基于扫描线并行RDOQ算法优化的硬件及流水实现方法
本发明属于视频编码领域,尤其涉及一种基于扫描线并行rdoq算法优化的硬件及流水实现方法。
背景技术:
1、rdoq是avs3视频编码中的一项重要技术,它在提升编码性能方面发挥了重要作用。视频编码中量化的目的是将信号的连续值或大量存在的离散值映射为有限多个离散值来降低码率。因此,量化过程是视频编码中产生失真的主要原因之一,从而影响这编码比特率和视频的失真率。
2、现在对于rdoq的研究主要是对算法的改进主要基于软件层面,由于rdoq的高计算复杂度和对数据的强依赖,使得其在硬件上的实现变得困难。目前还没有一个完整的rdoq硬件实现架构以达到更高的处理速度,且软件算法处理的速度达不到实时处理的要求。
3、(1)传统的最优系数决策过程中采用之字形扫描的算法,硬件设计结构吞吐受限;
4、(2)传统最优系数候选值的rd cost计算复杂度较高且存在强数据依赖,硬件时序较差;
5、(3)最优非零位置决策需迭代计算最优位置,编码实时性较差。
技术实现思路
1、本发明目的在于提供一种基于扫描线并行rdoq算法优化的硬件及流水实现方法,以解决上述的技术问题。
2、为解决上述技术问题,本发明的一种基于扫描线并行rdoq算法优化的硬件及流水实现方法的具体技术方案如下:
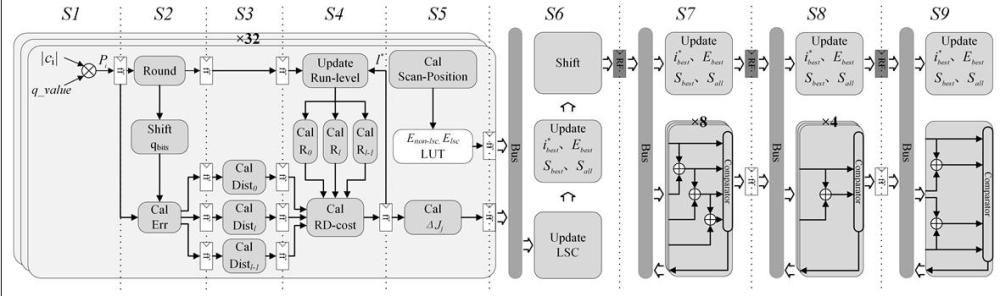
3、一种基于扫描线并行rdoq算法优化的硬件,包含9级流水线s1-s9,其中s1-s2为预量化阶段,s2-s4为ocl决策阶段,s5-s9阶段为lsc决策阶段,s1-s6在持续流水处理变换块,s7-s9阶段等待前w列处理完后再开始进行,所述硬件支持结合多个变换尺寸小于32的变换块以进行同步处理。
4、进一步的,包括如下步骤:
5、步骤1:设计预量化阶段;
6、步骤2:设计ocl决策阶段;
7、步骤3:设计lsc位置决策阶段。
8、进一步的,在预量化阶段,所有的变化系数ci将经历取绝对值,乘积与四舍五入运算,在avs3参考软件hpm-4.0中的除法运算以乘法与移位来替代,运算表达式如下:
9、pi=|ci|×qvalue,
10、li=round(pi)>>qbits,
11、其中qvalue是根据qp与变换块的尺寸来确定的,ci是变换系数,qbits是移位精度,pi是s1阶段的乘积结果,li是初始的量化等级。
12、进一步的,在ocl决策阶段,最优量化系数li*是通过比较每个候选值li的rd cost得到的,其中具有最小cost的候选值作为最优选,ocl步骤的细节如下:
13、
14、其中r和d表示rate与distortion,λ表示与qp关联的拉格朗日乘数,j是相应于候选值li计算得到的rd cost,优化rd cost的计算:
15、
16、进一步的,提出一种基于扫描线的并行ocl决策硬件结构,将原先的zigzag扫描顺序转变成列优先的多个扫描线顺序,进一步又分为右上与左下扫描线,因此单周期内所有输入系数的最优量化系数li*并行计算,而rd cost中的run-level上下文由下式计算:
17、
18、
19、其中(u,v)对应着zigzag扫描顺序的位置i,h’代表变换块的高-1,li代表位置i处的量化等级,l*i-1表示在当前i-1位置处的最优olc位置,符号!表示不操作运算。
20、进一步的,run-level上下文的获取与最优量化系数决策在一个周期内进行,并使用数据前触的方法实现这个依赖,rd cost的计算分成三个不同的流水阶段s2-s4进行,rate的计算分配到s4;
