一种基于注意力生成式卷积模型的信道均衡方法
本发明属于信号处理,尤其涉及一种基于注意力生成式卷积模型的信道均衡方法。
背景技术:
1、随着基于注意力机制的transformer(attention is all youneed)、bert(bert:pre-training of deep bidirectional transformers for language understanding)、chatgpt(improving language understanding by generative pre-training)等深度学习架构的提出,自然语言处理(nlp)领域在近五年得到了极大的发展。transformer的架构核心是将统计学中的注意力机制应用在了处理机器翻译问题的神经网络当中,通过计算“查询”和“键”的相似度作为注意力评分,对“值”进行加权平均。这一方法能使得在对句子中一个词元处理时,能够看到整个句子其他的词元,并根据注意力评分整合成与当前词元相关的语义空间信息。同时,这种架构的计算并行度高,使得能够处理长句子高复杂度问题的大模型成为可能。基于这种注意力机制,bert架构应用了transformer架构中的编码器,并在11项自然语言处理任务上取得最优。chatgpt创造性地开发了交互式聊天应用,使得工作迅速出圈。
2、transformer架构在nlp领域的优越性能,使得计算机视觉(cv)领域的研究人员也想要将注意力机制加入cv问题的网络结构中,由此提出了vit等模型,并认为cv中注意力机制是广义的卷积。vit和mae等模型在各自的任务上取得了很好的效果。
3、在通信领域,如自动调制识别(amc)等任务中,目前也有研究人员尝试将注意力机制应用于其中,在基础注意力模型上加入偏置(w.kong,x.jiao,y.xu,b.zhang andq.yang,"a transformer-based contrastive semi-supervised learning frameworkfor automatic modulation recognition,"in ieee transactions on cognitivecommunications andnetworking,doi:10.1109/tccn.2023.3264908.)、双注意力模型(h.su,x.fan and h.liu,"robust and efficient modulation recognition withpyramid signal transformer,"globecom 2022-2022ieee global communicationsconference,rio de janeiro,brazil,2022,pp.1868-1874,doi:10.1109/globecom48099.2022.10001593.)等,并取得了优于卷积神经网络,循环神经网络架构的效果。
4、目前已知的模型和实验并没有与信号处理的方法进行结合。一种方法是基于(mcformer:a transformer based deep neural network for automatic modulationclassification)通过卷积神经网络(cnn)与transformer两步进行特征提取,第二种方法是直接使用修改后的transformer模型进行训练,如双注意力。由于第一种方法没有进行很好的消融实验,信道的特征很有可能在cnn层中被学习到,训练完成后网络参数不再变化。网络计算过程中,使用多层cnn的多卷积核的组合起来对信道进行均衡与特征提取。当信道发生变化时,由于均衡与信道不匹配,导致信号的干扰进一步恶化,最终网络识别的结果是错误的。第二种方法在多头注意力层加入了一个卷积核,同样的,由于训练完成后网络参数不再变化,卷积核也可能学习到了固定的信道特征,从而无法应对数据集之外的信道。
