了雷达互信息。
101、3.本发明所述车联网络中多维资源协同管理方法设计了改进的内点法的计算资源分配算法,极大地降低了协同感知计算时延。
102、4.本发明所述车联网络中多维资源协同管理方法,联合对分簇、感知信息块选择、资源块rb分配和cpu周期频率进行优化,使得在满足其时延和雷达互信息约束等的同时,能够最大化协同感知任务的长期总满意度。
- 还没有人留言评论。精彩留言会获得点赞!