一种URL检测模型的训练方法、装置、设备及介质与流程
本技术涉及网络安全,尤其涉及一种url检测模型的训练方法、装置、设备及介质。
背景技术:
1、随着当前信息技术的高速发展,各行各业都不得不面对网络安全隐患问题。当用户接入网络访问不明统一资源定位器(uniform resource locator,url)或伪装为正常的恶意url时,可能就会进入网络攻击者的陷阱,导致个人信息的泄露甚至财产损失。因此,如何高效准确地检测用户访问的url是否安全,避免用户访问恶意url成为一个研究热点。
2、相关技术中,通常是使用预先训练完成的url检测模型对待检测url进行检测,从而确定该待检测url是否为恶意url。传统的url检测模型的训练过程,一般是预先标注大量的训练数据,再使用该大量的训练数据对初始url检测模型进行训练。但是,恶意url的生成速度非常快,这就意味着需要经常对url检测模型重新进行训练,以保证url检测模型能准确识别恶意url。而收集和标注训练数据是非常耗时的,从而导致每次对url检测模型重新进行训练的效率极低。
3、因此,如何提高url检测模型的训练效率成为亟待解决的问题。
技术实现思路
1、本技术实施例提供了一种url检测模型的训练方法、装置、设备及介质,用以解决现有技术中由于收集和标注训练数据耗时长,而导致url检测模型训练效率低的问题。
2、第一方面,本技术提供了一种url检测模型的训练方法,所述方法包括:
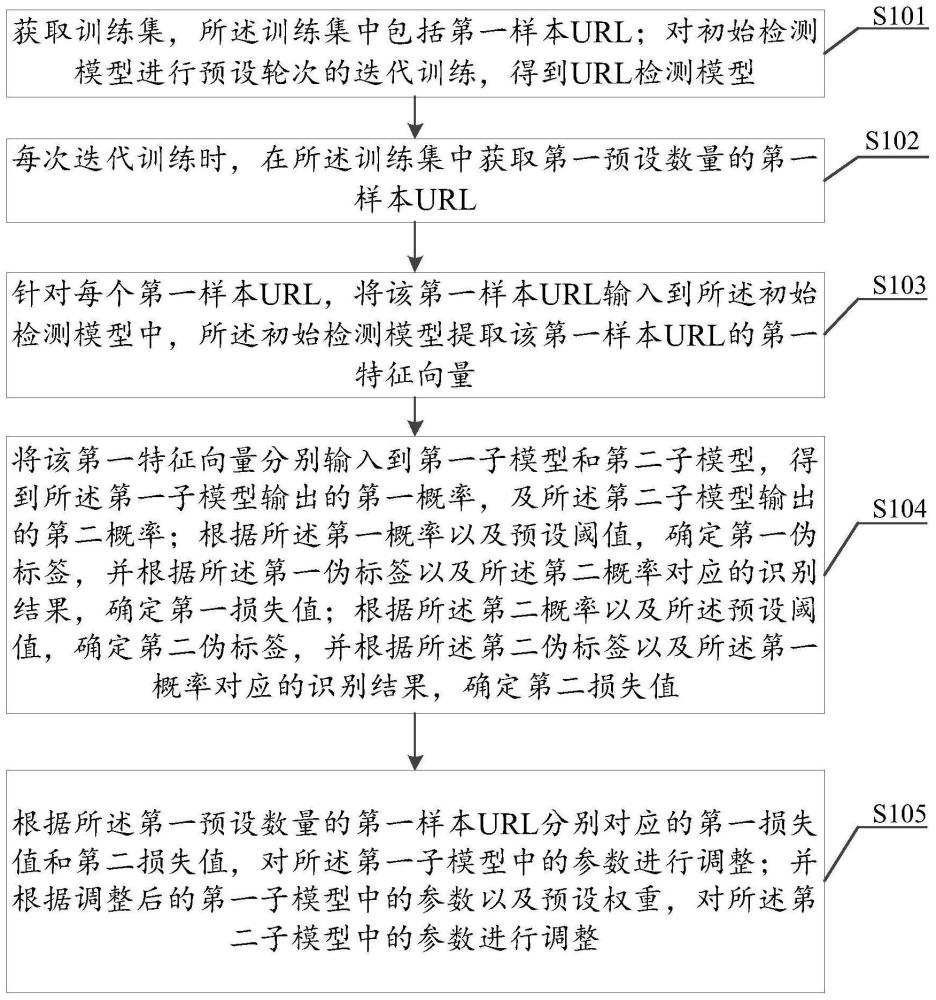
3、获取训练集,所述训练集中包括第一样本url;
4、对初始检测模型进行预设轮次的迭代训练,得到url检测模型,其中,每次迭代训练执行如下步骤:
5、在所述训练集中获取第一预设数量的第一样本url;
6、针对每个第一样本url,将该第一样本url输入到所述初始检测模型中,所述初始检测模型提取该第一样本url的第一特征向量;并将该第一特征向量分别输入到第一子模型和第二子模型,得到所述第一子模型输出的第一概率,及所述第二子模型输出的第二概率;根据所述第一概率以及预设阈值,确定第一伪标签,并根据所述第一伪标签以及所述第二概率对应的识别结果,确定第一损失值;根据所述第二概率以及所述预设阈值,确定第二伪标签,并根据所述第二伪标签以及所述第一概率对应的识别结果,确定第二损失值;
7、根据所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,对所述第一子模型中的参数进行调整;并根据调整后的第一子模型中的参数以及预设权重,对所述第二子模型中的参数进行调整。
8、进一步地,所述将该第一样本url输入到所述初始检测模型中之前,所述方法还包括:
9、根据预先保存的符号标识,对该第一样本url进行分割,将得到的每个字符串作为一个单词,并确定每个单词对应的词向量;
10、基于每个单词对应的词向量,构建该第一样本url对应的第一特征矩阵;
11、所述将该第一样本url输入到所述初始检测模型中包括:
12、将该第一样本url的所述第一特征矩阵输入到所述初始检测模型中。
13、进一步地,所述将该第一样本url输入到所述初始检测模型中之前,所述方法还包括:
14、基于爬虫技术,获取该第一样本url对应的网页的运行代码;
15、统计所述运行代码中调用每个预设函数的数量,并根据每个数量,确定对应的第一风险值,所述预设函数包括向网页中注入内容的函数、不需要检测的函数、文本匹配的函数、用于保存用户的敏感信息的函数中的至少一项;
16、统计所述运行代码中预设关键字的出现次数,并根据每个次数,确定对应的第二风险值,所述预设关键字包括保留关键字、预设语言类型对应的标准关键字、触发事件对应的关键字、修改超文本标记语言html对应的关键字中的至少一项;
17、将所述运行代码中字符串被直接赋值的数量确定为第三风险值,并将所述运行代码的熵值确定为第四风险值;
18、基于统计的每个风险值,构建该第一样本url对应的第二特征向量;
19、所述将该第一样本url输入到所述初始检测模型中包括:
20、将所述第二特征向量作为该第一样本url输入到所述初始检测模型中。
21、进一步地,所述根据所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,对所述第一子模型中的参数进行调整包括:
