一种基于检索多模态辅助生成描述的视频描述方法
本发明涉及视频描述,特别是涉及基于多模态交互的视频描述方法及系统。用于日常视频中的信息与事件检索。
背景技术:
1、本部分的陈述仅仅是提到了与本发明相关的背景技术,并不必然构成现有技术。
2、视频描述(video captioning)是一种利用自然语言来自动描述视频内容的方法,近年来在计算机视觉领域引起了广泛的关注。然而,由于视频场景和对象交互的复杂性,视频描述任务具有一定的挑战性。其中的挑战包括,如何有效地利用多种特征或其他方式来表示视频内容,以及如何结合视觉和语言特征生成更详细的描述。一种常用的视频描述方法是采用编码器-解码器框架。编码器利用卷积神经网络来对视频内容进行编码,通常使用2d卷积神经网络提取外观特征,3d卷积神经网络提取运动特征,以及r-cnn用于提取对象特征。这些编码器从不同的角度捕捉视频内容,形成多模态的输入信息。输入信息中所包含的视频内容越多,生成的句子描述越准确。解码器使用递归神经网络(rnn)、长短时记忆网络(lstm)等方法对输入信息进行解码,从而生成句子描述。
3、一般来说,现有的大多数工作都存在一些缺陷:首先,由于视频内容是唯一的输入来源,生成过程缺乏适当的指导,导致生成的句子准确度较低;第二,模型的知识域在训练后是固定的,除非再次训练,否则不能扩展或再访问。
技术实现思路
1、为了解决目前大多数方案生成描述过程中缺少适当的指导和模型的知识域训练后固定的问题,本发明提供了一种基于检索多模态辅助生成描述的视频描述方法。此方法可以根据视频内容相关句子的提示下生成自然语言,而不局限于视频本身。本发明可以应用于日常视频中的信息与事件检索。
2、本发明针对现有问题,设计出一种基于检索多模态辅助生成描述的视频描述方法。其采用编码器-解码器结构,提出了一种新的检索-复制生成网络,该网络构建了可插入的视频-文本检索模块,有效地从训练语料库中检索句子,并引入了动态复制生成模块,从多检索句子中动态提取表达式。
3、本发明将视频描述分为视频-文本检索和生成描述两步:首先进行视频-文本检索,从语料库中检索相关句子;然后利用检索到的句子作为生成视频描述的额外提示或指导。这样生成器可以根据视频内容生成单词,或直接从被检索的句子中复制表达句。灵活的视频-文本检索和可变的语料库为模型的扩展或修改提供了可能。
4、本发明的技术方案是这样实现的:
5、(1)一种基于检索多模态辅助生成的视频描述方法,其特征是,包括:
6、获取待描述的视频;
7、从待描述视频中提取多模态特征;所述多模态特征包括运动特征、外观特征;
8、将多模态特征输入视频-文本检索模块,从语料库中检索与视频内容最相关的多个句子;
9、将多模态特征和检索到的多个句子作为提示输入到动态复制生成模块中;根据多模态特征生成词汇表;
10、通过选择在视频-文本检索模块中检索到的多个句子与动态复制生成模块中生成的词汇表,共同生成最适合的描述。
11、(2)如特征(1)所述的基于检索多模态辅助生成的视频描述方法,其特征是,从待描述视频中提取多模态特征,具体包括:
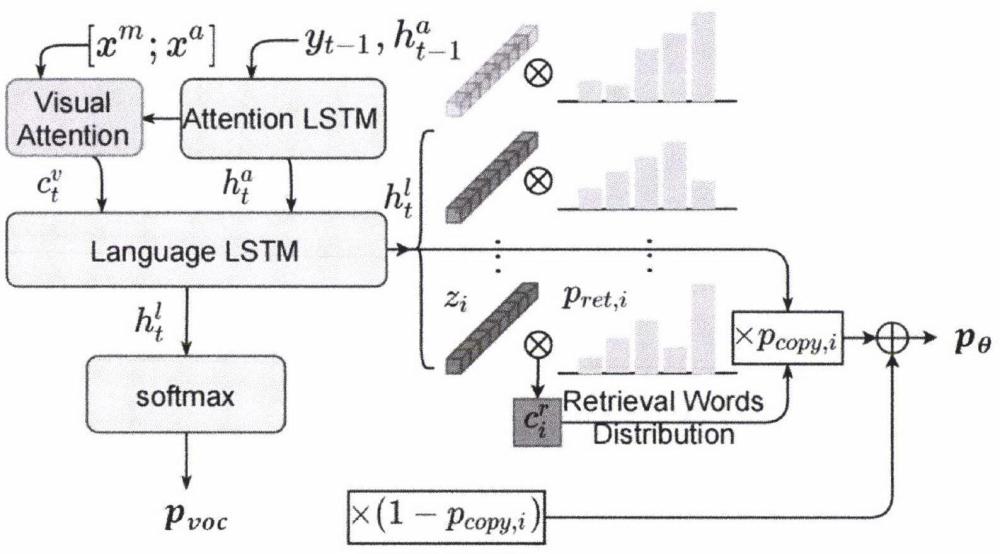
12、通过二维卷积神经网络,提取待描述视频的外观特征;
13、通过三维卷积神经网络,提取待描述视频的运动特征;
