一种云会议自适应音量均衡方法与流程
本发明涉及计算机多媒体,具体涉及一种云会议自适应音量均衡方法。
背景技术:
1、在实时音视频会议场景中,不同终端设备采集到的音频音量有不均衡的情形。例如某设备终端a出现技术问题,使得录制采集的音量过大,或者过小,或者出现严重的噪声等;这样的音量水平传输到云会议会场,可能导致各端所接收到终端a的音量水平与会议当时的平均音量水平严重不均衡,从而引起其他参会人试听的不适,严重影响试听体验。
2、dolby公司的dialog normalization(dolby dialog normalization,杜比对白归一化,dolby digital音频流中的一个 元数据(metadata)参数,可以把所有节目的平均音量都归一化到dialnorm定义的音量水平上,使用者就不需要根据节目音量水平不同而不断调整音量大小)技术,在ac3(dolby audio coding version 3 杜比ac-3音频编码格式)码流中定义了dialnorm字段,将音频录制时的音量水平预设写入该字段中;当解码端读取到dialnorm字段后,则可以根据预设值来动态调整音量水平,使得最终输出的音量水平在舒适收听范围内。然而dolby dialog normalization技术需要在dolby自有的编码器格式如ac3来实现,我们常用的opus(opus是一种广泛应用在流媒体语音通信上的音频编码格式,包含了silk和celt两种编码器,可以在编码器内部实现低比特率和高码率编码的无缝调节,且具有非常低的算法延迟,非常适合用于语音通信编码传输)、aac等开源流媒体音频格式中没有类似的字段。
3、其他的开源多媒体处理库,如webrtc,ffmpeg,freeswitch等,一般会配置音频音量的自动增益控制(agc,agc是一种用于自动调节麦克风音量水平稳定性的音频处理技术,避免因为麦克风的位置或硬件设备不同而导致声音忽大忽小声)处理或者动态范围控制(drc,drc是一种用于均衡音频音量水平的音频处理技术,通过压缩或扩大音频信号的动态范围来提高音频的试听体验)处理。但agc技术主要用于麦克风采集音量的控制上,并没有对音频输出做相应处理。而drc技术虽然能提升降低音量水平,但无法处理云会议系统的会场和入会混音音量处理等复杂场景下的音量均衡化,同时drc易引入噪音和忽高忽低的音高波动。因此在使用这些开源库的实际应用场景中,时常会遇到音量不均衡、爆音等不适体验。
4、所以,亟需一种云会议自适应音量均衡方法,来解决因输出音量异常变化,而导致终端用户试听体验较差的问题。
技术实现思路
1、本发明针对现有技术中的不足,提供一种云会议自适应音量均衡方法,以解决因输出音量异常变化,而导致终端用户试听体验较差的问题。
2、为实现上述目的,本发明采用以下技术方案:
3、一种云会议自适应音量均衡方法,其特征在于,包括如下步骤:
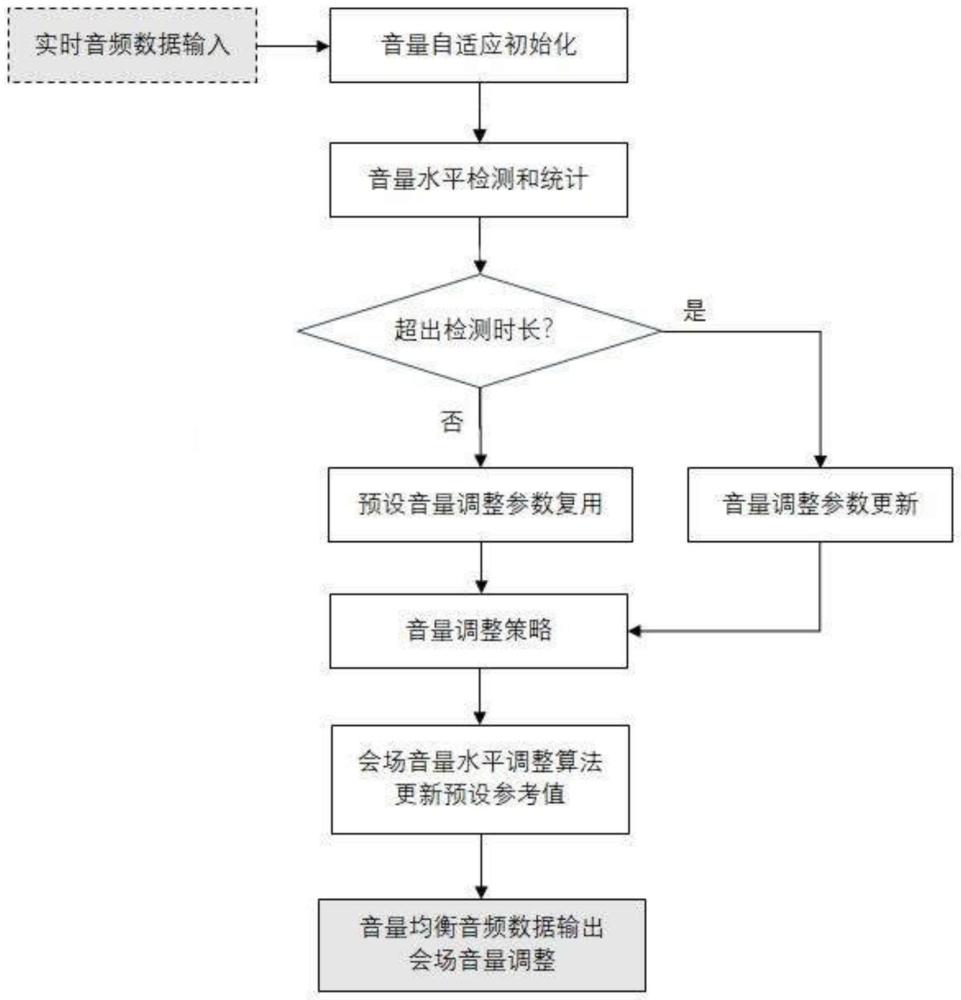
