一种基于GPU并行实现密码技术中大整数乘法的方法
本发明涉及公钥密码,具体是涉及一种基于gpu并行实现密码技术中大整数乘法的方法。
背景技术:
1、随着云计算时代的到来和云服务需求的不断增加,用户数据的安全性和隐私性成为人们关注的热点。尽管云平台存放的是用户经过加密的数据,但同时密钥被云服务商所获知,不能确保用户数据的安全和隐私。同态加密依据对加密数据进行处理的能力,完美符合隐私计算的计算模式,成为了当前学术研究的热点,受到了广泛的关注;其中paillier复合剩余类难题的公钥加密算法正是最为重要的算法之一。在实际应用当中,paillier密钥的长度需要达到2048比特,以此满足大多数应用场景的安全需要。但2048比特的密钥参与到乘法运算中,速度较慢,算法复杂度高,限制了paillier等算法的适用范围;因此,研究一种能够提高加密性能的大数乘法算法在国内外快速发展起来。
2、基于传统的按位乘法中,需要将一个操作数的每一位乘以另一个操作数据的每一位并累加,算法复杂度达到了o(n^2),使用cpu单线程计算大数乘法来说是不可接受的。因此,研究gpu并行计算大整数乘法提高密钥运算速度具有重要研究价值与意义。
3、gpu起初的设计目的是辅助cpu完成图像渲染等计算机图形学功能,而随着硬件及相关软件体系的不断完善,gpu的应用已不再局限于计算机图形处理,基于gpu的通用并行计算研究引发了广泛的关注。
4、cuda并行计算架构是利用了gpu的处理能力,因其大规模、高并行和易开发的特点,逐渐在高性能密码计算中得到广泛应用。利用cuda平台区分高位低位的乘加指令完成两个w比特整数的相乘,可以分别获得乘法运算的高w比特和低w比特,同时利用洗牌指令获取同一个线程束中其他线程的运算产生的长度为w比特的进位,完成乘积的高w比特或低w比特与进位的加法运算。利于cuda平台的各类指令,能够方便通过多个线程实现大整数乘法的并行计算;但现有的gpu大整数乘法研究中,均是采用单个线程完成一次大整数乘法,使得算法存在实现复杂度较高、并行度低的问题。
5、如cn201610325863公开了一种利用浮点数计算指令实现大整数乘法计算加速方法,其利用cuda平台的浮点数计算指令实现大整数乘法运算;但是该方法并未对乘法进行拆分,单个线程的计算量依旧很大,整体的计算延时高。
技术实现思路
1、为解决上述技术问题,本发明提供了一种基于gpu并行实现密码技术中大整数乘法的方法,将公钥密码计算中的大整数乘法拆分成多个部分分配到多个线程之中,采用多个线程并行完成一次大整数乘法运算,减少了单个线程的计算量,有效提升了公钥密码中乘法操作的性能,降低大整数乘法计算的复杂度,提升计算速度。
2、本发明所述的一种基于gpu并行实现密码技术中大整数乘法的方法,包括以下步骤:
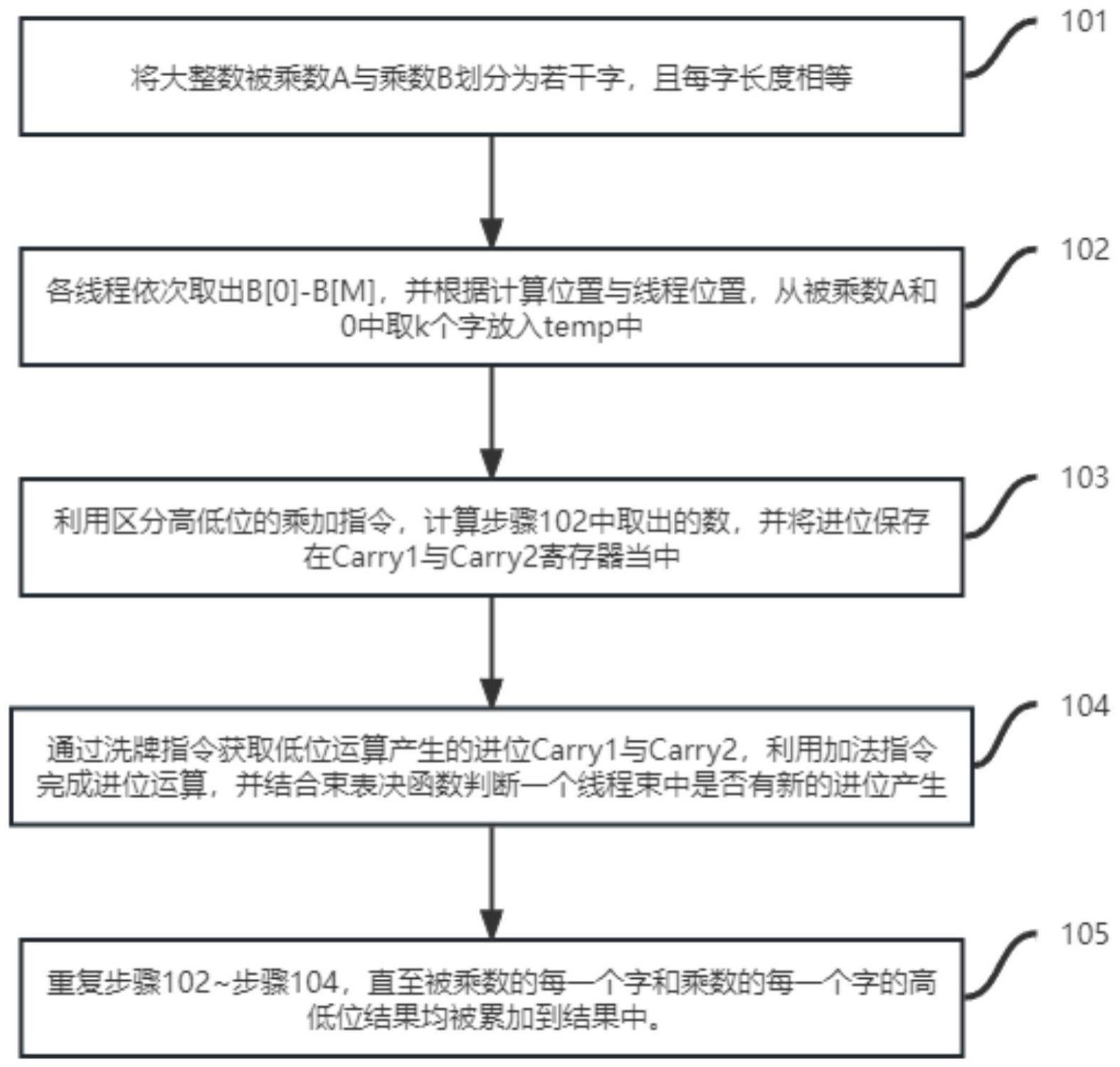
3、步骤1、数据划分:对在gpu平台上进行的公钥密码加解密过程需要进行大整数乘法的数据进行划分,将输入的被乘数记为a,乘数记为b,对长度为n比特的被乘数a按照从低到高(或从高到低)的次序每w比特划为一个字,共计n个字,长度为m比特乘数b按照与a同样的高低次序每w比特划为一个字,共计m个字;
