基于多智能体深度强化学习的SDN跨域智能路由方法
本发明涉及软件定义网络(software defines networking,sdn),具体涉及一种基于多智能体深度强化学习的sdn跨域智能路由方法。
背景技术:
1、近年来,随着云计算、大数据和5g网络等新技术的出现导致各种类型的多媒体服务和网络设备的快速发展,这些网络设备通常具有响应时间快、网络性能高、功能类型多等特点,以满足用户对服务质量(quality of service,qos)需求。其中,网络性能质量是满足qos需求最基本且最重要的条件,这就需要一个高效的qos感知网络架构。软件定义网络(software defines networking,sdn)作为一种新的网络架构,能将控制平面和数据平面解耦,通过sdn南向接口获取网络状态信息,sdn北向接口为上层提供应用服务,实现了对网络的集中统一控制,能够很方便获取全局网络视图,达到灵活部署路由的策略,从而提高网络性能。凭借sdn架构开放可编程、控制平面与数据平面分离等优势,许多研究者已经在数据中心网络(dcn,data center network)、流量工程(te,traffic engineering)等方面使用sdn来实现路由转发和流量管理以提高网络性能。但是,随着网络规模的增大,基于单控制器管理下的sdn网络会出现控制器负载过大和单点故障等问题,甚至会出现流量数据包堆积导致处于长时间的排队等待而得不到及时转发,从而严重影响网络性能。
2、为了解决单控制器管理模式下的大规模网络出现的性能瓶颈问题,基于多控制器模式下的分域管理已经成为一种关键性技术。基于多控制器模式下的分域管理将大规模网络划分成多个子域,在每个子域上部署所谓的本地控制器负责本域的流量管理和路由转发,通过设置增加一个具备协调全局网络功能的根控制器解决跨域的信息交换和路由转发,从而解决sdn单控制器管理模式下的大规模网络中负载过大和数据包堆积的问题。然而,基于多控制器分域管理的大规模网络中必须要解决控制器之间的消息转递和消息同步等关键性问题。传统的边界网关协议(border gateway protocol,bgp)是通过边界路由器进行相邻自治系统(autonomous system,as)之间的消息转递,实现域间的消息同步,但基于bgp的方式实现消息传递与消息同步在sdn环境中配置较为繁琐且存在路由震荡等问题。openflow1.3协议提供了一种东西向接口以实现sdn跨域路由消息的传递,但其与南北向接口标准化的广泛使用相反,东西向接口还没有形成业内一致认可的标准。虽然有部分学者在sdn东西向接口的工作中取得了一些成果,通过自适应更新控制器间的状态达到全局网络状态的一致性,有效解决了多控制器间消息传递和消息同步等问题。然而,这些基于多控制器间自适应的方式实现消息传递和消息同步,存在适应时间较长、收敛速度慢等问题,难以达到实时获取全局网络状态信息的目的。另外现有的传统域间路由方法存在数据传输不够灵活和对动态网络变化适应性较差等缺陷,导致难以获取全局网络状态信息,不能实时生成高效的跨域路由,从而影响了整体网络的性能。
