一种用于工业控制系统入侵检测的隐蔽个性化联邦学习方法
本发明涉及工控网络安全领域,尤其涉及一种用于工业控制系统入侵检测的隐蔽个性化联邦学习方法。
背景技术:
1、工业控制系统(industrial control systems,ics,简称工控系统)已被广泛应用于能源、交通、石油化工等工业生产领域,成为国家关键基础设施的神经中枢。人工智能、边缘计算和5g等新技术的融合应用加速了工业制造模式由传统的线性制造向基于工业物联网的智能制造迈进。然而,激增的智能终端设备和频繁的数据交换也为工业控制系统带来了重大的安全和隐私问题。
2、众多基于人工智能的入侵检测方法已被证明能够有效的缓解ics的安全威胁。然而,虽然大部分工作都取得了令人满意的效果,但它们都需要遵循一个强有力的假设,即训练数据是集中且高质量的。然而,在实践中,用户往往只拥有少量的攻击实例,并不足以构建一个理想的入侵检测模型。此外,出于商业机密的考量,大多数用户并不乐意共享这些数据,这使得模型的开发变得更加困难。鉴于这种数据隐私的挑战,联邦学习作为一种潜在的解决方案引起了越来越多的关注。然而,碎片化的ics环境为联邦学习的直接应用带来了巨大的挑战。此外,目前大部分联邦学习方案中服务器与客户端的通信方式都以传统it协议为主。虽然它们应用了各种安全加密技术来保障隐私性,但同时也很容易引起攻击者的额外关注。因此,如何构建一个更具鲁棒性和隐蔽性的联邦学习框架成为一个非常棘手的问题。
3、论文“he x,chen q,tang l,et al.cgan-based collaborative intrusiondetection for uav networks:ablockchain-empowered distributed federatedlearning approach[j].ieee internet of things journal,2022,10(1):120-132.”提出了一种基于条件生成对抗网络(cgan)的协作入侵检测算法,并结合区块链支持的分布式联邦学习来解决样本分布不均的问题。将长短期记忆(lstm)引入到cgan训练中,以提高生成网络的训练效果。利用lstm网络的特征提取能力,将cgan生成的数据作为增强数据,应用于入侵数据的检测和分类。但并没有将联邦学习参与者之间所存在的数据异质性纳入考虑。此外,此模型不适用于一些设备性能有限的工控设备代理上。
4、论文“li b,wu y,song j,et al.deepfed:federated deep learning forintrusion detection in industrial cyber–physical systems[j].ieee transactionson industrial informatics,2020,17(8):5615-5624.”提出了一种利用卷积神经网络和门控循环单元的基于深度学习的入侵检测模型。提出了基于paillier密码系统的安全通信协议,以保证模型参数在训练过程中的安全性和隐私性。其采用的密码系统需要的计算性能较高,在一些工控设备上容易出现性能不足的问题。此外,它还需要一个第三方代理来保证通信的安全性。
技术实现思路
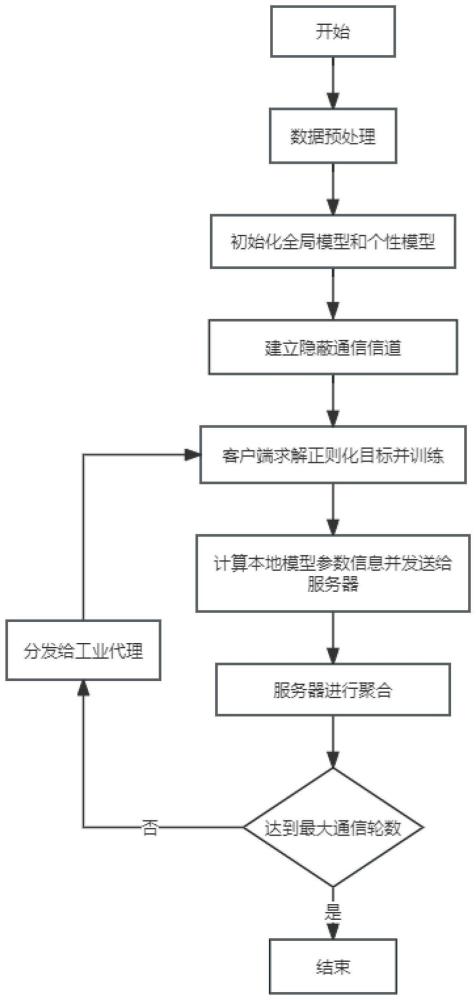
1、本发明的目的是提出一种用于工业控制系统入侵检测的隐蔽个性化联邦学习方法。该方法能够在联邦训练过程中添加客户端之间的潜在关系信息来为每个客户端创建一个专属的入侵检测模型,在客户端和服务端之间建立一条隐蔽通道,使用modbus协议来完成联邦通信过程,从而保证联邦通信的隐蔽性。