4、步骤2、线程取数:采用x个线程并行计算一个大整数乘法,每个线程取对应位置上的被乘数与乘数;
5、步骤3、乘法运算:对于步骤2中取到的数,在每个线程当中使用区分高位低位的乘加指令,依次计算被乘数与乘数的乘积,将最终结果保存至result,进位保存在carry1、carry2中;
6、步骤4、进位运算:通过使用洗牌指令获取其他线程运算产生的进位carry1、carry2放入tmp中,使用加法指令计算result与tmp的和,将新的结果写入result,将新产生的进位保存在carry中;通过循环迭代方式,即使用cuda的束表决函数,判断在一个线程束中,是否有线程存在进位;如果存在,线程束中的所有线程同时累加迭代,直到所有线程不再产生进位;
7、步骤5、结果写回:将各线程所得到的计算结果result放入最终结果的对应位置并输出结果。
8、进一步的,对被乘数a和乘数b划分时,若长度不能被w整除,通过高位补0的方式将长度填充至w的整数倍。
9、进一步的,对于步骤1的划分结果,定义以下符号:a[u]表示a的第u个字,b[u]表示b的第u个字,a[0:n-1]表示被乘数a的第0~(n-1)的n个字,b[0:m-1]乘数b的第0~(m-1)的m个字。
10、进一步的,其特征在于,对于步骤1的划分结果:a为n个字,b为m个字,其中每个线程根据位置从被乘数a或0中取k个字与乘数b相乘,其中一个大整数乘法的所有线程同属于一个线程束之中,而一个线程束的大小为32,,故线程数x≤32。
11、进一步的,采用了区分高位低位的乘加指令为cudaptx提供的底层乘加指令,改进了乘法运算的实现过程;定义两个乘数a、b,加数c,结果d,其长度均为w比特;计算前标志寄存器计为cf_in,计算后标志寄存器计为cf_out,区分高位低位的乘加指令表示为:
12、(d,cf_out)=madc.lo.cc.(a,b,c)=(a×b).lo+c+cf_in
13、(d,cf_out)=madc.hi.cc.(a,b,c)=(a×b).hi+c+cf_in
14、其中(a×b).lo表示低w比特运算,(a×b).hi表示高w比特运算,cf_out用于保存计算产生的进位。
15、进一步的,x个线程并行计算完成一个大整数乘法,其具体过程为:
16、其中第i号线程的计算过程为:
17、1)j从0至m-1,每次取出乘数b的一个字b[j]作为b,根据线程号i与循环号j的值从被乘数a或0中取k个字放入temp中,利用区分高位低位的乘加指令完成b与temp做乘法,循环m次计算完成b与temp的乘法计算,结果放入result[0:8]中,进位存入carry1,carry2中;
18、2)x个线程并行计算完成后通过洗牌指令获取低位线程的进位carry1,carry2,并于本线程的计算结果result[0:8]做加法运算,结果放入result[0:8]中,进位存入carry中;
19、3)判断各线程的carry值是否为0,若为0则结束计算,否则再执行2)。