22、根据每个第一样本url对应的所述第一概率和所述第二概率的差,确定所述第一预设数量的第一样本url的第一检测误差;
23、根据所述第一检测误差、所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,确定第一目标损失值,并基于所述第一目标损失值对所述第一子模型中的参数进行调整。
24、进一步地,所述训练集中还包括第二样本url及对应的标签,所述标签用于标识对应的第二样本url是否为恶意url的概率;每次迭代训练时还执行如下步骤:
25、在所述训练集中获取第二预设数量的第二样本url;
26、针对每个第二样本url,将该第二样本url及对应的标签输入到所述初始检测模型中,所述初始检测模型提取该第二样本url的第三特征向量;并将所述第三特征向量输入到所述第一子模型,得到所述第一子模型输出的第三概率;并根据所述标签以及所述第三概率,确定所述第一子模型的第三损失值;
27、所述根据所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,对所述第一子模型中的参数进行调整包括:
28、根据所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,及所述第二预设数量的第二样本url分别对应的第三损失值,确定第二目标损失值,并基于所述第二目标损失值对所述第一子模型中的参数进行调整。
29、进一步地,所述确定所述第一子模型的第三损失值之后,所述根据所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,对所述第一子模型中的参数进行调整之前,所述方法还包括:
30、将所述第三特征向量输入到所述第二子模型,得到所述第二子模型输出的第四概率;
31、根据每个第二样本url对应的所述第三概率和所述第四概率的差,确定所述第二预设数量的第二样本url的第二检测误差;
32、根据所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,及所述第二预设数量的第二样本url分别对应的第三损失值,确定第二目标损失值,并基于所述第二目标损失值对所述第一子模型中的参数进行调整包括:
33、根据所述第二检测误差、所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值、所述第二预设数量的第二样本url分别对应的第三损失值,确定第三目标损失值,并基于所述第三目标损失值对所述第一子模型中的参数进行调整。
34、进一步地,所述第一子模型和所述的第二子模型的结构相同,所述根据调整后的第一子模型中的参数以及预设权重,对所述第二子模型中的参数进行调整包括:
35、针对所述第二子模型中的每个待调整参数,根据所述第二子模型中该待调整参数对应的第一参数值、所述调整后的第一子模型中该待调整参数对应的第二参数值以及对应的预设权重,确定第三参数值,并使用所述第三参数值对所述第一参数值进行更新。
36、第二方面,本技术提供了一种url检测模型的训练装置,所述装置包括:
37、获取模块,用于获取训练集,所述训练集中包括第一样本url;
38、训练模块,用于对初始检测模型进行预设轮次的迭代训练,得到url检测模型;
39、所述训练模块,具体用于在所述训练集中获取第一预设数量的第一样本url;针对每个第一样本url,将该第一样本url输入到所述初始检测模型中,所述初始检测模型提取该第一样本url的第一特征向量;并将该第一特征向量分别输入到第一子模型和第二子模型,得到所述第一子模型输出的第一概率,及所述第二子模型输出的第二概率;根据所述第一概率以及预设阈值,确定第一伪标签,并根据所述第一伪标签以及所述第二概率对应的识别结果,确定第一损失值;根据所述第二概率以及所述预设阈值,确定第二伪标签,并根据所述第二伪标签以及所述第一概率对应的识别结果,确定第二损失值;根据所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,对所述第一子模型中的参数进行调整;并根据调整后的第一子模型中的参数以及预设权重,对所述第二子模型中的参数进行调整。
40、进一步地,所述装置还包括:
41、预处理模块,用于根据预先保存的符号标识,对该第一样本url进行分割,将得到的每个字符串作为一个单词,并确定每个单词对应的词向量;基于每个单词对应的词向量,构建该第一样本url对应的第一特征矩阵;将该第一样本url的所述第一特征矩阵输入到所述初始检测模型中。
