一种基于人工智能的网络安全漏洞识别方法及系统与流程
本发明涉及人工智能,并且更具体地,涉及一种基于人工智能的网络安全漏洞识别方法及系统。
背景技术:
1、随着网络和应用的复杂性增加,网络安全漏洞也相应地变得更难以识别和管理。现有的方法通常依赖于人工分析和传统的机器学习算法,这些方法不仅效率低下,而且难以适应新出现的威胁或不同类型的网络环境。
技术实现思路
1、根据本发明,提供了一种基于人工智能的网络安全漏洞识别方法及系统,以解决现有的方法通常依赖于人工分析和传统的机器学习算法,这些方法不仅效率低下,而且难以适应新出现的威胁或不同类型的网络环境的技术问题。
2、根据本发明的第一个方面,提供了一种基于人工智能的网络安全漏洞识别方法,包括:
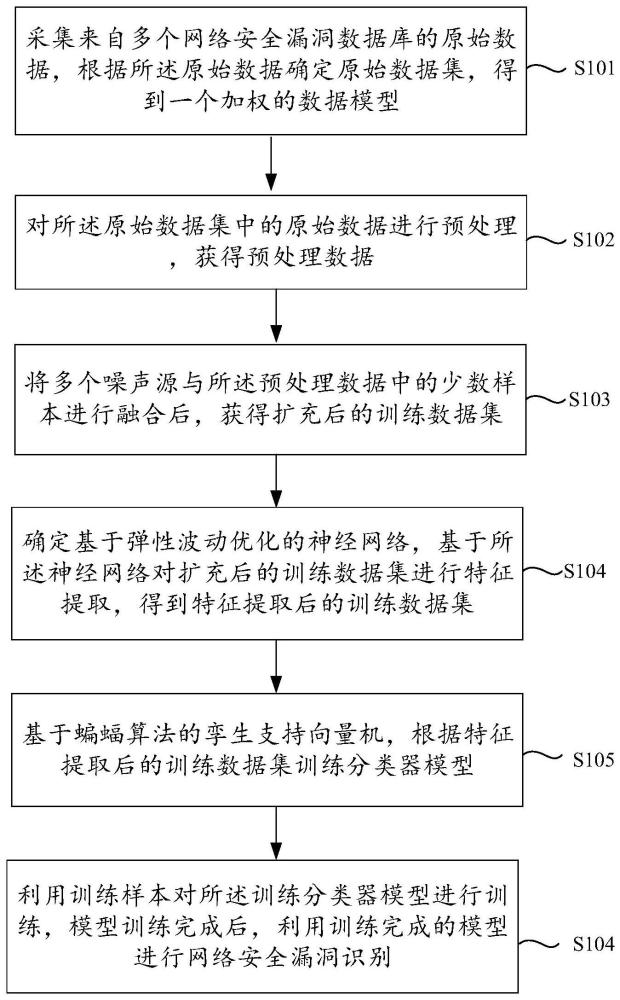
3、采集来自多个网络安全漏洞数据库的原始数据,根据所述原始数据确定原始数据集,得到一个加权的数据模型;
4、对所述原始数据集中的原始数据进行预处理,获得预处理数据;
5、将多个噪声源与所述预处理数据中的少数样本进行融合后,获得扩充后的训练数据集;
6、确定基于弹性波动优化的神经网络,基于所述神经网络对扩充后的训练数据集进行特征提取,得到特征提取后的训练数据集;
7、基于蝙蝠算法的孪生支持向量机,根据特征提取后的训练数据集训练分类器模型;
8、利用训练样本对所述训练分类器模型进行训练,模型训练完成后,利用训练完成的模型进行网络安全漏洞识别。
9、可选地,采集来自多个网络安全漏洞数据库的原始数据,根据所述原始数据确定原始数据集,得到一个加权的数据模型,包括:
10、采集来自多个网络安全漏洞数据库的原始数据,所述原始数据的数据格式为json格式,包含多个属性字段和多个数据属性;
11、根据所述原始数据确定数据集,设数据集中有n个样本,每个样本si表示为一个10维特征向量:
12、si=(idi,ti,di,sevi,atki,cvei,pdi,mdi,asi,veni>
13、其中,idi,ti,di,sevi,atki,cvei,pdi,mdi,asi,veni分别代表10个数据属性,idi为唯一标识符id,ti为漏洞标题title,di为漏洞描述description,sevi为严重性等级severity,atki为攻击类型attack_type,cvei为cve评分cve_score,pdi为发布日期published_date,mdi为最后修改日期modified_date,asi为受影响的软件affected_software,veni为软件厂商;
14、确定所述数据集的特征权重w
15、w=<wid,wt,wd,wsev,watk,wcve,wpd,wmd,was,wven),权重计算公式如下:
16、
17、其中,i(fij)是信息量函数,用于衡量第i个特征在第j个样本中的信息量;
18、对于离散属性,计算方式为:
19、i(fij)=-∑kp(fk)logp(fk)
20、对于连续属性,,计算方式为:
21、i(fij)=-∫p(f)logp(f)df
22、基于此,则得到一个加权的数据模型:
23、
24、在这个数据模型中,每个特征都被赋予了与其信息量成比例的权重。
25、可选地,对采集到的原始数据进行预处理,获得预处理数据,包括:
26、对采集到的原始数据进行向量化后,得到的向量化后的原始数据为x,其数据格式为矩阵,维度为n×m,其中n是样本数量,m是特征数量,采集到的数据的标签矩阵为y,维度为n×1;
27、对每一个特征进行z-分数归一化,表示为:
28、
