一种具有后门鲁棒性并衡量用户贡献度的联邦学习聚合算法
本发明涉及人工智能安全(ai security)、联邦学习(federated learning)、后门攻击(backdoor attack)、合作博弈论(cooperative game theory)等,尤其涉及一种具有后门鲁棒性并衡量用户贡献度的联邦学习聚合算法。
背景技术:
1、随着计算机算力的逐步提升,许多过去难以实现的人工智能算法如今已经可以得到实际应用,深度学习更是掀起了一波浪潮,许多人工智能模型更是广泛应用于人类社会,包括人脸识别、语音识别、自动驾驶等,对于人类生活有着很大的改善与便利。
2、然而,人工智能技术的发展过程中面临着两大挑战,一是隐私数据泄漏造成的数据安全问题亟待解决,二是网络安全隔离和数据隐私保护法,如欧盟所推广的通用数据保护条例(gdpr)造成不同行业、部门之间存在数据壁垒,从而形成数据“孤岛”,各部门之间数据无法安全共享,而人工智能模型想要达到比较好的性能通常需要非常大量的数据集。
3、为了解决以上问题,谷歌提出了联邦学习技术,其通过将本地数据保留至本地,而仅与中心服务器交互模型更新的方式有效地保障了用户的数据隐私安全。
4、然而联邦学习同样也面临着传统的集中式机器学习模型所会面临的安全问题,而且由于联邦学习的数据安全特性以及联邦学习的尽可能多的吸纳更多优质用户的初衷,其面临的染毒攻击或者后门攻击等恶意攻击问题更加严重,并且大量研究表明,联邦学习确实很容易受到染毒攻击或后门攻击的影响。染毒攻击会使得联邦学习的全局模型性能变差,而后门攻击会使得全局模型在附有后门的输入上输出攻击者所期望的输出,而在正常的输入上正常输出,且更具有隐蔽性。而目前大多数鲁棒性算法在防御的同时却会降低全局模型在主任务上的性能,异常更新检测算法通常在检测到异常更新后会直接抛弃该更新,那么就会浪费掉其训练所获得的数据信息。
5、此外,为了激励用户贡献更多的优质数据,并且避免用户仅提供随机模型而不贡献数据进行训练,对每个用户在每轮中所提供的模型更新进行贡献度评估是有必要,因此在联邦学习中设计贡献度度量机制是十分有研究意义的。而目前对于联邦学习中用户贡献度度量方法或激励机制的研究虽然有的考虑到了如何处理无目标的染毒攻击,却都没有很好的解决如何处理包含后门的更新,因为包含后门的更新虽然会对于包含后门的输入产生攻击者所期望的输出,但其对于联邦学习的主任务是有贡献并有所保障的,所以既应考虑其正面贡献也要对其恶意行为进行抵御以及惩罚。
技术实现思路
1、本发明的目的在于针对现有联邦学习防御攻击的方法以及贡献度度量方法的不足,提供一种既对后门攻击具有鲁棒性又能度量用户贡献度并能在一定程度上改善联邦学习训练的方法,一种具有后门鲁棒性并衡量用户贡献度的联邦学习聚合算法。本发明是通过以下技术方案来实现的:
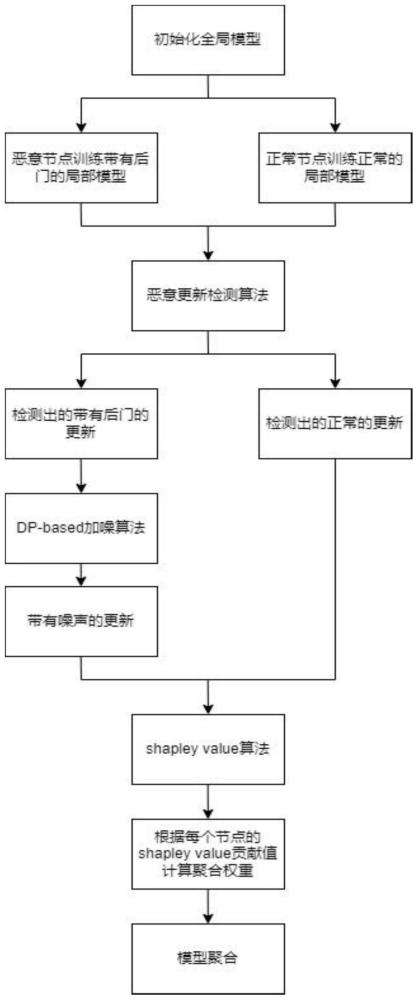
2、本发明公开了一种具有后门鲁棒性并衡量用户贡献度的联邦学习聚合算法,包括以下步骤:
3、s1中心服务器初始化一个全局模型,分发给所有参与联邦学习的用户节点;
4、s2用户节点用本地数据集来训练中心服务器所发送来的全局模型,其中正常用户节点用正常数据集进行一定轮数的训练得到更新后的局部模型,恶意节点利用其所掌控的正常数据集构建包含后门的数据集,用其所掌控的正常数据集与包含后门的数据集共同来训练得到局部模型,所有参与训练的节点将模型更新返回给中心服务器;
5、s3中心服务器运行恶意更新检测算法来检测本轮所收集到的来自用户节点的所有模型更新,检测出正常的模型更新与带有后门的模型更新;
6、s4中心服务器对检测出的带有后门的模型更新进行dp(differencial privacy)-based加噪算法,使得加噪后的模型更新的后门失效;
7、s5中心服务器对检测出的正常的更新以及加噪后的模型更新运行基于shapleyvalue的算法得到每个节点的贡献度值,并根据每个节点的贡献度值来计算出其在本轮模型聚合中所占的聚合权重;
8、s6中心服务器根据s5计算所得到的聚合权重进行模型聚合得到新的全局模型,并保留本轮所收集到的所有节点的模型更新,以便后续shapley value算法的运行;