21、rate与distortion计算结构并行例化成三个独立的单元,其中distortion的计算如下式所示:
22、
23、
24、其中qbits是移位精度,pi是s1阶段的乘积结果,l是初始量化系数,j是最优量化系数候选值,sf是经拉格朗日乘数优化后的缩放因子,distortion的计算在s2-s3中完成,且两次乘法运算被拆开分配到两段流水级中;
25、一旦所有最优量化系数候选值的rd cost都计算后,值最低的被认定最优选,其对应的最优量化系数候选值将作为最优量化系数li*,随后在下一个周期去更新run-level上下文。
26、进一步的,步骤3中提出一种基于贪婪算法的lsc位置决策,在第k个扫描线的次优位置由下式获得:
27、
28、
29、其中,jj,lj*是系数等级在位置j处量化成lj*时的rd cost,jj,0是系数等级在位置j处量化成0时的distortion cost,ej,non_lsc是当位置j不是最优lsc位置时coeff_last的rate cost,ej,lsc是当位置j假定为最优lsc位置时coeff_last的rate cost,而n是当前tu中全部扫描线的数目,由w+h-1计算得到,是累加的cost,b(k)与e(k)分别代表第k条扫描线的起始坐标与结束坐标;
30、在计算得到所有扫描线的次优坐标后,最优lsc位置i*由比较次优候选值ik*得到,表达式如下所示:
31、
32、改进下-左扫描的次优位置决策公式:
33、
34、在此式中,是整条扫描线的累加cost,在迭代计算次优位置决策时应该是一个常数值存在于单条扫描线中,因此在计算次优候选值ik*
35、被消除。
36、进一步的,提出一种on-the-fly的决策方法,当处理第h(h<w)列的tu时,每个周期都会得到一个次优值,而仅需一个存储器及比较器即可完成前w条扫描线的此优化值,而剩下的h-1条扫描线的次优值将在第w个周期时同时得到,并存储至存储器内进行最优lsc位置决策。
37、进一步的,整体lsc位置决策的硬件设计被放置在s5-s9阶段,该结构可以划分成三个硬件结构:
38、第一个硬件结构紧随着ocl决策得到最小rd cost并作为最优选后,δjj,ei.lsc,enon_lsc变量的计算都规划到阶段s5,为各个扫描线的次优化值ik*
39、计算做准备;
40、第二个硬件结构是设计实现on-the-fly次优候选值决策,将用来计算前w条扫描线的最优lsc位置,该设计被规划到阶段s6,在这个阶段,一个移位存储器被引用来对齐各个扫描线的暂时计算结果,且每个周期都会得到一条完整扫描线的次优位置值,随后与先前扫描线的次优位置值相比较并决策出前w条扫描线的最优lsc位置;
41、最后一个硬件结构致力于计算出最优lsc位置,该硬件结构被规划到整体流水线的阶段s7-s9,一旦一个tu的最后一列进入到s7阶段时,所有扫描线的次优位置值都被得到,此时开始计算得到剩下h-1条扫描线的最优lsc位置,采用并行的决策进行比较,将比较周期缩减到3个,整体lsc最优位置决策仅需6+w-1+3个周期。
42、本发明的一种基于扫描线并行rdoq算法优化的硬件及流水实现方法具有以下优点:
43、本发明在保证编码失真率良好的前提下,减少了算法计算复杂度及硬件实现难度;
44、相比现有的一些算法加速方式,本发明在硬件架构进行实时并行流水rdoq处理,提高了硬件设计的吞吐率,创新度较高,并为rdoq算法在asic平台上研究提供了参考。
- 还没有人留言评论。精彩留言会获得点赞!