4、获取实时音频数据并进行自适应初始化,对输入的音频数据实施音量水平检测和统计,并输出音量调整参数;预设检测时长,进行是否超出检测时长的判断,当未超出检测时长内时,进行预设音量调节参数复用,音量调整策略将使用预设音量调节参数做默认调整,并输出音量均衡音频数据;当超出检测时长时,将输出的音量调整参数更新为当前的音量调整参数并输入音量调整策略,音量调整策略将使用更新后的音量调整参数实施对比决策,判断是否超出预设的调整缓冲区间,根据判断结果调整音频音量,在调整完毕后,更新调整后的音频音量值为新的音频音量参考值,输出音量均衡音频数据。
5、为优化上述技术方案,采取的具体措施还包括:
6、进一步地,所述对输入的音频数据实施音量水平检测和统计,并输出音量调整参数,具体包括如下步骤:输入音频数据,进行是否为人声的判断,当非人声时,视为背景音,计算背景音音量水平,再计算音量调整参数,并输出计算后的音量调整参数;当为人声时,计算单位时长下的音量水平值,统计并对异常数据做平滑处理,然后计算检测时长内平均的音量水平值和音量调整参数,并输出计算后的音量调整参数。
7、进一步地,所述单位时长为10ms。
8、进一步地,所述检测时长配置为5~30s。
9、进一步地,所述音量调整策略将使用更新后的音量调整参数实施对比决策,判断是否超出预设的调整缓冲区间,根据判断结果调整音频音量,在调整完毕后,更新调整后的音频音量值为新的音频音量参考值,具体包括如下步骤:
10、当更新后的音量调整参数大于预设的调整缓冲区间边界时,则做降低音量处理,或提升音量处理,并根据调整后的音频音量值更新为新的音频音量参考值;
11、当更新后的音量调整参数在预设的调整缓冲区间边界内,且小于调整缓冲区间时,则不做音量调整处理;
12、当更新后的音量调整参数在预设的调整缓冲区间边界内,且不小于调整缓冲区间时,转而设定时长下持续统计实时音量水平检测值,在累计统计时长内持续高于参考值时,做降低音量的处理,反之做提升音量的处理,并根据调整后的音频音量值更新为新的音频音量参考值。
13、进一步地,所述当更新后的音量调整参数大于预设的调整缓冲区间边界时,则做降低音量处理,或提升音量处理,之后还包括:做渐入渐出处理。
14、进一步地,所述在累计统计时长内持续高于参考值时,做降低音量的处理,反之做提升音量的处理,之后还包括:做平滑处理。
15、进一步地,所述输出音量均衡音频数据前,还包括通过音频噪声抑制算法来做消噪处理,再输出音量均衡音频数据。
16、进一步地,一种计算机可读存储介质,存储有计算机程序,其特征在于:所述计算机程序使计算机执行如上述的一种云会议自适应音量均衡方法。
17、进一步地,一种电子设备,其特征在于,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行计算机程序时,实现如上述的一种云会议自适应音量均衡方法。
18、本发明的有益效果是:
19、本发明通过预设或者实时检测分析得到云会议会场中的音频音量水平值,以此作为平均音量参考值,对混音的输入音频做音量自适应调整,使得音频音量水平在终端输出前能够保持恒定在一个试听体验舒适的动态范围中,保证音量水平的良好体验。本发明为了避免在音量水平计算中因为长时间的静默或者非人声带来的较大的偏差,加入vad算法来检测计算人声音量水平,加入音频噪声抑制算法来做消噪处理。本发明为了避免频繁的音量调整导致会场音量忽高忽低带来的不适感,对会场音量参考值上下3db边界处设定了缓冲调整区间。
