出行热点提取方法、系统、设备及存储介质
本发明属于热点提取,具体涉及一种出行热点提取方法、系统、设备及存储介质。
背景技术:
1、城市的出行热点作为居民活动和社会事件的聚集发生地,其时空分布及动态演化反映了居民在城市的流动性和城市区域的功能分布。因此,基于城市的出行热点分析居民出行行为和城市内部空间结构一直以来都受到众多学者的关注。
2、早期的城市的出行热点研究主要采用问卷调查和社会经济统计资料的方式完成,如利用从调查问卷中获取的游客性别、年龄、客流量等多项指标,分析城市的出行热点。但这种研究方式不仅耗时耗力,且人群覆盖面和调查内容的覆盖度非常有限,调查内容的真实性也缺乏保障。
3、目前,利用地理时空大数据探测城市的出行热点已成为城市出行热点研究的主流。通过是对相关位置轨迹点进行聚类获得,如采用划分式聚类方算法对出行热点进行提取,但是划分式聚类算法,对于初始聚类中心的选取十分重要,不同的初始聚类中心,可能会出现不同的聚类结果,易陷入局部最优问题。
技术实现思路
1、本发明的目的在于提供一种出行热点提取方法、系统、设备及存储介质,能够有效避免了陷入局部最优,提高了聚类算法的准确性和收敛速度。
2、本发明第一方面公开了一种出行热点提取方法,包括:
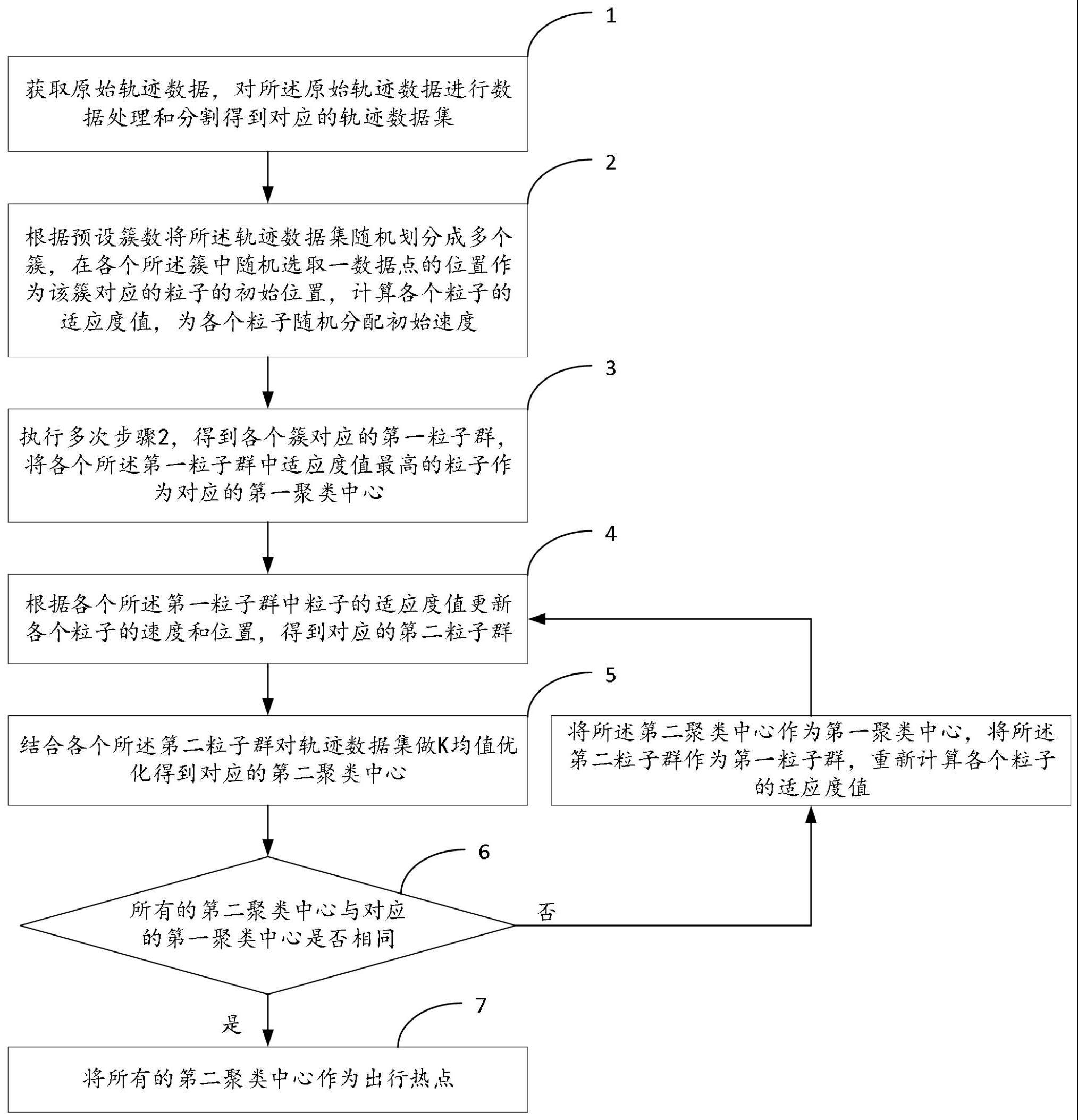
3、步骤1、获取原始轨迹数据,对所述原始轨迹数据进行数据处理和分割得到对应的轨迹数据集;
4、步骤2、根据预设簇数将所述轨迹数据集随机划分成多个簇,在各个所述簇中随机选取一数据点的位置作为该簇对应的粒子的初始位置,计算各个粒子的适应度值,为各个粒子随机分配初始速度;
5、步骤3、将步骤2执行多次,得到各个簇对应的第一粒子群,将各个所述第一粒子群中适应度值最高的粒子作为对应的第一聚类中心;
6、步骤4、根据各个所述第一粒子群中粒子的适应度值更新各个粒子的速度和位置,得到对应的第二粒子群;
7、步骤5、结合各个所述第二粒子群对轨迹数据集做k均值优化得到对应的第二聚类中心;
8、步骤6、判断所有的第二聚类中心与对应的第一聚类中心是否相同,若是,则执行步骤7、若否,则将所述第二聚类中心作为第一聚类中心,将所述第二粒子群作为第一粒子群,重新计算各个粒子的适应度值,并执行步骤4;
9、步骤7、将所有的第二聚类中心作为出行热点。
10、可选的,所述根据各个所述第一粒子群中粒子的适应度值更新各个粒子的速度和位置,得到对应的第二粒子群,包括:
11、步骤41、根据各个粒子的适应度值与其经历过的适应度值,确定各个粒子的个体最优解;
12、步骤42、根据各个所述第一粒子群中的所有粒子的个体最优解,确定各个第一粒子群的全局最优解;
13、步骤43、根据粒子速度更新公式和粒子位置更新公式更新各个所述粒子的速度,所述粒子速度更新公式为:
14、
15、其中,v'id为第i个粒子在第d个维度上更新后的速度分量,为压缩因子,vid为第i个粒子在第d个维度上当前的速度分量,xid为第i个粒子在第d个维度上当前的位置分量,w为惯性权重,pid为第i个粒子的个体最优解,pgd为第i个粒子对应的第一粒子群的全局最优解,c1为第一加速系数,c2为第二加速系数,rand()为值在[0,1]之间的随机数;
16、所述粒子位置更新公式为:
17、x′id=xid+vid,
18、其中,x'id为第i个粒子在第d个维度上更新后的位置分量,xid为第i个粒子在第d个维度上当前的位置分量,vid为第i个粒子在第d个维度上当前的速度分量。