29、其中,zi,j是归一化后的第i个样本的第j个特征,xi,j是原始数据中的第i个样本的第j个特征,μj和σj分别是第j个特征的均值和标准差;
30、基于信息增益的特征选择表示为:
31、ig(f)=h(y)-h(y|f)
32、其中,ig(f)是特征f的信息增益,h(y)和h(y|f)分别是标签y的熵和给定特征f后的条件熵;
33、对数据进行低维映射表示为:
34、t=xp
35、其中,t是转换后的数据矩阵,维度为n×k(k<m),p是一个m×k维的投影矩阵,获得:
36、
37、其中,wwithin和wbetween分别是类内和类间的散度矩阵。
38、可选地,将多个噪声源与所述预处理数据中的少数样本进行融合后,获得扩充后的训练数据集,包括:
39、将所述多个噪声源∈1,∈2,...,∈n与少数类样本进行融合,新的样本xnew通过以下公式生成:
40、
41、其中,wj是权重因子,与每个噪声源∈j相关联;∈j是从正态分布中抽取的噪声值;μj和σj是该正态分布的均值和标准差,xi是原始的少数类样本,xz是xi的一个邻居样本,λ是一个在[0,1]之间的随机数;
42、其中,权重因子wj是通过一个自适应机制确定的,该机制根据样本的局部密度来调整噪声强度,具体的,考虑以下优化问题:
43、
44、该优化问题的拉格朗日函数为:
45、
46、通过对wj和λ求导并令导数为0,即得到wj的确定方式:
47、
48、其中,d(xi,xz)是xi和xz之间的距离,θ是一个调节参数,并且
49、可选地,确定基于弹性波动优化的神经网络,包括:
50、定义神经网络的结构,采用多层神经网络具有l个隐藏层,对于第lth个隐藏层,该层的权重和偏置分别表示为w(l)和b(l);
51、定义神经网络的参数空间,设神经网络的参数空间为其中任一点pi由一组权重wi和一组偏置bi定义,则表示为:
52、
53、pi=(wi,bi)
54、其中,n是参数空间中点的数量;
55、定义神经网络损失函数为l(),所述损失函数为波动损失函数,表示为:
56、
57、其中,y和分别是神经网络特征提取后的特征输入到预设的softmax分类器的目标输出和实际输出,n是输入样本数量,t是当前训练迭代轮数,α_l和β_l是余弦和正弦波的振幅系数,由人为预设,ω和φ是余弦和正弦波的频率,由人为预设;
58、定义弹性常数与波动速度,确定弹性常数k和波动速度v,与网络的权重w和偏置b相关联;
59、定义弹性波动更新规则,弹性波动更新的过程即为神经网络参数更新的过程,定义一组弹性波动更新规则为:
60、
61、
62、wi+1=wi+δw
63、bi+1=bi+δb
64、其中,δt是时间步长;
65、定义震荡调整机制,震荡调整即为弹性常数k和波动速度v的调整策略,表示为:
66、k=κ_0×(1-e^(-β_zt))
67、v=v_0×e^(-γ_zt)
68、其中,κ0和v0是初始的弹性常数和波动速度,βz和γz是调整因子。
69、可选地,基于所述神经网络对扩充后的训练数据集进行特征提取,得到特征提取后的训练数据集包括:
70、步骤1:初始化神经网络参数w,b,κ,和v,设定时间步长δt;
71、步骤2:计算初始损失函数l(w,b);
72、步骤3:对于每一次迭代i:
73、步骤3.1:基于弹性波动更新规则更新w和b,对于第lth层的权重w(l)和偏置b(l),根据以下弹性波动更新规则:
74、
75、
76、
77、
78、其中,δt是时间步长;
79、步骤3.2:将应用震荡调整机制更新κ和v,对于每一层l应用震荡调整机制的更新表示为:
80、
81、
82、其中,和是第lth层的初始弹性常数和波动速度;