9、s7判断联邦学习是否达到结束标准,若未达到,中心服务器将新的全局模型发送给下一轮参与联邦学习的所有节点,返回s2进行迭代,若达到则结束训练,进行结算。
10、作为进一步地改进,本发明所述的步骤s3中,恶意更新检测算法采用基于梯度的检测方法,计算所有模型更新矩阵间的余弦相似性和l2范数距离,将余弦相似性差异较大的和l2范数距离差异大的视为恶意更新,并选取合适的l2范数距离作为剪裁边界(记为cb)用于后续噪声计算,运用聚合算法将l2范数距离平均值比较大的分组中的模型更新进行裁剪以削弱其在聚合中的影响;采用基于概率统计学的方法,抽象出每个模型更新的概率分布,将概率分布较为异常的视为恶意更新。
11、作为进一步地改进,本发明所述的步骤s4中,dp-based加噪算法根据s3所得到的剪裁边界,即cb计算出合适的噪声,使得该噪声在使后门失效的前提下尽可能少地影响该模型更新对于主任务的性能表现,高斯噪声(ε,δ)-dp中的参数ε和δ可根据经验取值,而噪声σg可根据剪裁边界cb和参数ε和δ由如下公式计算得:
12、
13、作为进一步地改进,本发明所述的步骤s5中,若计算出的节点贡献度值为负,则可将其聚合权重直接置为零,同时对于提供恶意更新的节点可将其贡献值进行额外扣除作为惩罚,其中shapley value值φi的计算公式如下:
14、
15、其中n表示所有用户节点,i表示当前用户,s表示所有用户节点中不包含当前用户的任意子集,v可以是任意的评估模型效用的函数,采用对shapley value值设置一定的阈值对某些排列组合的计算进行裁剪的方法减少此步骤的计算时间,该阈值可自己根据不同环境进行实验来选定,通常比较接近于0。
16、本发明公开了一种基于差分隐私噪声的具有后门鲁棒性并衡量用户贡献度的联邦学习聚合算法,通过检测模型更新中可能存在后门的更新,对其进行加噪来消除后门,而正常更新不需要加噪,之后对所有更新利用shapley value方法计算出贡献度,根据每个更新的贡献度计算出其在聚合中所应占的权重,根据计算出来的权重进行模型聚合来更新全局模型,从而实现降低模型遭受后门攻击的风险,并度量每个节点的贡献度。对含有后门的恶意更新加噪从而消除后门在一定程度上会影响其主要训练任务的精确度,从而会降低其贡献度值,这也属于一种对于恶意节点的惩罚,最后根据每个更新的贡献度值计算每个更新的聚合权重而进行聚合而不是采用平均权重,这对于全局模型的性能提升和收敛速度会有一定帮助。本发明是一种对后门攻击具有鲁棒性的度量用户贡献度的方法,并可基于用户的贡献度度量结果改善联邦学习聚合过程。
17、本发明的有益效果如下:
18、本发明的方法通过恶意更新检测方法检测出正常更新与恶意更新,只对恶意更新进行加噪处理,这只会对恶意更新的主任务上的表现性能产生影响,进而影响后续对于其的贡献度评估,而正常更新的贡献度评估是不会受到影响的。
19、本发明的方法通过dp-based加噪算法对恶意更新进行加噪而消除其后门,而且是通过计算得到比较合适的噪声,使得在保证消除后门的影响的前提下尽可能小地减少其加噪后对于主任务的影响,使得最终所有的更新都是正常的。
20、本发明的方法通过shapley value方法度量所有节点模型更新的贡献度,中心服务器可以根据贡献度对用户节点进行奖励,并根据其贡献度计算其在全局模型聚合中的权重,比较合理地改善了fedavg(google最初所设计的平均联邦学习算法)在实际应用中无法估计节点所用数据集大小而计算聚合权重的弊端,可以比较好的提高联邦学习全局模型的性能以及提高收敛速度。
21、本发明的方法通过对输入样本求取边缘梯度之后的梯度信息进行检测来满足识别对抗样本的需求,降低遭受对抗攻击的风险,从而评估模型的鲁棒性。通过对输入图像提取边缘梯度,训练一个基于分类器的主任务模型,由于对抗样本与正常样本的梯度信息之间存在较大差异,使得对抗样本能很好地被主任务模型识别。
22、本发明为处理包含后门的模型更新的联邦学习激励机制的设计提供了一定的思路。
- 还没有人留言评论。精彩留言会获得点赞!