19、可选的,所述压缩因子的计算公式为:
20、
21、其中,ρ为常数,ρ>4。
22、可选的,所述惯性权重w根据0.9向0.4线性减小的变化进行取值。
23、可选的,所述结合各个所述第二粒子群对轨迹数据集做k均值优化得到对应的第二聚类中心,包括:
24、将各个所述第二粒子群中适应度值最高的粒子作为对应的聚类中心;
25、计算所述轨迹数据集中的数据点与各个聚类中心之间的距离,根据最近邻原则,将所述轨迹数据集中的数据点分配给距离其最近的聚类中心,得到更新后的各个簇,计算更新后的各个簇中所有数据点的均值处得到对应的第二聚类中心。
26、可选的,所述对所述原始轨迹数据进行数据处理和分割得到对应的轨迹数据集,包括:
27、对所述原始轨迹数据进行数据清洗得到有效轨迹数据;
28、对所述有效轨迹数据进行数据标准化得到标准化数据;
29、根据预设分割标识对所述标准化数据进行分割得到对应的轨迹数据集。
30、可选的,还包括:
31、步骤8、将所有的出行热点添加给点图层,将路线段添加给线路图层,所述路线段根据所述轨迹数据进行绘制,将添加有出行热点的点图层和添加有路线段的线路图层添加给地图对象,进行可视化输出。
32、本发明第二方面公开了一种出行热点提取系统,包括:
33、获取处理模块,用于获取原始轨迹数据,对所述原始轨迹数据进行数据处理和分割得到对应的轨迹数据集;
34、初始化模块,用于根据预设簇数将所述轨迹数据集随机划分成多个簇,在各个所述簇中随机选取一数据点的位置作为该簇对应的粒子的初始位置,计算各个粒子的适应度值,为各个粒子随机分配初始速度;
35、粒子群初始模块,用于执行初始化模块多次,得到各个簇对应的第一粒子群,将各个所述第一粒子群中适应度值最高的粒子作为对应的第一聚类中心;
36、粒子群更新模块,用于根据各个所述第一粒子群中粒子的适应度值更新各个粒子的速度和位置,得到对应的第二粒子群;
37、k均值模块,用于结合各个所述第二粒子群对轨迹数据集做k均值优化得到对应的第二聚类中心;
38、判断模块,用于判断所有的第二聚类中心与对应的第一聚类中心是否相同,若是,则执行热点确定模块、若否,则将所述第二聚类中心作为第一聚类中心,将所述第二粒子群作为第一粒子群,重新计算各个粒子的适应度值,并执行粒子群更新模块;
39、热点确定模块,用于将所有的第二聚类中心作为出行热点。
40、本发明第三方面公开了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至7中任一项所述的方法的步骤。
41、本发明第四方面公开了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的方法的步骤。
42、本发明所提供的技术方案具有以下的优点及效果:通过将步骤2执行多次,得到各个簇对应的第一粒子群,也就是确定初始的第一粒子群,在每一轮的迭代过程中,根据各个所述第一粒子群中粒子的适应度值更新各个粒子的速度和位置对第一粒子群进行更新,得到第二粒子群,根据第二粒子群以确定该轮的k均值聚类算法的初始聚类中心,有效避免了陷入局部最优,提高了聚类算法的准确性和收敛速度;在更新各个粒子的速度和位置的过程中,粒子群算法中带压缩因子,能通过配置最优参数(如第一加速系数和第二加速系数)控制粒子群更新速度,有效改进粒子群算法的准确率和全局收敛性。
- 还没有人留言评论。精彩留言会获得点赞!