一种无线接入网中基于联邦学习的高效自协同方法
本发明属于无线通信,具体涉及一种无线接入网中基于联邦学习的高效自协同方法。
背景技术:
1、随着通信技术的蓬勃发展,未来无线接入网逐步演进的更加复杂和异构。因此,仅依赖传统模型驱动的通信系统设计将难以捕捉网络中动态复杂特征,进而不足以支撑未来无线网络中极致化的应用需求。此外,随着智能设备的普及以及多样应用的出现,无线通信网络产生了空前的海量数据。这些海量数据以及并行计算技术的发展助长了包括无线通信在内的许多领域对机器学习的研究兴趣。因此,国际标准开发组织3gpp已确定将数据驱动的机器学习技术作为可行解决方案来应对通信行业面临的紧迫挑战。与此同时,随着移动计算和物联网技术的发展,数据来源正在从云数据中心转移到例如智能手机、监视摄像头和可穿戴设备等网络边缘节点上。根据思科公司统计估算,2021年数据中心产生的数据只能达到20zb,而网络边缘节点预计生成了近850zb的数据。然而,由于带宽有限和时延的限制,传统的集中式方法,即通过把原始数据上传到数据中心进行数据处理的方案会消耗大量的通信资源。此外,随着对数据隐私和数据安全方面需求的提高,这种传输原始数据的方法也变得不再适用。
2、此外,随着各界对数据隐私性和安全性的重视,直接进行原始数据交换的方式也变得不再适用。随着计算能力的下沉,各界纷纷提出无线网络中的拥有数据的智能节点(例如:各类用户设备以及基站)可通过协同学习的方法来本地化处理数据。目前,各界纷纷提出将计算能力下沉到无线接入网边缘,这为无线节点之间的协同提供了基础。因此,未来无线接入网可通过协同学习实现知识共享和信息传递,从而提高网络的效率和吞吐量。具体来说,通过节点之间的模型交换和分析,无线接入网的节点协同学习可以更准确地预测用户需求和网络状态,提高网络的响应速度和数据传输效率,同时避免了数据隐私性担忧。
3、目前,机器学习算法和大数据技术已经被公认为是一种可行的解决方案来应对通信技术产业面临的挑战。面对海量数据,传统的集中式数据处理需要巨大的通信开销。因此,亟需设计高效的分布式框架来支持无线接入网中的协同学习。随着联邦学习技术的发展,目前基于联邦学习框架下的无线接入网的协同问题引起了各界的关注。
4、联邦学习作为一种新型的分布式机器学习算法避免了大量原始数据的传输,可以为协同数据处理提供有效的解决方案,并且保证了数据的隐私性。如图1,联邦学习分为两种基本架构:有中心的架构(左)和全分布式架构(右)。在有中心的架构下,所有拥有本地数据的worker节点(通常为用户设备)训练本地机器学习模型并将本地模型传输到parameterserver(ps)节点(通常为基站)。ps节点收到模型后进行模型聚合,并将聚合后的模型向下传输给所有的worker节点。然而,在模型上传和下发过程中,可能会有大量流量涌向ps节点,从而导致ps很容易成为系统瓶颈。此外,中心式架构存在不可避免的单点故障问题以及可扩展性差的弊端。与中心式架构相比,在全分布式架构下,协作节点通过本地训练以及与邻居节点交换传输模型来不断提升本地模型性能,进而可以有效避免单点故障并且具有灵活的可扩展性。因此,本发明考虑在全分布式架构下研究无线接入网的协同机制。