14、(3)如特征(1)所述的基于检索多模态辅助生成的视频描述方法,构建一种视频-文本检索模块,其特征是,用于处理特征(2)中提取的多模态特征:
15、视频-文本检索器采用双编码器架构;文本编码器将语料库中的所有句子映射到d维向量中,构建一个候选数据集;视觉编码器视频映射一个d维向量作为查询。
16、整个检索模型通过度量学习进行训练,将视觉和文本模式嵌入到一个联合的高维语义空间中。将视频与文本之间的相似性定义为其嵌入向量的点积,通过将相似度排序即可得到最符合要求的多个句子。
17、(4)如特征(1)所述的基于检索多模态辅助生成的视频描述方法,构建一种动态复制生成模块,其特征是,用于处理特征(2)中提取的多模态特征和特征(3)中产生的多个句子;动态复制生成模块的结构包括层级解码器和动态多指针模块。
18、(5)如特征(4)所述的动态复制生成模块,构建一个层级解码器,其特征是,由注意力lstm和语言lstm组成,根据视频内容生成固定的词汇表的概率分布,具体包括:
19、注意力lstm根据当前隐藏状态来关注不同的视觉特征x=[xm;xa],来实现视觉上下文;
20、然后,语言lstm将当前隐藏状态和视觉上下文聚合,生成每个时间步长的固定词汇表的概率分布pvoc。
21、(6)如特征(4)所述的动态复制生成模块,构建一个动态多指针模块,其特征是,为了利用如特征(3)所述得到的多个句子,在每个解码步骤中分别作用于每个检索到的句子,并生成相应句子的单词概率分布,具体包括:
22、在每个解码步骤中,多指针模块分别作用于每个检索到的句子,使用隐藏状态作为查询来加入单词,并生成对应检索句子的单词概率分布pret。
23、(7)如特征(1)所述的基于检索多模态辅助生成的视频描述方法,采用每个检索到的句子中复制单词的概率pcopy由检索到的句子的语义上下文和解码器的状态决定;
24、根据特征(5)中生成的固定的词汇表的概率分布和特征(6)得到的检索句子的概率分布,最终得到生成描述的概率分布:pθ=(1-pcopy)pvoc+pcopypret。
25、本发明中的一种基于检索多模态辅助生成描述的视频描述方法执行逻辑如下:
26、此方法主要由两个部分组成:
27、(1)带有参数η的视频-文本检索模块pη(z|x),根据视频x检索top-k个语义相似的句子z;
28、(2)带有可学习参数θ的动态复制生成模块pθ(yt|zi,x,y1:t-1),利用上述检索到的句子z、原始视觉信息x和先前的t-1生成的标记yt-1来生成当前目标标记yt。
29、形式上此方法产生视频描述的条件概率定义为:
30、
31、其中,y是带有n个标记的目标句子。
32、由于数据集通常包含语义内容相似的视频,因此相应的句子总是具有相似的形式或表达式。因此,检索到的top-k个句子z可以提供与视频内容x相关的信息,以帮助生成器更准确地生成目标句子。同时,pη(z|x)可以作为一个软阈值,表示生成模块是否可以直接从检索句子中复制单词的置信度。
33、有益效果
34、本发明提出了一种基于检索多模态辅助生成的视频描述方法。
35、本发明提出了一种多模态特征交互模块,有效的融合不同特征中相关部分,使得表示视频的输入特征含有更多的视频内容。
36、本发明将传统的基于检索的方法与传统的编码器-解码器方法进行协调,不仅可以利用检索到的句子中的不同表达,还可以生成自然、准确的视频内容。
- 还没有人留言评论。精彩留言会获得点赞!