技术实现思路
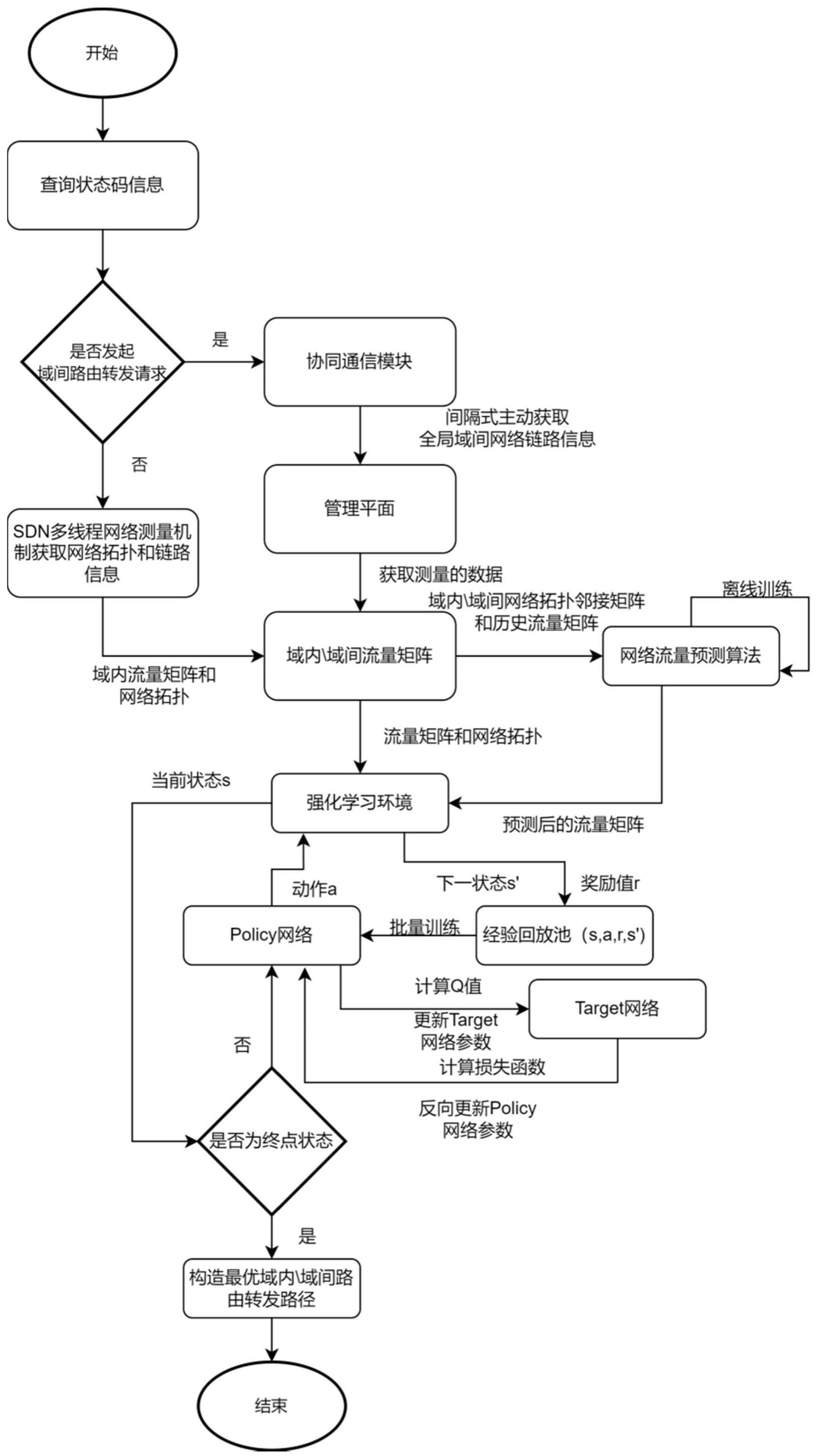
1、本发明所要解决的是软件定义网络中多控制器域间路由的消息传递和消息同步适应时间较长和可靠性差以及传统域间路由算法数据转发不够灵活的问题,提供一种基于多智能体深度强化学习的sdn跨域智能路由方法。
2、为解决上述问题,本发明是通过以下技术方案实现的:
3、基于多智能体深度强化学习的sdn跨域智能路由方法,包括步骤如下:
4、步骤1、将sdn网络划分为多个子域,并分别给sdn网络的根控制器和每个子域的本地控制器各分配一个智能体用于训练智能转发路由;
5、步骤2、当sdn网络中的一个用户需要向另一个用户传输数据时,将发送数据的用户所属子域定义为源子域,接收数据的用户所属子域定义为目的子域,除源子域和目的子域之外的其他子域定义为中间子域;
6、步骤3、源子域的本地控制器向根控制器发送tcp/ip数据报文,根控制器解析tcp/ip数据报文以查询状态码,并根据状态码判断源子域与目的子域是否为同一子域:若是,执行基于深度强化学习的域内智能转发路由;否则,执行基于深度强化学习的域间与域内智能转发路由。
7、上述步骤3中,基于深度强化学习的域内智能转发路由过程为:
8、步骤1)根控制器向源子域即目的子域的本地控制器下发域内路由指令;
9、步骤2)源子域即目的子域的本地控制器先获取域内数据平面的当前网络拓扑和当前网络状态信息来构建其智能体交互的环境;再利用该子域的本地控制器所分配的智能体与环境进行交互,并通过深度强化学习方法获得域内最优路由转发路径;
10、步骤3)源子域即目的子域的本地控制器根据域内最优路由转发路径,将tcp/ip数据报文从源ip地址通过域内的普通sdn交换机发送到目的ip地址。
11、上述步骤3中,基于深度强化学习的域间与域内智能转发路由过程为:
12、步骤1)根控制器先获取各子域管理平面的当前网络拓扑和当前网络状态信息来构建其智能体交互的环境;再利用根控制器所分配的智能体与环境进行交互,并通过深度强化学习算法获得域间最优路由转发路径;
13、步骤2)根控制器根据域间最优路由转发路径,将tcp/ip数据报文从源子域的边缘sdn交换机通过中间子域的边缘sdn交换机发送到目的子域的边缘sdn交换机;
14、步骤3)根控制器向域间最优路由转发路径上的各个子域的本地控制器下发域内路由指令;
15、步骤4)域间最优路由转发路径上的各个子域的本地控制器先获取域内数据平面的当前网络拓扑和当前网络状态信息来构建其智能体交互的环境;再利用各个子域的本地控制器所分配的智能体与环境进行交互,并通过深度强化学习方法获得域内最优路由转发路径;