技术实现思路
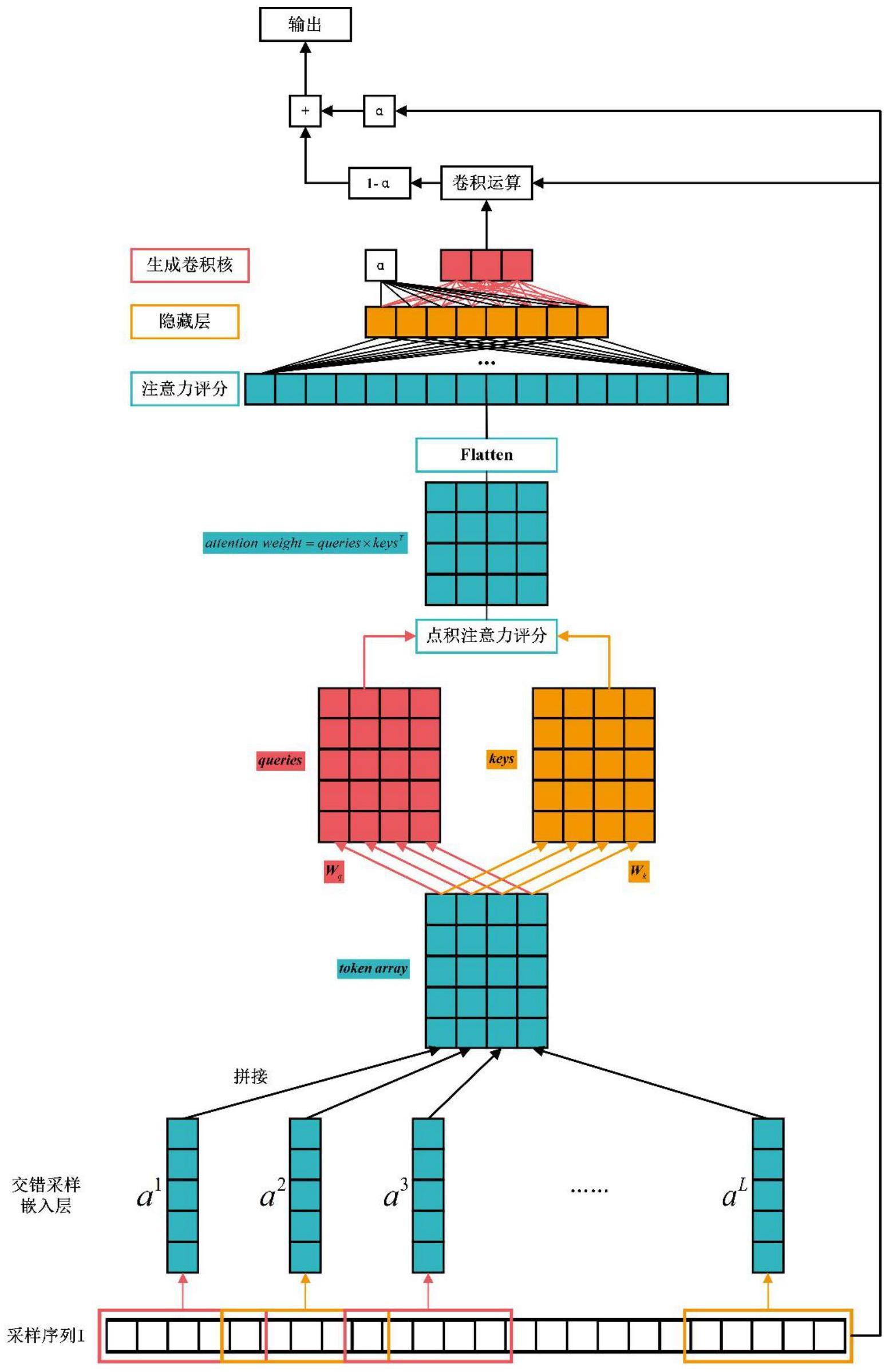
1、本发明目的是为了解决现有技术中的问题,从而提出一种基于注意力生成式卷积模型的信道均衡方法。所述方法能够从序列中计算出信道信息并得到用于信道均衡的卷积核,并对输入序列进行信道均衡。
2、本发明是通过以下技术方案实现的,本发明提出一种基于注意力生成式卷积模型的信道均衡方法,所述方法包括以下步骤:
3、步骤1、对采样信息序列进行层归一化layer normalization,对输入的序列进行自动增益控制;
4、步骤2、对输入序列进行交错采样,分别设置采样间隔interval和交错长度cross;依照两值对输入序列进行采样成长度为length=interval+cross的个序列,并将这些序列拼接成行length列的矩阵作为词元token array;
5、步骤3、对词元的行使用两个不同的线性层映射得到查询queries和键keys:
6、queries=wq×token array+biasq
7、keys=wk×token array+biask
8、其中,是可训练参数;hidden为映射后的向量长度,为超参数;
9、步骤4、使用点积注意力计算注意力分数矩阵:
10、attention weight=quaries×keyst
11、其中,上标t表示矩阵转置;
12、步骤5、将注意力分数矩阵attention weight通过flatten操作展平成一个行向量,作为下一步多层感知机mlp的输入:
13、attention array=flatten(attention weight)
14、也可以写成:
15、attention array=attention weight.reshape(batch size,-1)
16、步骤6、使用mlp生成卷积核与门控单元:
17、[kernel,α]=wo×f(wh×attention array+biash)+biaso
18、其中,是可训练参数;h为隐藏层大小,kernel length为卷积核长度,为超参数;
19、步骤7、使用生成卷积核kernel对ln层后的原序列i卷积,并使用门控单元α进行输出控制:
20、output=α×i+(1-α)×(i*kernel)
21、其中,*运算符表示卷积;
22、步骤8、利用训练好的注意力生成式卷积模型和损失函数进行信道均衡处理,如果模型计算结果的错误量小于3比特,认为信道均衡处理正确。
23、进一步地,在步骤1中,归一化layer normalization具体为:
24、其中,拉伸参数γ和偏移参数β为可训练参数,μl为样本均值,σl为样本标准差,以x∈l表示一层所有维度的输入,ε为一极小值,
25、进一步地,所述损失函数具体为均方误差mse损失函数:loss=min{mse(output,label),mse(-output,label)}。
26、本发明具有的有益效果是:
27、(1)本发明提出了根据注意力生成卷积核的方法,能够根据信息序列的注意力评分生成匹配的卷积核,从而自适应地进行信道均衡、特征提取。实际使用中,不需要导频序列,提高了频谱效率。
28、(2)本发明引入了门控单元,使得网络结构能判断信道特征从而自动选择是否需要均衡器处理,使得网络能对高斯信道的数据做特殊处理。能够更好地对高斯信道进行处理。同时起到了残差连接的效果,使得网络能够训练的更深。
29、(3)本发明将ln层放置于网络的第一层,起到对输入序列进行自动增益控制的功能,使得网络更容易训练。
30、(4)本发明修改了损失函数,能够忽略信道中比特反转的情况。比特反转可以在框架外通过预编码等技术解决。
- 还没有人留言评论。精彩留言会获得点赞!