蜜罐优化方法、蜜罐防护方法以及蜜罐优化系统与流程
本发明涉及网络信息安全领域,特别涉及一种用于蜜罐优化方法、蜜罐防护方法以及蜜罐优化系统。
背景技术:
1、随着互联网技术的不断普及,日益增长的网络攻击呈现复杂化、多元化的现象。网络信息安全日益被人们关注,使用范围广、交互性强的网络无法单纯利用防火墙隔绝外来交互信息,需要采用更多样化的网络安全技术来保障网络信息安全。
2、蜜罐是一个经过精心设计的伪装计算机系统,旨在诱导并捕捉未经授权或具有恶意的系统活动。它不仅可以充当数据的收集者,收集攻击者的行为特征和策略信息;另一方面还可以充当诱饵,吸引攻击者有效地转移其注意力,确保真正的生产环境得到保护。
3、然而,现有的蜜罐在使用中,无法随着网络威胁的不断演变而持续进化,不能适应新的安全挑战。现有的蜜罐在部署后往往只能通过管理员手动更新响应策略,一方面这种升级模式有滞后性,另一方面也受管理者策略部署的主观影响。
4、因此,如何蜜罐根据攻击指令自动升级响应策略,是一个亟需解决的问题。
技术实现思路
1、针对现有技术不足,本发明提出一种蜜罐优化方法、蜜罐防护方法以及蜜罐优化系统,旨在解决现有蜜罐无法根据攻击指令自动升级优化响应策略的问题,保障蜜罐在使用中可以不断迭代升级,增加攻击者的难度,提高网络信息安全。
2、为解决上述问题,本发明实施例提供了一种蜜罐优化方法,所述方法包括:
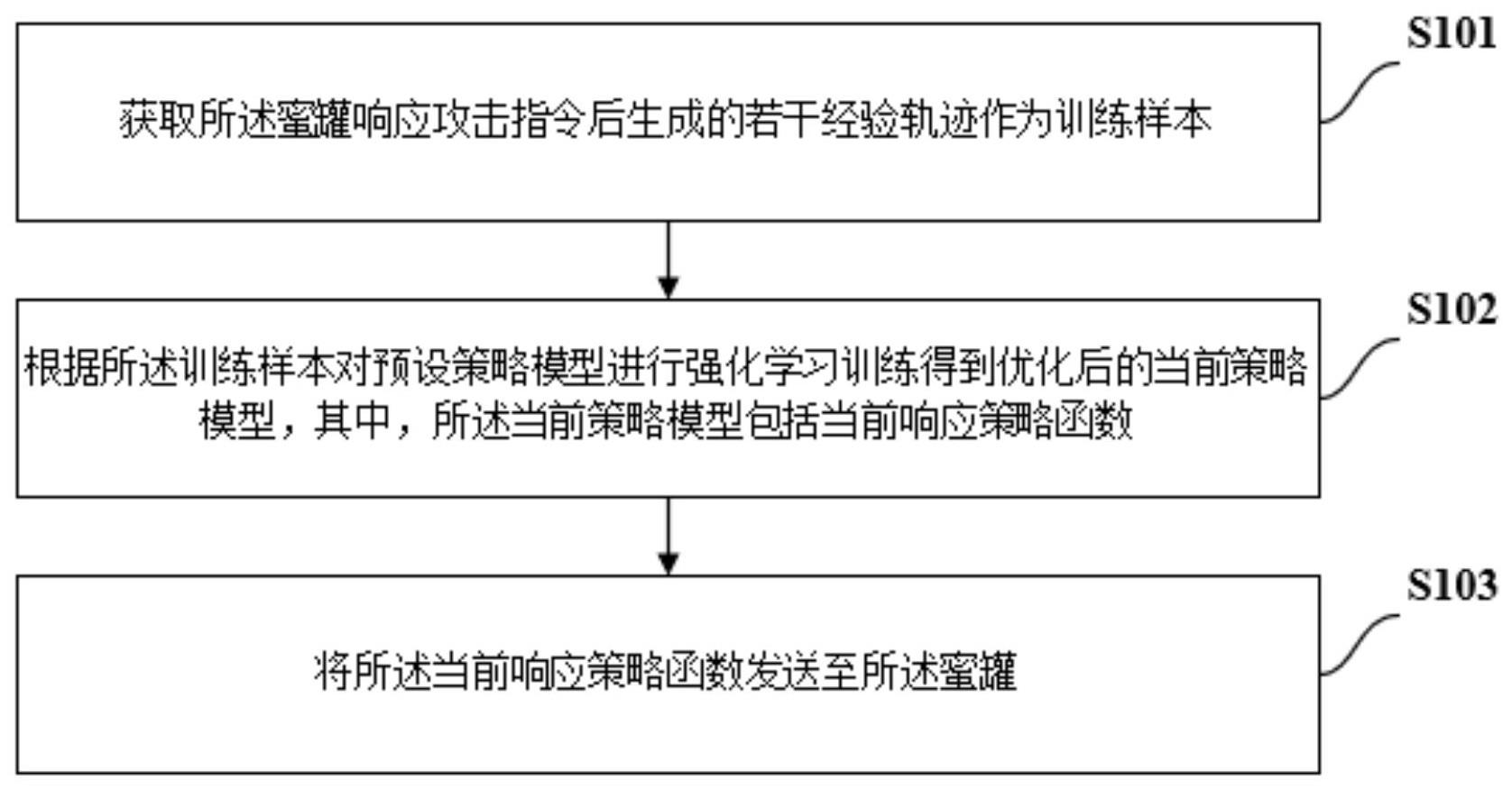
3、获取蜜罐响应攻击指令后生成的若干经验轨迹作为训练样本;所述经验轨迹包括所述蜜罐的历史状态信息和对应各历史状态信息的历史响应动作信息,其中,所述历史响应动作信息基于对应的所述历史状态信息和历史响应策略函数形成;
4、根据所述训练样本对预设策略模型进行强化学习训练得到优化后的当前策略模型,其中,所述当前策略模型包括当前响应策略函数;
5、将所述当前响应策略函数发送至所述蜜罐。
6、可选地,获取所述蜜罐响应攻击指令后生成的若干经验轨迹作为训练样本的步骤还包括:
7、判断所述若干经验轨迹是否达到预设数量;
8、在所述若干经验轨迹达到预设数量的情况下,解析所述若干经验轨迹作为所述训练样本。
9、可选地,所述预设策略模型包括奖励函数、熵影响函数、主网络的历史主动作价值函数和历史主状态价值函数以及目标网络的历史目标动作价值函数和历史目标状态价值函数,根据所述训练样本对预设策略模型进行强化学习训练得到优化后的当前策略模型的步骤包括:
10、将所述训练样本输入至所述历史目标状态价值函数、所述奖励函数以及所述熵影响函数得到所述历史目标动作价值函数;其中,所述历史目标状态价值函数表示在所述目标网络中特定状态下采取历史响应策略函数的预期状态回报,所述历史目标动作价值函数表示在所述目标网络中特定状态和特定动作下采取历史响应策略函数的预期动作回报;