技术特征:
1.一种云会议自适应音量均衡方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种云会议自适应音量均衡方法,其特征在于,所述对输入的音频数据实施音量水平检测和统计,并输出音量调整参数,具体包括如下步骤:输入音频数据,进行是否为人声的判断,当非人声时,视为背景音,计算背景音音量水平,再计算音量调整参数,并输出计算后的音量调整参数;当为人声时,计算单位时长下的音量水平值,统计并对异常数据做平滑处理,然后计算检测时长内平均的音量水平值和音量调整参数,并输出计算后的音量调整参数。
3.根据权利要求2所述的一种云会议自适应音量均衡方法,其特征在于:所述单位时长为10ms。
4.根据权利要求2所述的一种云会议自适应音量均衡方法,其特征在于:所述检测时长配置为5~30s。
5.根据权利要求1所述的一种云会议自适应音量均衡方法,其特征在于,所述音量调整策略将使用更新后的音量调整参数实施对比决策,判断是否超出预设的调整缓冲区间,根据判断结果调整音频音量,在调整完毕后,更新调整后的音频音量值为新的音频音量参考值,具体包括如下步骤:
6.根据权利要求5所述的一种云会议自适应音量均衡方法,其特征在于,所述当更新后的音量调整参数大于预设的调整缓冲区间边界时,则做降低音量处理,或提升音量处理,之后还包括:做渐入渐出处理。
7.根据权利要求5所述的一种云会议自适应音量均衡方法,其特征在于,所述在累计统计时长内持续高于参考值时,做降低音量的处理,反之做提升音量的处理,之后还包括:做平滑处理。
8.根据权利要求1所述的一种云会议自适应音量均衡方法,其特征在于,所述输出音量均衡音频数据前,还包括通过音频噪声抑制算法来做消噪处理,再输出音量均衡音频数据。
9.一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序使计算机执行如权利要求1-8任一项所述的一种云会议自适应音量均衡方法。
10.一种电子设备,其特征在于,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行计算机程序时,实现如权利要求1-8任一项所述的一种云会议自适应音量均衡方法。
技术总结
本发明公开了一种云会议自适应音量均衡方法,包括如下步骤:获取并输入音频数据,对输入的音频数据实施音量水平检测和统计,并输出音量调整参数;预设检测时长,进行是否超出检测时长的判断,未超出时,音量调整策略将使用预设音量调节参数做调整,并输出音量均衡音频数据;超出时,将输出的音量调整参数输入音量调整策略,音量调整策略使用更新后的音量调整参数判断是否超出预设的调整缓冲区间,根据判断结果调整音频音量,并更新音频音量参考值,再输出音量均衡音频数据。本发明通过预设或者实时检测分析得到会场中的音频音量水平值,以此作为平均音量参考值,对混音的输入音频做音量自适应调整,保证音量水平的良好体验。
技术研发人员:冉文波
受保护的技术使用者:中电信数智科技有限公司
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!