16、步骤5)源子域的本地控制器将tcp/ip数据报文从源ip地址通过域内的普通sdn交换机发送到第一中间子域的边缘sdn交换机;中间子域的本地控制器将tcp/ip数据报文从上一子域的边缘sdn交换机通过域内的普通sdn交换机发送到下一子域的边缘sdn交换机;目的子域的本地控制器将tcp/ip数据报文从最后中间子域的边缘sdn交换机通过域内的普通sdn交换机发送到目的ip地址。
17、上述网络状态信息包括网络链路剩余带宽、时延、丢包率、已用带宽、弃包数和错包数。
18、上述深度强化学习方法的过程如下:
19、步骤(1)初始化决策网络的参数θ和目标网络的参数设定目标网络更新频率f,清空优先经验回放池;
20、步骤(2)智能体与环境进行交互,得到当前状态st;
21、步骤(3)智能体先将当前状态st输入到当前决策网络中得到当前状态st的q值即预测q值;再根据当前状态st的q值,通过动作选择策略得到当前动作at;
22、步骤(4)智能体执行当前动作at,并与环境进行交互,得到当前奖励值rt和下一个状态st+1;
23、步骤(5)智能体将当前状态st、当前动作at、当前奖励值rt和下一个状态st+1构成的经验元组(st,at,rt,st+1)放入优先经验回放池中,并为该经验元组分配一个优先级;
24、步骤(6)智能体从优先经验回放池中选择一批经验元组对当前策略网络进行训练,以更新当前决策网络的参数θ;
25、步骤(7)判断是否达到目标网络更新频率f:如果达到,则将当前策略网络的参数θ复制到当前目标网络的参数否则,保持当前目标网络的参数不变;
26、步骤(8)先将优先经验回放池中所有经验元组中的所有下一个状态st+1输入到当前目标网络中,得到每个下一个状态st+1的q值即目标q值;再找出目标q值最大的下一个状态st+1,并将当前状态st更新为目标q值最大的下一个状态st+1;后清空优先经验回放池;
27、步骤(9)判断当前状态st是否为最终状态:如果是,则完成深度强化学习,获得最优路由转发路径;否则,转至步骤(3)。
28、根据经验元组的选择概率从优先经验回放池选择经验元组,其中对于优先经验回放池中的第i个经验元组,其选择概率p(i)为:
29、
30、式中,priority(i)表示第i个经验元组的优先级,∑priority(j)表示所有经验元组的优先级之和,是设定的常数;ξ是设定的平衡参数,i,j=1,2,...,k,k为优先经验回放池中经验元组的个数。
31、与现有技术相比,本发明具有如下特点:
32、1、针对大规模sdn网络的分层式架构,通过将网络划分为多个子域,同时给每个子域分配一个智能体,利用分布式技术对sdn多智能体进行并发学习,以降低模型训练时间的开销。
33、2、本地控制器和根控制器中的智能体实时自适应生成当前网络状态下的域内和域间最优路由转发路径,从而有效解决了在sdn跨域路由中由于传统路由算法数据转发不够灵活而出现流量数据包堆积和网络拥塞等问题,并实现了在大规模网络中实时智能优化最优路由决策能力。
- 还没有人留言评论。精彩留言会获得点赞!