11、将所述训练样本输入至所述历史主动作价值函数和所述熵影响函数得到所述历史主状态价值函数;其中,所述历史主状态价值函数表示在所述主网络中特定状态采取历史响应策略函数的预期价值回报,所述历史主动作价值函数表示在所述主网络中特定状态和特定动作下采取历史响应策略函数的预期价值回报;
12、根据所述历史主状态价值函数和所述历史目标状态价值函数按照预设比例求和作为当前目标状态价值函数,其中,所述预设比例包括第一预设比例和第二预设比例,第一预设比例和第二预设比例总和为1;
13、将当前目标动作价值函数作为所述当前策略模型的当前主动作价值函数、所述历史目标状态价值函数作为所述当前策略模型的当前目标状态价值函数以及所述历史主状态价值函数作为所述当前策略模型的当前主状态价值函数以得到优化后的所述当前策略模型。
14、可选地,在将所述训练样本输入至所述历史目标状态价值函数、所述奖励函数以及所述熵影响函数得到所述历史目标动作价值函数之后,根据所述训练样本对预设策略模型进行强化学习训练得到优化后的当前策略模型的步骤还包括:
15、将所述历史状态信息、所述历史响应动作信息输入所述历史主动作价值函数与所述熵影响函数更新所述历史主动作价值函数与所述熵影响函数中的参数;
16、将更新后的所述历史主动作价值函数与所述熵影响函数相减得到第一函数;
17、将所述第一函数作为所述当前响应策略函数;
18、根据所述第一函数更新所述熵影响函数的参数。
19、可选地,将所述训练样本输入至所述历史目标状态价值函数、所述奖励函数以及所述熵影响函数得到所述历史目标动作价值函数的步骤包括:将所述训练样本按照时序划分成第一样本数据和第二样本数据;
20、将所述第一样本数据输入至所述奖励函数得到第二函数;
21、将第二样本数据输入至所述历史目标状态价值函数和所述熵影响函数得到第三函数;
22、将所述第二函数与所述第三函数相加得到所述历史目标动作价值函数。可选地,将所述训练样本输入至所述历史主动作价值函数和所述熵影响函数得到所述历史主状态价值函数的步骤包括:
23、将所述训练样本输入至所述历史主动作价值函数和所述熵影响函数更新所述历史主动作价值函数与所述熵影响函数中的参数;
24、将更新后的所述历史主动作价值函数和所述熵影响函数作差得到所述历史主状态价值函数。
25、可选地,将所述当前响应策略函数发送至所述蜜罐的步骤包括:
26、检测所述蜜罐的连接情况;
27、将所述当前响应策略函数发送至处于连接中的所述蜜罐。
28、本发明还提供一种蜜罐防护方法,所述方法包括:
29、如上述中任一项所述的蜜罐优化方法;
30、获取接收到所述攻击指令的所述蜜罐的当前状态信息;
31、根据所述蜜罐的当前状态信息和当前响应策略函数从响应动作空间中调取对应的响应动作;其中,所述响应动作空间包括若干个不同的预设的所述响应动作;
32、生成所述响应动作的执行参数;
33、所述蜜罐按照确定执行参数后的响应动作进行所述攻击指令的响应。