5、然而,无线接入网中的两个重要属性,即:动态性和异构性,对全分布式的协同学习造成了挑战。具体来说,由于节点位置变化以及无线信道的时变特性,导致无线接入网具有极高的动态性。因此,亟需针对无线环境的动态性设计自适应的协同策略从而提高协作节点的学习效率。其次,在无线接入网中,协作节点通常是异构的,包括数据集、计算能力、通信能力等方面。多个维度的异构性会导致难以通过传统的优化方法来挖掘节点间的隐含关系,从而增加了协同策略设计的难度。现有的大多数解决方案通常是基于中心式的架构的联邦学习来实现无线接入网中的高效协同学习,因此对于全分布式场景并不适用。目前,有一部分文献研究了全分布式架构下的协同学习设计,但仍采用较为固定的协作策略且没有关注无线接入网环境的动态性,例如d-psgd,cdsgd等。因此,亟需设计针对分布式异构无线接入网场景下的高效自协同机制。
技术实现思路
1、有鉴于此,本发明的目的是提供一种无线接入网中基于联邦学习的高效自协同方法,可以有效地提升协同学习效率,减少协同学习中运行时间和通信开销。
2、一种无线接入网中基于联邦学习的高效自协同方法,包括:
3、步骤一、构建自适应协同模型:
4、针对每一个协作节点定义分布式的随机协同策略:协作节点i的协同策略表示在第k次迭代时协同动作ai(k)的概率分布:
5、
6、其中,ai,0(k)代表本地训练指示变量,如果节点i在第k次迭代进行本地模型训练,则ai,0(k)=1,否则ai,0(k)=0;ai,j(k)是模型参数请求指示变量,如果节点i在迭代步骤k时从其邻居中请求模型参数,则ai,j(k)=1,否则ai,j(k)=0;其中,表示协作节点i的邻居集合;
7、在第k次迭代时,协作节点i请求模型参数的邻居集合表示为:
8、
9、步骤二、构建问题模型:
10、定义分布式协同学习的学习效率为:
11、
12、其中,ei(k)表示协作节点i在第k迭代的学习效率;acci(θi(k))表示协作节点i在迭代次数k时模型的准确度;acci(θi(k))-acci(θi(k-1))表示第k迭代后协作节点i的模型精度的改变量;τi(k)表示协作节点i在第k次迭代时所需的时间;
13、将分布式协同学习问题建模为马尔可夫博弈问题;马尔可夫博弈问题由多元组定义,其中表示协作节点的集合;表示协作节点观察到的状态空间,表示协作节点i的动作空间;表示协作节点的联合动作空间;表示通过动作从中的一个状态s到中的任意状态s′的转移概率;是协作节点i执行动作后收到的即时奖励;γ∈(0,1]是折扣因子;
14、针对分布式协同学习问题,每一个协作节点都充当一个学习最优协作策略的智能体;用状态空间描述智能体的状态,其中包括在协作节点本地模型的准确度;在迭代步骤k时各方的状态表示为:
15、
16、其中acci(k-1)是协作节点i在迭代步骤k-1时的准确度;在迭代步骤k时,协作节点i的动作ai(k)由协作策略中式(1)定义;执行动作后,状态s(k)将转换到下一个状态s(k+1);
17、在完成一轮迭代后,协作节点i将获得即时奖励,即ri(k),作为采取特定行动的反馈;即时奖励函数ri(k)定义为:
18、
19、优化目标是通过学习最优合作策略设计一个高效的无线接入网分布式协同学习策略,使各协作节点在纳什均衡的情况下最大化长期平均收益;协作节点i的目标函数表示为:
20、
21、其中,γ是一个折扣因子;πi表示节点i的随机协作策略;-i表示中除节点i外所有协作节点的索引;π-i表示除了节点i外所有协作节点联合协作策略;
22、在联合协作策略下,将协作节点i的值函数vi被定义为:
23、
24、其中,s表示当前状态;
25、其中,值函数是预期的累积折扣奖励;是各个协作节点的联合行动;节点i的联合协作策略π下的动作值函数表示为:
26、
27、其中,a表示当前的动作;
28、步骤三、采用纳什均衡策略来保证各个协作节点策略的收敛性,采用自适应分布式协同学习,获得协作策略:
29、步骤3.1、q函数的平均场表征
30、首先将第i协作节点标准q函数分解为成对局部q函数和的形式:
31、
32、其中,是协作节点i及其邻居的成对的局部q函数;
33、采用平均场理论来近似表征q函数:平均场q函数是通过计算协作节点i的邻居的平均动作来近似标准q函数其中是协作节点j的独热编码动作aj;
34、当成对的局部q函数为m-smooth时,标准q函数由平均场q函数和一个有界值b∈[-2m,2m]表示:
35、
36、其中,m为一个常数;
37、根据贝尔曼方程式,平均场q函数进一步表示为:
38、
39、其中,协作节点i的平均场值函数为:
40、
41、每个协作节点i均采用玻尔兹曼探索策略来进行学习:
42、
43、其中,ξ是玻尔兹曼探索策略的参数;
44、步骤3.2、采用adcl算法实现无线接入网全分布式协同学习:
45、对于每个迭代步骤k,协作节点首先根据式(4)得到当前环境,然后根据式(14)计算协作策略;根据协同策略,每个协作节点i执行本地训练流程;其中,每个协作节点i决定在协同策略中ai,0(k)=1时训练本地模型;本地训练阶段的模型参数更新公式为:
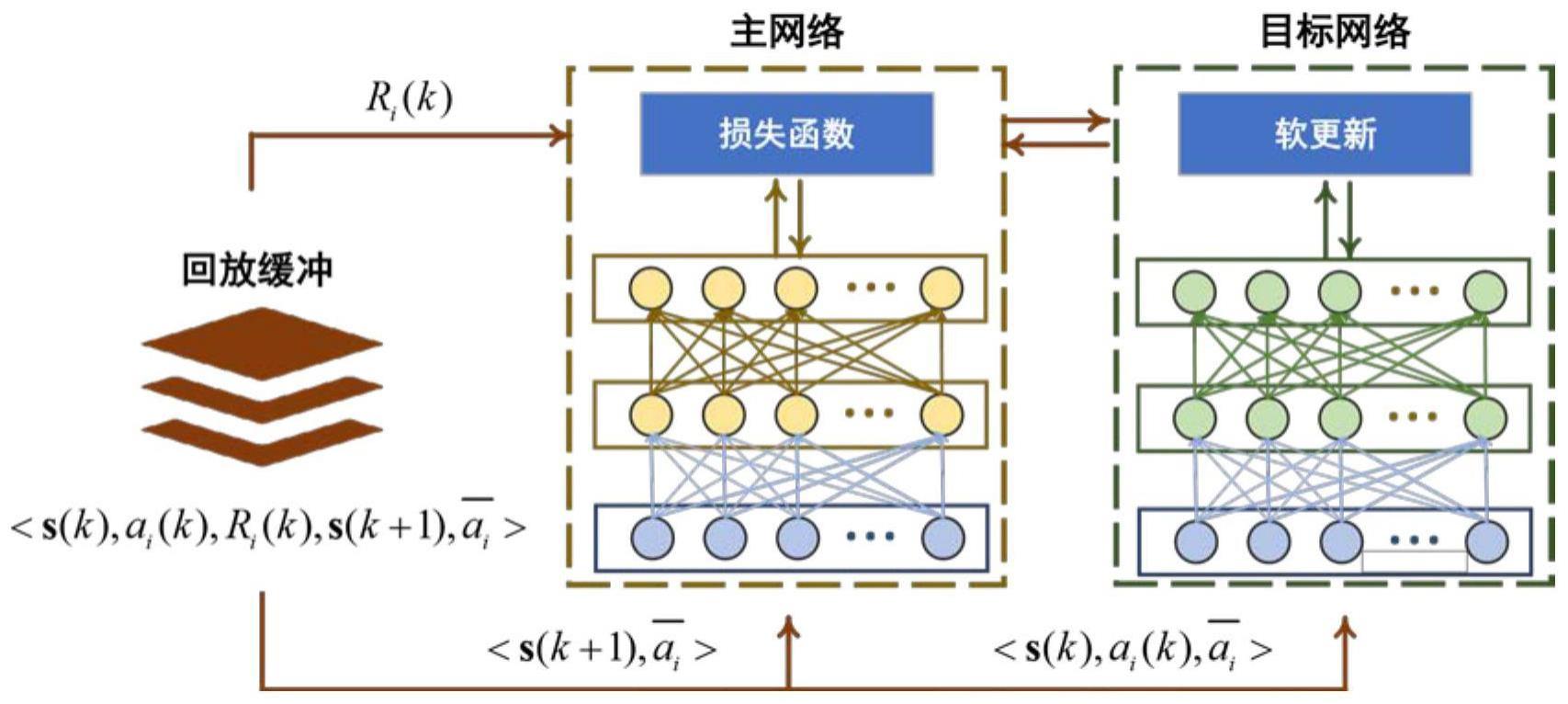
46、
47、其中,δθi(k)是模型参数的梯度向量,β是学习率;
48、接下来,每个协作节点i进行模型的传输,即如果协作策略中的ai,j(k)=1,则以从其邻居中获取模型如果aj,i(k)=1,则协作节点i向其邻居发送自身的模型之后,各个协作节点在聚合阶段根据以下公式聚合获取的模型参数:
49、
50、其中,ρi是用于聚合模型参数的权重;
51、然后,各个协作节点根据参数更新后模型得到协作策略,并计算奖励函数;
52、然后,观察下一步的状态,计算平均动作,并将得到的经验数据存储在回放缓冲区b中;
53、返回步骤3.2,进入下一轮的决策过程;当满足迭代条件,输出最后的协作策略,完成自协同;
54、其中,采用双层神经网络对每个协作节点的q函数进行拟合,具体包括:
55、双层神经网络包括全连接网络形式的主网络和目标网络;主网络和目标网络的输入分别为s,ai,和s,ai,网络参数表示为ωi和按照以下方法对双层神经网络训练完成后,输出协作节点的q函数;
56、针对每个协作节点i,从回放缓冲区b中抽取一个批次的经验数据,基于经验数据,双层神经网络的主网络的损失函数表示为:
57、
58、其中,k是设定的批次大小,是目标网络的平均场值函数值;然后,主网络的参数ωi通过以下方式更新:
59、
60、其中,ξt是主网络的学习率;目标网络参数根据主网络参数ωi进行定期的软更新;目标网络的参数更新公式为:
61、
62、其中,τ是目标网络的软更新因子。
63、较佳的,所述步骤一中,在第k次迭代时,协作节点i需要通过无线传输得到模型参数的邻居集合,表示为
64、本发明具有如下有益效果:
65、本发明提出的一种无线接入网中基于联邦学习的高效自协同方法,其中adcl算法通过强化学习设计协作节点的自适应协作策略,提高协同学习效率。首先定义了自适应协同模型来支持协作节点的间灵活通信和本地训练策略。其次设计了q函数的平均场表征机制,从而缓解了标准q函数中联合动作空间爆炸的问题。然后针对强化学习中过拟合问题,设计了双层神经架构将动作选择和动作评估解耦。数值结果表明,提出的adcl算法相较于传统的算法可以有效地提升协同学习效率,减少协同学习中运行时间和通信开销。
- 还没有人留言评论。精彩留言会获得点赞!