基于Pyspark框架的数据处理方法、装置及设备与流程
本技术涉及数据处理技术,尤其涉及一种基于pyspark框架的数据处理方法、装置及设备。
背景技术:
1、随着社会不断发展,在日常生活和工作中产生了海量数据,在企业生产、公共交通以及运输等行业需要对海量数据进行处理及分析,从而有利于各大行业发展。
2、现有技术中服务器获取原始数据后,对原始数据进行预处理后得到预处理数据,并调用目标机器学习算法,将预处理数据输入至目标机器学习算法,从而获得数据处理结果。
3、然而,现有技术中服务器调用目标机器学习算法进行数据处理时,如果是海量数据,服务器则会出现处理能力不足的现象,从而数据处理效率低。
技术实现思路
1、本技术提供一种基于pyspark框架的数据处理方法、装置及设备,用以解决服务器则会出现处理能力不足的现象,从而数据处理效率低的问题。
2、第一方面,本技术提供一种基于pyspark框架的数据处理方法,所述方法应用于控制服务器,所述控制服务器位于分布式集群中,所述分布式集群中还包括至少一个执行服务器,所述分布式集群是基于pyspark框架构建的,所述方法包括:
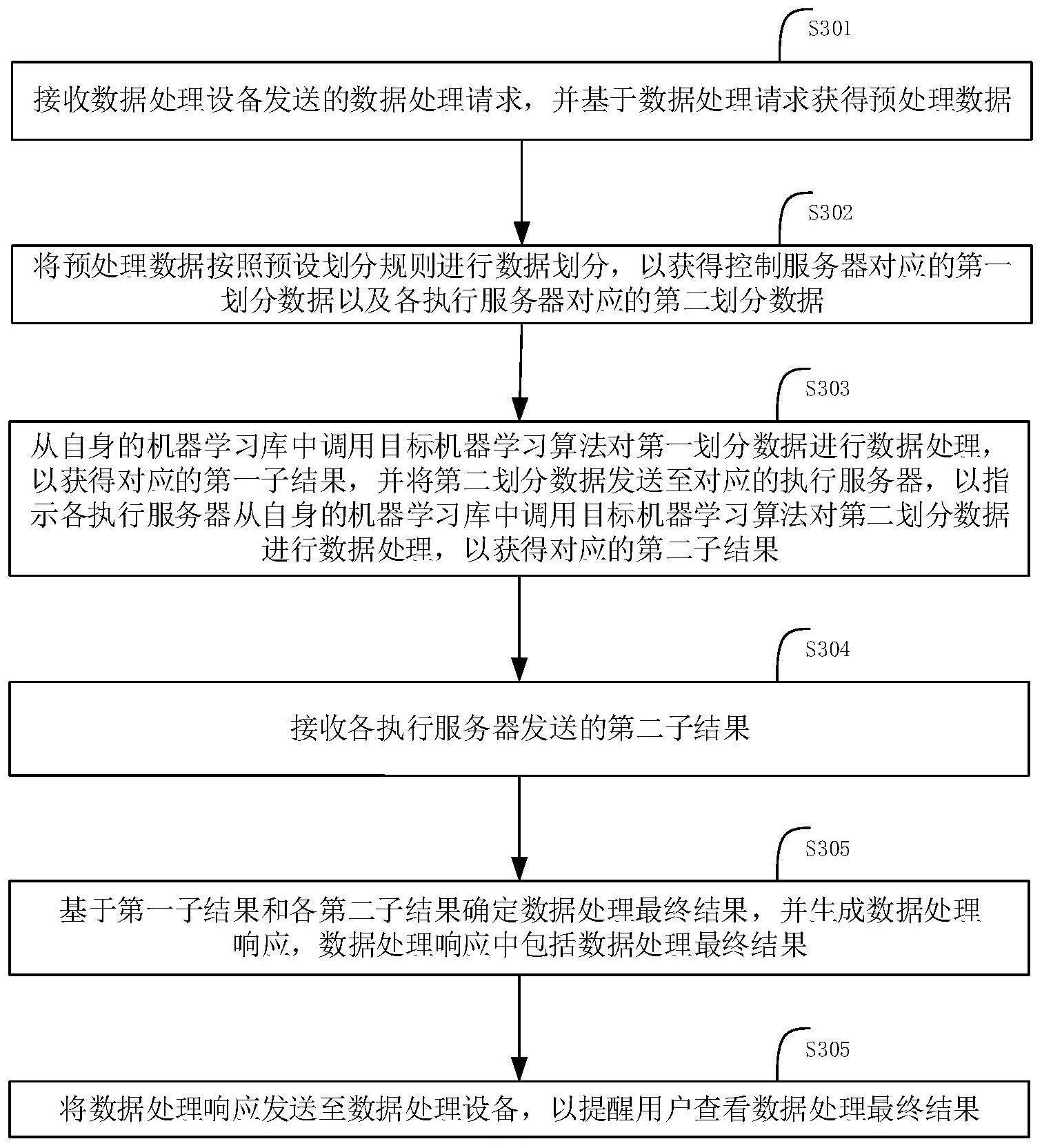
3、接收数据处理设备发送的数据处理请求,并基于所述数据处理请求获得预处理数据;
4、将所述预处理数据按照预设划分规则进行数据划分,以获得控制服务器对应的第一划分数据以及各执行服务器对应的第二划分数据;
5、从自身的机器学习库中调用目标机器学习算法对所述第一划分数据进行数据处理,以获得对应的第一子结果,并将第二划分数据发送至对应的执行服务器,以指示各所述执行服务器从自身的机器学习库中调用目标机器学习算法对第二划分数据进行数据处理,以获得对应的第二子结果;
6、接收各执行服务器发送的第二子结果;
7、基于所述第一子结果和各所述第二子结果确定数据处理最终结果,并生成数据处理响应,所述数据处理响应中包括数据处理最终结果;
8、将所述数据处理响应发送至数据处理设备,以提醒用户查看数据处理最终结果。
9、第二方面,本技术提供一种基于pyspark框架的数据处理方法,所述方法应用于至少一个执行服务器,所述至少一个执行服务器位于分布式集群中,所述分布式集群中还包括一个控制服务器,所述分布式集群是基于pyspark框架构建的,包括:
10、接收控制服务器发送的对应的第二划分数据;所述第二划分数据是所述控制服务器将预处理数据按照预设划分规则对分布式集群中的各执行服务器进行数据划分获得的;所述预处理数据是所述控制服务器基于所述数据处理请求获得的;所述数据处理请求是所述控制服务器接收数据处理设备发送的;
11、从自身的机器学习库中调用目标机器学习算法对第二划分数据进行数据处理,以获得对应的第二子结果;