83、步骤3.3:重新计算损失函数l(w,b);
84、步骤4:重复迭代步骤3.1到步骤3.3,直至训练达到收敛,其中,所述收敛的判断方式为,损失值的变化δl在预设次数迭代是,不再变化,即达到收敛;述损失值的变化δl的计算依据为,在迭代过程中,考虑算法在任意迭代i和i+1之间的状态转换,损失函数l()的变化量δl表示为:
85、δl=l(wi+1,bi+1)-l(wi,bi)
86、根据弹性波动更新规则和泰勒级数展开,有:
87、
88、将更新规则代入上述方程,得:
89、
90、因为δl是负的或零,算法将保证损失函数l(w,b)下降或保持不变;
91、算法终止后,即表示该特征提取神经网络模型训练完成。
92、可选地,基于蝙蝠算法的孪生支持向量机,包括:
93、确定基于蝙蝠算法的孪生支持向量机的目标函数:
94、定义目标函数j(w1,b1,w2,b2)为:
95、
96、其中,和分别是第一个和第二个孪生支持向量机问题的损失项,α是一个平衡因子;
97、损失项和通过以下方式定义:
98、
99、
100、目标函数j(w1,b1,w2,b2)用于评价蝙蝠算法中每个解的质量,即每个蝙蝠的适应度。
101、可选地,基于蝙蝠算法的孪生支持向量机,根据特征提取后的训练数据集训练分类器模型,包括:
102、初始化蝙蝠种群:每个蝙蝠个体的位置xi被初始化为(w1,b1,w2,b2),并初始化速度vi,设置fmin和fmax分别作为蝙蝠算法中频率的最小和最大值,设置β是为[0,1]范围内的随机数;
103、评估适应度:使用目标函数j来评估每个蝙蝠个体;
104、全局最优选择:在所有蝙蝠中选择具有最低目标函数值j的蝙蝠;
105、频率调整:对于适应度较差的蝙蝠,通过调整频率f以改变搜索范围,表示为:
106、
107、速度与位置更新:更新方式表示为:
108、vi,t+1=vi,t+α×(jbest-ji)×fi
109、xj,t+1=xi,t+vi,t+1
110、其中,α为学习速率,由人为预设;
111、局部搜索与随机搜索:若新位置的适应度值比全局最佳值好,那么使用新位置作为新的全局最佳位置;
112、更新全局最佳位置:使用具有最低j的蝙蝠位置。
113、根据本发明的另一个方面,还提供了一种基于人工智能的网络安全漏洞识别系统,包括:
114、得到加权数据模型模块,用于采集来自多个网络安全漏洞数据库的原始数据,根据所述原始数据确定原始数据集,得到一个加权的数据模型;
115、获得预处理数据模块,用于对所述原始数据集中的原始数据进行预处理,获得预处理数据;
116、获得扩充训练数据集模块,用于将多个噪声源与所述预处理数据中的少数样本进行融合后,获得扩充后的训练数据集;
117、提取特征模块,用于确定基于弹性波动优化的神经网络,基于所述神经网络对扩充后的训练数据集进行特征提取,得到特征提取后的训练数据集;
118、训练分类器模型模块,用于基于蝙蝠算法的孪生支持向量机,根据特征提取后的训练数据集训练分类器模型;
119、识别安全漏洞模块,用于利用训练样本对所述训练分类器模型进行训练,模型训练完成后,利用训练完成的模型进行网络安全漏洞识别。
120、从而,从数据预处理到特征提取,再到模型训练和优化,都进行了全面和针对性的改进。通过引入创新的数据预处理算法、数据扩充方法、基于弹性波动优化的神经网络以及基于蝙蝠算法的孪生支持向量机,本发明不仅提高了网络安全漏洞识别的准确性,还增强了模型的鲁棒性和适应性。这在很大程度上解决了现有技术中的一系列问题,能够大幅提升网络安全漏洞识别的效率和准确度。
- 还没有人留言评论。精彩留言会获得点赞!