2、本发明的技术方案如下:一种用于工业控制系统入侵检测的隐蔽个性化联邦学习方法,在服务端和客户端之间增设隐蔽信道,用于服务端和客户端通信;所述服务端分发各客户端初始化的全局模型,各客户端根据所输入的数据进行训练,得到各个局部本地模型;通过正则化目标函数获得每个客户端的个性化模型;各个局部本地模型传输至服务端,服务端根据各客户端参数的重要性,聚合获得更新后的全局模型;所述全局模型再次下发至客户端进行训练;所述服务端和客户端间通信达到设定次数后,最终更新的个性化模型用于每个客户端的工业控制设备的入侵检测。
3、所述隐蔽信道为采用modbus协议进行通信的模拟信道,具体操作如下:
4、步骤2.1、制定数据交换规则:
5、服务端模拟主终端单元,客户端模拟远程终端单元;使用三种寄存器进行数据传输,分别为保持寄存器、输入寄存器和离散输入寄存器;服务端通过写保持寄存器进行模型结构和参数的分发;服务端使用读输入寄存器进行参数和其重要位置的上传;服务端使用离散输入寄存器查询客户端的训练状态;
6、步骤2.2、计算每个客户端和服务端的各种寄存器传输的参数个数:
7、
8、其中,mi为客户端i需要接收或发送的参数个数。
9、所述数据具体如下:
10、步骤3.1、将网络流量数据中的字符型特征采用独热编码的形式转化为数值型特征;
11、步骤3.2、对所有数值型特征进行标准化处理,处理公式如下:
12、
13、其中,r为原始数值型特征的特征值,μ为该数值型特征的平均值,s为该数值型特征的标准差,z为经过标准化后的特征值;
14、步骤3.3、将标准化后的特征值通过归一化映射至[0,1]区间,归一化公式如下:
15、
16、其中,zmin为该数值型特征的最小值,zmax为该数值型特征的最大值,x为经过归一化后的特征值,作为训练数据。
17、所述全局模型参数包括客户端个数n、最大通信轮数r、本地训练轮数e、学习率η、正则项系数λ、重要参数个数k;全局模型参数如下:
18、
19、其中,n表示所有的客户端;
20、全局模型为cnn+lstm结构,其包括三个不同卷积核尺寸的卷积层、拼接层、lstm层和两个全连接层;分发至各客户端的全局模型经数据训练获得训练数据x的预测值prex;以最小化正则目标函数为目标,更新参数,获得本地个性化模型;同时,以最小化客户端本地目标函数为目标,更新参数,获得局部本地模型。
21、所述获得训练数据x的预测值prex过程如下:
22、步骤5.1、输入x,将其分别输入卷积核尺寸为3、4、5的3个cnn中,使cnn在输入数据上滑动提取多个空间局部特征,计算公式如下:
23、v1=cnn1(x)
24、v2=cnn2(x)
25、v3=cnn3(x)
26、其中,cnni,i∈{1,2,3}代表第i个cnn,vi为对应cnn的隐藏向量;
27、步骤5.2、对卷积过后的所有空间局部特征进行拼接操作,计算公式如下:
28、u=concate(v1,v2,v3)
29、步骤5.3、通过一个长短期记忆人工神经网络lstm从拼接后的特征图中提取各特征之间的长期依赖关系,计算公式如下:
30、h1=lstm(u)
31、其中,h1为lstm的隐藏向量;
32、步骤5.4、将lstm隐藏向量依次通过两个全连接层fc得到输出,计算公式如下:
33、o1=fc1(h1)
34、prex=fc2(o1)