34、本发明还提供一种蜜罐优化系统,所述蜜罐优化系统包括:
35、第一获取模块,用于获取蜜罐响应攻击指令后生成的若干经验轨迹作为训练样本;所述经验轨迹包括所述蜜罐的历史状态信息和对应各历史状态信息的历史响应动作信息,其中,所述历史响应动作信息基于对应的所述历史状态信息和历史响应策略函数形成;
36、优化模块,用于根据所述训练样本对预设策略模型进行强化学习训练得到优化后的当前策略模型,其中,所述当前策略模型包括当前响应策略函数;以及
37、发送模块,用于将所述当前响应策略函数发送至所述蜜罐。
38、可选地,所述第一获取模块包括:
39、判断模块,用于判断所述若干经验轨迹是否达到预设数量;以及
40、解析模块,用于在所述若干经验轨迹达到预设数量的情况下,解析所述若干经验轨迹作为所述训练样本。
41、可选地,所述预设策略模型包括奖励函数、熵影响函数、主网络的历史主动作价值函数和历史主状态价值函数以及目标网络的历史目标动作价值函数和历史目标状态价值函数,所述优化模块包括:
42、第一函数优化模块,用于将所述训练样本输入至所述历史目标状态价值函数、所述奖励函数以及所述熵影响函数得到所述历史目标动作价值函数;其中,所述历史目标状态价值函数表示在所述目标网络中特定状态下采取历史响应策略函数的预期状态回报,所述历史目标动作价值函数表示在所述目标网络中特定状态和特定动作下采取历史响应策略函数的预期动作回报;
43、第二函数优化模块,用于将所述训练样本输入至所述历史主动作价值函数和所述熵影响函数得到所述历史主状态价值函数;其中,所述历史主状态价值函数表示在所述主网络中特定状态采取历史响应策略函数的预期价值回报,所述历史主动作价值函数表示在所述主网络中特定状态和特定动作下采取历史响应策略函数的预期价值回报;
44、第三函数优化模块,用于根据所述历史主状态价值函数和所述历史目标状态价值函数按照预设比例求和作为当前目标状态价值函数,其中,所述预设比例包括第一预设比例和第二预设比例,第一预设比例和第二预设比例总和为1;
45、第一替代模块,用于将所述当前目标动作价值函数作为所述当前策略模型的当前主动作价值函数、所述历史目标状态价值函数作为所述当前策略模型的当前目标状态价值函数以及所述历史主状态价值函数作为所述当前策略模型的当前主状态价值函数以得到优化后的所述当前策略模型。
46、可选地,优化模块还包括:
47、第四函数优化模块,用于将所述历史状态信息、所述历史响应动作信息输入所述历史主动作价值函数与所述熵影响函数更新所述历史主动作价值函数与所述熵影响函数中的参数;
48、第五函数优化模块,用于将更新后的所述历史主动作价值函数与所述熵影响函数相减得到第一函数;
49、第六函数优化模块,用于将所述第一函数作为所述当前响应策略函数;
50、第二替代模块,用于根据所述第一函数更新所述熵影响函数的参数。
