一种人体目标识别的图像压缩、解压方法和系统与流程
本发明涉及图像压缩,特别涉及一种人体目标识别的图像压缩、解压方法和系统。
背景技术:
1、目前随着短视频等行业的高速发展,图像视频数据的爆发式增长,对图像视频数据的压缩传输方式也带来了较大的挑战。现有技术中,压缩方式被分为无损压缩和有损压缩,其中无损压缩是利用数据的统计冗余进行压缩,使得压缩前后的数据并不失真,然而无损压缩通常存在压缩率上限的问题,因此无损压缩后文件还是比较大,使得高清晰度的视频图像需要的传输带宽较大。而现有的有损压缩则在原数据基础上进行整体的有损处理,虽然有损压缩的压缩包体积更小,但因此也带来了压缩后高清晰度视频、图像解压的失真问题。目前短视频、直播销售等行业主要以人体目标的为传输对象,需要对人体目标的动作图像进行更高清晰度的展示,可以更清晰凸显主播的形象。
技术实现思路
1、本发明其中一个发明目的在于提供一种人体目标识别的图像压缩、解压方法和系统,所述方法和系统利用人体目标识别算法识别图像、视频中的人体目标,并将该人体目标采用区域划分算法进行划分,将被识别的人体目标图像区域进行高清晰度的无损压缩,对剩余非人体目标图像区域进行更高压缩比的有损压缩,进一步将有损压缩和无损压进行压缩包重组,将重组的压缩包进行传输后分别进行有损和无损解压,因此可以实现人体目标的高清晰度无损解压,同时也降低了高清晰度视频图像对传输带宽的要求,利用人体目标识别算法识别的人体图像的矩形网格按照预设的网格分割算法自动进行网格分割,整体上提高了视频、图像人体网格内显示的清晰度,同时降低高清晰度视频传输的带宽压力。
2、本发明另一个发明目的在于提供一种人体目标识别的图像压缩、解压方法和系统,所述方法和系统对识别的人体目标区域图像后,按照预设的图像分割规则将人体目标区域的矩形区域分割出来,并将非人体目标区域的矩形按照人体目标边界所在位置分割成固定块数区域的图像,并对不同的区域图像采用对应的有损压缩和无损压缩分别进行压缩,并对不同区域图像进行标记,得到分割图像标记组,同时记录被分割图像的位置参数,将所述被压缩的分割图像、分割图像标记和分割图位置参数打包到压缩包中进行数据传输,在数据接收端根据所述分割图像标记和分割图位置参数分别对不同分割图像按照不同解压方式还原,并进行拼接得到凸显人体目标的图像,因此可以实现简单、高效、低带宽要求的图像视频传输。
3、本发明另一个发明目的在于提供一种人体目标识别的图像压缩、解压方法和系统,所述方法和系统在基于人体识别模型识别对应人体目标区域后,当识别的人体目标为多个时,同时对主要的人体目标进行主网格分割,对次要人体目标按照主网格边界位置进行边界延伸分割成固定个数的次要网格,对主网格内图像进行高清晰度的无损压缩,对次要网格内图像进行高倍率有损压缩,从而可以避免受到其它非主要人体图像的干扰。
4、为了实现至少一个上述发明目的,本发明进一步提供一种人体目标识别的图像压缩、解压方法,所述方法包括:
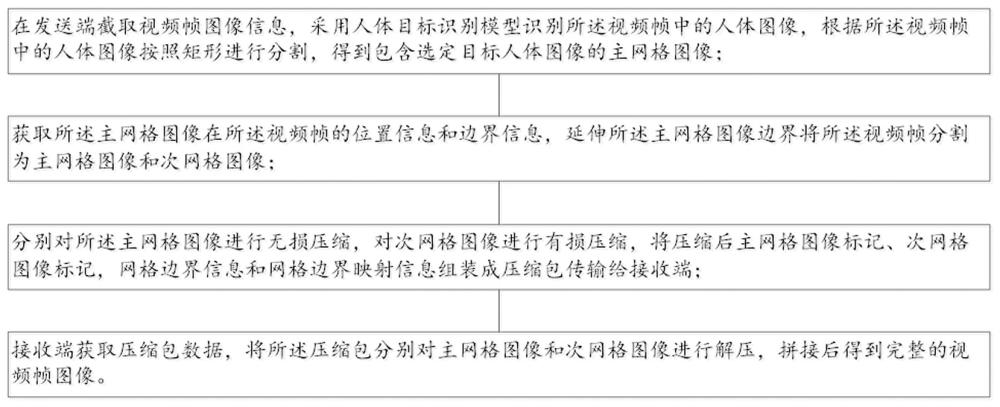
5、在发送端截取视频帧图像信息,采用人体目标识别模型识别所述视频帧中的人体图像,根据所述视频帧中的人体图像按照矩形进行分割,得到包含选定目标人体图像的主网格图像;
6、获取所述主网格图像在所述视频帧的位置信息和边界信息,延伸所述主网格图像边界将所述视频帧分割为主网格图像和次网格图像;
7、分别对所述主网格图像进行无损压缩,对次网格图像进行有损压缩,将压缩后主网格图像标记、次网格图像标记,网格边界信息和映射信息组装成压缩包传输给接收端;
8、接收端获取压缩包数据,将所述压缩包分别对主网格图像和次网格图像进行解压,拼接后得到完整的视频帧图像。