12、将第二子结果发送至所述控制服务器,以指示所述控制服务器基于第一子结果和各所述第二子结果确定数据处理最终结果,并生成数据处理响应;所述数据处理响应中包括数据处理最终结果,并指示所述控制服务器将数据处理响应发送至数据处理设备,以提醒用户查看数据处理最终结果;所述第一子结果是所述控制服务器从自身的机器学习库中调用目标机器学习算法对第一划分数据进行数据处理获得的;所述第一划分数据是所述控制服务器将所述预处理数据按照划分规则对分布式集群中的控制服务器进行数据划分获得的。
13、第三方面,本技术提供一种基于pyspark框架的数据处理装置,所述装置位于控制服务器,所述控制服务器位于分布式集群中,所述分布式集群中还包括至少一个执行服务器,所述分布式集群是基于pyspark框架构建的,所述装置包括:
14、接收模块,用于接收数据处理设备发送的数据处理请求,获取模块,用于基于所述数据处理请求获得预处理数据;
15、划分模块,用于将所述预处理数据按照预设划分规则进行数据划分,以获得控制服务器对应的第一划分数据以及各执行服务器对应的第二划分数据;
16、数据处理模块,用于从自身的机器学习库中调用目标机器学习算法对所述第一划分数据进行数据处理,以获得对应的第一子结果,并将第二划分数据发送至对应的执行服务器,以指示各所述执行服务器从自身的机器学习库中调用目标机器学习算法对第二划分数据进行数据处理,以获得对应的第二子结果;
17、接收模块,还用于接收各执行服务器发送的第二子结果;
18、确定模块,用于基于所述第一子结果和各所述第二子结果确定数据处理最终结果,生成模块,用于生成数据处理响应,所述数据处理响应中包括数据处理最终结果;
19、发送模块,用于将所述数据处理响应发送至数据处理设备,以提醒用户查看数据处理最终结果。
20、第四方面,本技术提供一种基于pyspark框架的数据处理装置,所述装置位于至少一个执行服务器,所述至少一个执行服务器位于分布式集群中,所述分布式集群中还包括一个控制服务器,所述分布式集群是基于pyspark框架构建的,所述装置包括:
21、接收模块,用于接收控制服务器发送的对应的第二划分数据;所述第二划分数据是所述控制服务器将预处理数据按照预设划分规则对分布式集群中的各执行服务器进行数据划分获得的;所述预处理数据是所述控制服务器基于所述数据处理请求获得的;所述数据处理请求是所述控制服务器接收数据处理设备发送的;
22、数据处理模块,用于从自身的机器学习库中调用目标机器学习算法对第二划分数据进行数据处理,以获得对应的第二子结果;
23、发送模块,用于将第二子结果发送至所述控制服务器,以指示所述控制服务器基于第一子结果和各所述第二子结果确定数据处理最终结果,并生成数据处理响应;所述数据处理响应中包括数据处理最终结果,并指示所述控制服务器将数据处理响应发送至数据处理设备,以提醒用户查看数据处理最终结果;所述第一子结果是所述控制服务器从自身的机器学习库中调用目标机器学习算法对第一划分数据进行数据处理获得的;所述第一划分数据是所述控制服务器将所述预处理数据按照划分规则对分布式集群中的控制服务器进行数据划分获得的。