51、可选地,所述发送模块包括:
52、检测模块,用于检测所述蜜罐的连接情况;
53、第一子发送模块,用于将所述当前响应策略函数发送至处于连接中的所述蜜罐。
54、本发明还提供一种蜜罐防护系统,所述蜜罐防护系统包括:
55、第一获取模块,用于获取蜜罐响应攻击指令后生成的若干经验轨迹作为训练样本;所述经验轨迹包括所述蜜罐的历史状态信息和对应各历史状态信息的历史响应动作信息,其中,所述历史响应动作信息基于对应的所述历史状态信息和历史响应策略函数形成;
56、优化模块,用于根据所述训练样本对预设策略模型进行强化学习训练得到优化后的当前策略模型,其中,所述当前策略模型包括当前响应策略函数;
57、发送模块,用于将所述当前响应策略函数发送至所述蜜罐;
58、第二获取模块,获取接收到所述攻击指令的蜜罐的当前状态信息;
59、处理模块,根据所述蜜罐的当前状态信息和当前响应策略函数从响应动作空间中调取对应的响应动作;其中,所述响应动作空间包括若干个不同的预设的所述响应动作;
60、生成模块,生成所述响应动作的执行参数;以及
61、响应模块,所述蜜罐按照确定执行参数后的响应动作进行所述攻击指令的响应。
62、为了解决上述问题,本发明实施例还提供一种电子设备,所述电子设备包括:
63、至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行如上述所述蜜罐优化方法或蜜罐防护方法,和/或,如上述的所述蜜罐防护方法。
64、为了解决上述问题,本发明实施例还提供一种计算机可读存储介质,其存储计算机程序,所述计算机程序被处理器执行时实现如上述所述蜜罐优化方法或蜜罐防护方法,和/或,如上述的所述蜜罐防护方法。
65、根据上述的技术方案,本发明有益效果:
66、本发明实施例中,获取所述蜜罐响应攻击指令后生成的若干经验轨迹作为训练样本;所述经验轨迹包括所述蜜罐的历史状态信息和对应各历史状态信息的历史响应动作信息,其中,所述历史响应动作信息基于对应的所述历史状态信息和历史响应策略函数形成;根据所述训练样本对预设策略模型进行强化学习训练得到优化后的当前策略模型,其中,所述当前策略模型包括当前响应策略函数;将所述当前响应策略函数发送至所述蜜罐。通过上述方法,一方面使得蜜罐的响应策略可以根据攻击指令不断地迭代升级,另一方面优化所述响应策略的模型也在不断地迭代升级,以使蜜罐的执行的结果更加多样化,更加不容易被攻击者发现其攻击的对象为蜜罐,达到吸引攻击者注意力的目的,提高了网络安全的防护能力。解决了现有蜜罐无法自我更新策略,经过攻击者几次试探后就识别出来其攻击对象为蜜罐,从而绕开该蜜罐攻击其他系统的缺陷,全面提高了网络信息安全。
67、应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本发明。
- 还没有人留言评论。精彩留言会获得点赞!