20、本发明所述的有益效果为:本发明所述的方法采用cuda平台提供的区分高位低位的乘加指令,改进了公钥密码中乘法运算的实现过程,避免了对于乘数、被乘数和结果的数据类型转换,降低了公钥密码算法的复杂度;同时将大整数的乘法的各个部分拆分为若干块分布到多个线程当中,多个线程同时计算大整数乘法的各个部分,并利用了cuda的洗牌指令和束表决函数实现线程间的通信,获取各线程的计算结果进行合并与进位的计算,以此提高算法的并行度,降低算法的时间开销,充分发挥平台的计算资源。
技术特征:
1.一种基于gpu并行实现密码技术中大整数乘法的方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于gpu并行实现密码技术中大整数乘法的方法,其特征在于,对被乘数a和乘数b划分时,若长度不能被w整除,通过高位补0的方式将长度填充至w的整数倍。
3.根据权利要求1或2任一项所述的一种基于gpu并行实现密码技术中大整数乘法的方法,其特征在于,对于步骤1的划分结果,定义以下符号:a[u]表示a的第u个字,b[u]表示b的第u个字,a[0:n-1]表示被乘数a的第0~(n-1)的n个字,b[0:m-1]乘数b的第0~(m-1)的m个字。
4.根据权利要求1或2所述的一种基于gpu并行实现密码技术中大整数乘法的方法,其特征在于,对于步骤1的划分结果:a为n个字,b为m个字,其中每个线程根据位置从被乘数a或0中取k个字与乘数b相乘,其中一个大整数乘法的所有线程同属于一个线程束之中,而一个线程束的大小为32,故线程数x≤32。
5.根据权利要求2所述的一种基于gpu并行实现密码技术中大整数乘法的方法,其特征在于,采用cuda ptx提供的区分高位低位的乘加指令改进了乘法运算的实现过程;定义两个乘数a、b,加数c,结果d,其长度均为w比特;计算前标志寄存器计为cf_in,计算后标志寄存器计为cf_out,区分高位低位的乘加指令表示为:
6.根据权利要求5所述的一种基于gpu并行实现密码技术中大整数乘法的方法,其特征在于,x个线程并行计算完成一个大整数乘法,其具体过程为:
7.根据权利要求1所述的一种基于gpu并行实现密码技术中大整数乘法的方法,其特征在于,所述方法应用在计算工程需要进行大整数乘法的公钥密码算法中。
技术总结
本发明属于公钥密码技术领域,公开了一种基于GPU并行实现密码技术中大整数乘法的方法,通过将大整数乘法运算拆解到多个线程中计算,在进行大整数乘法运算时,将被乘数和乘数拆分为若干字,利用区分高位低位的乘加指令完成各线程中的乘法计算与产生进位,并利用线程束的洗牌指令获取来自低位产生的进位,再利用束表决函数指令与加法指令实现循环进位运算,直到被乘数的每一个字和乘数的每一个字的高低位结果均被累加到结果中。本发明的有益效果是:通过多个线程共同完成大整数乘法运算,降低了单个线程计算大整数乘法的计算量,有效提高GPU计算资源的利用率,提升了大整数乘法的运算速度,提升公钥加密算法的实用性。
技术研发人员:董振江,叶青波,董建阔,亓晋,孙雁飞,陈滏媛
受保护的技术使用者:南京邮电大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!