9、根据本发明其中一个较佳实施例,所述人体目标识别模型包括yolo模型,根据所述yolo模型识别所述目标人体图像,获取所述yolo模型识别目标图像所对应的矩形主网格,并获取所述矩阵主网格图像在被识别的视频帧中位置数据,根据所述主网格图像的边界信息获取对应的次网格图像。
10、根据本发明另一个较佳实施例,所述次网格图像分割方法包括:获取所述矩形主网格图像的四条边界位置数据,判断所述主网格四条边界是否在所述对应图像帧边界,若所述主网格四条边界均不在所述图像帧边界,将所述四条边界线和其中两个相对的边界的延长线作为对视频帧图像的切割线,所述延长线延长到所述视频帧图像的边缘,使得所述主网格图像的四条边界和对应的延长线将所述视频帧图像分割裁剪为一个主网格图像和四个次网格图像。
11、根据本发明另一个较佳实施例,所述次网格图像分割方法包括:根据所述主网格图像的边界信息,若当前主网格图像至少一个边界在对应的视频帧的边界上,则将不在对应视频帧边缘的主网格边界和所述不在视频帧边缘的主网格边界的延长线作为切割线对所述视频帧进行切割,得到一个主网格图像和至少一个次网格图像。
12、根据本发明另一个较佳实施例,在获取所述主网格图像和次网格图像后,分别对所述主网格图像和次网格图像进行标记,分别对标记后的主网格图像进行无损压缩,对次网格图像进行高压缩倍率的有损压缩,其中对所述次网格图像的压缩方法包括:采用高倍率的jpg图像有损压缩模式压缩算法对所述次网格图像进行压缩,将所述次网格图像的长和宽压缩至原图的四分之一,得到次网格压缩图像文件。
13、根据本发明另一个较佳实施例,所述主网格图像标记和次网格图像标记和边界位置信息获取方法包括:在每一视频帧中按照像素点位置排列建立平面直角坐标系,选定坐标系原点,按照像素点排列每个像素点均为一个坐标点,根据所述yolo模型识别所述目标人体图像对应的主网格图像边界所在的像素点位置得到所述主网格图像边界信息,并根据分割后次网格图像边界所在的像素点位置得到对应次网格图像边界信息,根据所述主网格图像和次网格图像中心点像素坐标作为对应的图像标记,并建立对应网格和边界映射关系。
14、根据本发明另一个较佳实施例,将所述分割后压缩后的主网格图像、次网格图像、网格图像标记信息、对应网格边界信息和对应网格边界映射信息组装成压缩包传输到接收终端,所述接收终端则根据所述根据所述网格标记信息提取所述主网格图像和次网格图像,分别对所述主网格图像和次网格图像进行对应解压后,根据对应网格边界信息和边界映射关系进行拼接,将和所述主网格图像存在重合或相邻边界的次网格图像边界拼接得到完整的图像信息。
15、根据本发明另一个较佳实施例,所述主网格解压方法包括:获取待解压的主网格图像包括颜色、纹理特征,将上述颜色、纹理特征进行上采样,采用邻近插值法对所述待解压的主网格图像进行超分辨率解压,得到解压后的主网格图像。
16、为了实现至少一个上述发明目的,本发明进一步提供一种人体目标识别的图像压缩、解压系统,所述系统执行上述一种人体目标识别的图像压缩、解压方法。
17、本发明进一步提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行以实现上述一种人体目标识别的图像压缩、解压方法。
技术特征:
1.一种人体目标识别的图像压缩、解压方法,其特征在于,所述方法包括:
2.根据权利要求1所述的一种人体目标识别的图像压缩、解压方法,其特征在于,所述人体目标识别模型包括yolo模型,根据所述yolo模型识别所述目标人体图像,获取所述yolo模型识别目标图像所对应的矩形主网格,并获取所述矩阵主网格图像在被识别的视频帧中位置数据,根据所述主网格图像的边界信息获取对应的次网格图像。