42、进一步地,预处理模块,还用于基于爬虫技术,获取该第一样本url对应的网页的运行代码;统计所述运行代码中调用每个预设函数的数量,并根据每个数量,确定对应的第一风险值,所述预设函数包括向网页中注入内容的函数、不需要检测的函数、文本匹配的函数、用于保存用户的敏感信息的函数中的至少一项;统计所述运行代码中预设关键字的出现次数,并根据每个次数,确定对应的第二风险值,所述预设关键字包括保留关键字、预设语言类型对应的标准关键字、触发事件对应的关键字、修改超文本标记语言html对应的关键字中的至少一项;将所述运行代码中字符串被直接赋值的数量确定为第三风险值,并将所述运行代码的熵值确定为第四风险值;基于统计的每个风险值,构建该第一样本url对应的第二特征向量;将所述第二特征向量作为该第一样本url输入到所述初始检测模型中。
43、进一步地,所述训练模块,具体用于根据每个第一样本url对应的所述第一概率和所述第二概率的差,确定所述第一预设数量的第一样本url的第一检测误差;根据所述第一检测误差、所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,确定第一目标损失值,并基于所述第一目标损失值对所述第一子模型中的参数进行调整。
44、进一步地,所述训练模块,具体用于在所述训练集中获取第二预设数量的第二样本url;针对每个第二样本url,将该第二样本url及对应的标签输入到所述初始检测模型中,所述初始检测模型提取该第二样本url的第三特征向量;并将所述第三特征向量输入到所述第一子模型,得到所述第一子模型输出的第三概率;并根据所述标签以及所述第三概率,确定所述第一子模型的第三损失值;根据所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值,及所述第二预设数量的第二样本url分别对应的第三损失值,确定第二目标损失值,并基于所述第二目标损失值对所述第一子模型中的参数进行调整。
45、进一步地,所述训练模块,具体用于将所述第三特征向量输入到所述第二子模型,得到所述第二子模型输出的第四概率;根据每个第二样本url对应的所述第三概率和所述第四概率的差,确定所述第二预设数量的第二样本url的第二检测误差;根据所述第二检测误差、所述第一预设数量的第一样本url分别对应的第一损失值和第二损失值、所述第二预设数量的第二样本url分别对应的第三损失值,确定第三目标损失值,并基于所述第三目标损失值对所述第一子模型中的参数进行调整。
46、进一步地,所述训练模块,具体用于针对所述第二子模型中的每个待调整参数,根据所述第二子模型中该待调整参数对应的第一参数值、所述调整后的第一子模型中该待调整参数对应的第二参数值以及对应的预设权重,确定第三参数值,并使用所述第三参数值对所述第一参数值进行更新。
47、第三方面,本技术还提供了一种电子设备,所述电子设备包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现如上述任一所述url检测模型的训练方法的步骤。
48、第四方面,本技术还提供了一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一所述url检测模型的训练方法的步骤。
49、由于在本技术实施例中,用于训练初始url检测模型的训练集中只包括第一样本url,在每次迭代训练过程中,在训练集中获取第一预设数量的第一样本url,并针对每一个样本url,将该第一样本url输入到初始检测模型中,初始检测模型提取该第一样本url的第一特征向量;并将该第一特征向量分别输入到第一子模型和第二子模型,得到第一子模型输出的第一概率,及第二子模型输出的第二概率;再根据第一概率以及预设阈值,确定第一伪标签,并根据第一伪标签以及第二概率对应的识别结果,确定第一损失值;根据第二概率以及预设阈值,确定第二伪标签,并根据第二伪标签以及第一概率对应的识别结果,确定第二损失值;根据第一预设数量的第一样本url分别对应的第一损失值和第二损失值,对第一子模型中的参数进行调整;并根据调整后的第一子模型中的参数以及预设权重,对第二子模型中的参数进行调整,实现了使用无标签的样本数据对初始url检测模型进行训练,有效的提高了模型训练的效率。
- 还没有人留言评论。精彩留言会获得点赞!