35、其中,fcj,j∈{1,2}代表第j个全连接层,o1和prex分别代表两个全连接层的输出,prex即为x的预测值。
36、所述正则化目标函数如下:
37、
38、
39、
40、
41、其中,hi为求解客户端本地个性化模型的正则化目标函数,fi是局部本地目标函数,表示全局模型,wj为客户端j的本地模型,αi,j代表局部本地模型wi和wj的相关系数;λ∈[0,+∞)为正则项系数,控制本地个性化模型和全局模型的逼近程度,当λ→+∞时,本地个性化模型pi与全局模型相近;当λ被设为0时,pi为仅基于本地数据训练的单一本地模型;
42、根据正则化目标函数获得本地个性化模型;
43、步骤6.1、更新本地个性化模型pi:
44、
45、步骤6.2、对于全局模型令更新局部本地模型
46、
47、其中,为第t轮通信第i个客户端的局部本地模型,为客户端本地训练后所得到的局部本地模型;步骤6.1和步骤6.2同步进行;
48、步骤6.3、根据基于梯度的模型参数重要程度评估方法对局部模型训练的损失变化进行计算,任意一轮的本地模型训练损失变化由模型梯度估计为:
49、
50、其中m为本地模型参数数量,代表客户端i的本地模型的第m个参数在第t轮训练的梯度,为第m个参数在本轮训练的变化量;为第m个参数对本轮损失变化的贡献;对于t轮训练,本地模型训练损失的总变化量由每轮的变化量累加得到:
51、
52、其中表示第m个本地模型参数对损失的累计贡献;
53、步骤6.4、计算每个客户端i造成损失下降的参数的重要程度:
54、
55、其中为本地模型参数m的累计变化量;
56、步骤6.5、生成重要因子向量选择前k个最大值作为第i个客户端的重要模型参数,并标记其位置:
57、
58、
59、其中是第i个客户端的参数重要程度,是重要因子向量;
60、步骤6.6、客户端通过隐蔽信道传输本地模型和重要因子向量
61、所述聚合获得更新后的全局模型具体如下:
62、步骤7.1、服务端汇总所有客户端本地模型的参数位置信息;
63、步骤7.2、计算全局模型的重要参数因子向量e={em}m∈m,其中每个元素em计算如下:
64、
65、其中,k为重要参数个数;
66、步骤7.3、获取各个客户端的本地模型重要模型参数;
67、
68、
69、步骤7.4、根据步骤7.3得到的计算各客户端本地模型之间的相关系数矩阵a={α1,...αn},αi=[αi,1,...αi,m]是经过softmax归一化后的结果;相似性计算方式如下:
70、
71、
72、其中,∏(wi,wj)代表wi和wj的所有联合概率分布集集合,γ(x,y)是x出现在wi和y出现在wj的概率;e(x,y)代表所有x和y的距离期望,其最小值即为emd距离;
73、步骤7.5、更新全局模型
74、
75、本发明的有益效果:本发明所提出的用于工业控制系统入侵检测的隐蔽个性化联邦学习方法,可以为每个客户端生成一个个性化的入侵检测模型,增强那些相似客户端之间的协作效果,提升了联邦学习的性能。选取topk个重要参数信息,压缩参数维度,降低通信压力和服务器压力,同时保证模型的准确度;具有更好的鲁棒性,能够在独立同分布和非独立同分布数据上都取得良好结果。考虑通信过程中的安全性,为服务端和客户端建立隐蔽通信方式,伪装工控设备普通通信,降低攻击者对联邦设备的关注度;该方法可以作为用于ics中的隐蔽联邦通信方案,使得执行联邦学习的设备看起来更像是一个真实ics设备,从而隐藏真正的意图,能够有效降低攻击者对联邦设备的关注度。
- 还没有人留言评论。精彩留言会获得点赞!