3.根据权利要求1所述的一种人体目标识别的图像压缩、解压方法,其特征在于,所述次网格图像分割方法包括:获取所述矩形主网格图像的四条边界位置数据,判断所述主网格四条边界是否在所述对应图像帧边界,若所述主网格四条边界均不在所述图像帧边界,将所述四条边界线和其中两个相对的边界的延长线作为对视频帧图像的切割线,所述延长线延长到所述视频帧图像的边缘,使得所述主网格图像的四条边界和对应的延长线将所述视频帧图像分割裁剪为一个主网格图像和四个次网格图像。
4.根据权利要求1所述的一种人体目标识别的图像压缩、解压方法,其特征在于,所述次网格图像分割方法包括:根据所述主网格图像的边界信息,若当前主网格图像至少一个边界在对应的视频帧的边界上,则将不在对应视频帧边缘的主网格边界和所述不在视频帧边缘的主网格边界的延长线作为切割线对所述视频帧进行切割,得到一个主网格图像和至少一个次网格图像。
5.根据权利要求1所述的一种人体目标识别的图像压缩、解压方法,其特征在于,在获取所述主网格图像和次网格图像后,分别对所述主网格图像和次网格图像进行标记,分别对标记后的主网格图像进行无损压缩,对次网格图像进行高压缩倍率的有损压缩,其中对所述次网格图像的压缩方法包括:采用高倍率的jpg图像有损压缩模式压缩算法对所述次网格图像进行压缩,将所述次网格图像的长和宽压缩至原图的四分之一,得到次网格压缩图像文件。
6.根据权利要求5所述的一种人体目标识别的图像压缩、解压方法,其特征在于,所述主网格图像标记和次网格图像标记和边界位置信息获取方法包括:在每一视频帧中按照像素点位置排列建立平面直角坐标系,选定坐标系原点,按照像素点排列每个像素点均为一个坐标点,根据所述yolo模型识别所述目标人体图像对应的主网格图像边界所在的像素点位置得到所述主网格图像边界信息,并根据分割后次网格图像边界所在的像素点位置得到对应次网格图像边界信息,根据所述主网格图像和次网格图像中心点像素坐标作为对应的图像标记,并建立对应网格边界映射关系。
7.根据权利要求6所述的一种人体目标识别的图像压缩、解压方法,其特征在于,将所述分割后压缩后的主网格图像、次网格图像、网格图像标记信息、对应网格边界信息和对应网格边界映射信息组装成压缩包传输到接收终端,所述接收终端则根据所述根据所述网格标记信息提取所述主网格图像和次网格图像,分别对所述主网格图像和次网格图像进行对应解压后,根据对应网格边界信息和网格边界映射关系进行拼接,将和所述主网格图像存在重合或相邻边界的次网格图像边界拼接得到完整的图像信息。
8.根据权利要求1所述的一种人体目标识别的图像压缩、解压方法,其特征在于,所述主网格解压方法包括:获取待解压的主网格图像包括颜色、纹理特征,将上述颜色、纹理特征进行上采样,采用邻近插值法对所述待解压的主网格图像进行超分辨率解压,得到解压后的主网格图像。
9.一种人体目标识别的图像压缩、解压系统,其特征在于,所述系统执行上述权利要求1-8中任意一项所述的一种人体目标识别的图像压缩、解压方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行以实现上述权利要求1-8中任意一项所述的一种人体目标识别的图像压缩、解压方法。
技术总结
本发明提供了一种人体目标识别的图像压缩、解压方法和系统,所述方法包括:获取视频帧图像信息,采用人体目标识别模型识别所述视频帧中的人体图像,根据所述视频帧中的人体图像按照矩形进行分割,得到包含选定目标人体图像的主网格图像;获取所述主网格图像在所述视频帧的位置信息和边界信息,延伸所述主网格图像边界将所述视频帧分割为主网格图像和次网格图像;分别对所述主网格图像进行无损压缩,对次网格图像进行有损压缩,将压缩后主网格图像、次网格图像标记和后组装成压缩包传输给接收端;接收端获取压缩包数据,将所述压缩包分别对主网格图像和次网格图像进行解压,拼接后得到完整的视频帧图像。
技术研发人员:柏壑,陈玮
受保护的技术使用者:杭州杰竞科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!