24、第五方面,本技术提供一种控制服务器,包括:处理器,以及与所述处理器通信连接的存储器和收发器;
25、所述存储器存储计算机执行指令;所述收发器,用于收发数据;
26、所述处理器执行所述存储器存储的计算机执行指令,以实现如上述第一方面或任一项方式中所述的方法。
27、第六方面,本技术提供一种执行服务器,包括:处理器,以及与所述处理器通信连接的存储器和收发器;
28、所述存储器存储计算机执行指令;所述收发器,用于收发数据;
29、所述处理器执行所述存储器存储的计算机执行指令,以实现如上述第二方面或任一项方式中所述的方法。
30、第七方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如上述第一方面、第二方面或任一项方式中所述的方法。
31、第八方面,本技术提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现如上述第一方面、第二方面或任一项方式中所述的方法
32、本技术提供的一种基于pyspark框架的数据处理方法、装置及设备,本技术中的数据处理方法应用于控制服务器,而控制服务器又位于分布式集群中,其中,分布式集群中还包括至少一个执行服务器,分布式集群是基于pyspark框架构建的,所以本技术是基于pyspark框架实现了数据处理方法,由于pyspark框架,可以实现对数据处理时采用分布式集群中包括的服务器进行共同处理,具体的,控制服务器接收数据处理请求,从而基于数据处理请求获得预处理数据,控制服务器将预处理数据按照预设划分规则进行数据划分,从而控制服务器获得对应的第一划分数据,各执行服务器获得对应的第二划分数据。进一步的,控制服务器从自身的机器学习库调用目标机器学习算法对第一划分数据进行数据处理,从而获得第一子结果,控制服务器将第二划分数据发送至各对应的执行服务器,从而指示各执行服务器从自身的机器学习库中调用目标机器学习算法对第二划分数据进行数据处理,从而获得各执行服务器对应的第二子结果,接收各执行服务器发送的第二子结果,从而控制服务器基于第一子结果和各第二子结果确定数据处理最终结果,并生成数据处理响应,其中,数据处理响应中包括数据处理最终结果,将数据处理响应发送至数据处理设备,从而提醒用户查看数据处理最终结果。本技术中对数据处理采用分布式集群中包括的服务器共同进行数据处理,各服务器承担一部分数据处理任务,然后基于各服务器处理得到的子结果获得数据处理最终结果,从而完成对数据的处理,由于本技术中能够采用分布式集群中的各服务器共同实现对数据的处理任务,所以本技术处理能力足够,进而处理速度快,提高了效率,特别是针对海量数据,本技术也是有足够处理能力进行处理。
- 还没有人留言评论。精彩留言会获得点赞!