一种基于深度学习的边缘云故障预测加速方法与流程
本发明属于故障预测,具体涉及一种基于深度学习的边缘云故障预测加速方法。
背景技术:
1、随着万物互联时代到来以及5g通信网络普及,互联网数据规模呈现指数级增长。在此背景下,传统的云计算的中心化架构已经无法满足终端用户对于时效、容量、算力的需求。边缘云的超低时延、海量数据、边缘智能等特性促使更多的企业选择边缘云技术方案,也使得边缘云计算在市场中成为构筑在中心云与终端之间的重要组成。
2、边缘云对比中心云,不仅有着因特网、以太网、5g、wifi等复杂形态的网络构成,而且具有硬件节点形态众多、硬件配置多样性等特点。这种复杂的边缘云构成也就导致边缘云设备相对中心云等不仅往往有着更高的故障率,而且故障的发生往往有着更多的外部因素。在边缘云的运维管理部署中,对设备故障率的准确判定预测,不仅对边缘云的服务稳定性起着至关重要的作用,而且对边缘云服务商的市场盈利有着非常重要的作用。
3、在边缘云故障预测领域,深度学习尤其是transformer模型的应用至关重要,因为它们能够处理和分析大量复杂的工业数据。transformer模型,如bert,由于其高效的处理能力和准确的数据解析特性,对于边缘云故障预测非常有用。尤其是在故障预测领域,这些模型能够从海量的生产数据中提取有价值的洞察,帮助优化流程,提升效率,降低错误率,从而在边缘云故障预测领域发挥关键作用。
4、然而,在真实的边缘云系统中,深度学习模型如transformer在实时分析机器性能数据方面,模型的高计算需求和大内存消耗可能导致实时监控的延迟,影响及时发现和预防故障的能力。基于bert的模型消耗的参数空间越来越大,相应的计算资源也越来越多。比如,一个基础bert模型需要69亿次浮点操作来推断一个40个单词的句子,而使用基本seq2seq模型翻译一个20个单词的句子时,这个操作将增加到200亿次。参数空间的大小和计算需求增加了bert类模型的训练和推理的成本,对边缘云故障预测带来了显著影响。这种模型规模的扩大导致了对计算资源的巨大需求,尤其是在处理大量和复杂的工业数据时。这不仅增加了运算成本,还可能影响到系统的实时响应能力。在边缘云故障预测中,处理速度慢可能严重影响服务质量(qos)。延迟的故障检测和预测可能导致及时性差,无法迅速响应设备故障,增加系统停机时间,影响生产连续性和用户体验。这不仅会导致运营成本上升,还可能因为响应不及时而导致更严重的设备损坏。因此,对bert等大型模型的优化,在保证分析准确性的同时降低资源消耗,对于边缘云故障预测的效率和可行性至关重要。
5、对于边缘云系统的故障预测领域,transformer模型的优化不仅仅是算法层面的改进,还涉及到了整个深度学习推理框架的设计。这种优化旨在提高处理可变长度输入的效率,减少冗余计算,同时优化内存使用。尤其是在处理大规模和复杂的机器日志时,这种优化可以显著提高数据处理速度和准确性,从而加强生产线的实时监控和故障预测能力。通过这样的改进,不仅提升了边缘云故障预测系统的整体性能,也降低了运营成本,使得大型transformer模型在工业应用中更具可行性和效率。为了提高硬件效率,现有dl框架采用了批处理策略。由于批量执行要求不同批次的任务长度相同,dl框架在设计软件时假定输入长度固定。然而,这种假设并不总是成立,因为transformer模型经常面临变长输入问题。为了将具有可变长度输入的模型直接部署到仅支持固定长度模型的传统框架,一个简单的解决方案是将所有序列填充到最大序列长度(padding)。然而,这带来了对填充的冗余计算。这些填充的零还引入了显著的内存开销,可能会阻碍部署大型transformer模型。为精细的内核级优化和显式的端到端设计的dl推理框架可以避免在处理可变长度输入时对填充的浪费计算,这对大规模nlp模型的实际应用十分重要。
6、传统的基于字符的nlp模型框架在处理边缘云故障预测中出现的变长输入时存在局限性,主要具有以下的缺点:1.传统的固定长度输入限制:传统深度学习框架,如pytorch、tensorflow等,通常是为处理固定长度的输入张量而设计的。这意味着在生产线数据处理中,传统框架需要将所有数据填充至最大长度,导致计算资源浪费,影响实时数据处理效率;2.性能低下:传统框架在处理变长的机器日志和传感器数据时,处理速度较慢,影响生产效率,尤其是在需快速响应的场景下;3.复杂性:为了适应变长输入,需要进行额外的数据预处理和填充操作,增加了生产系统的复杂度;4.浪费计算资源:针对变长输入的传统方法通常会浪费计算资源,因为它们不充分利用非零元素的计算,导致性能下降;5.不适用于特定硬件:传统框架通常没有针对特定硬件的优化,导致在一些硬件平台上性能较差。
技术实现思路
1、针对以上问题,本发明提出了一种基于深度学习的边缘云故障预测加速方法,在边缘云故障预测中处理变长序列时,不仅可以释放整个transformer模型的填充部分,还提供了一套手工调优的gpu融合内核,以最小化gpu全局内存的访问成本。为解决以上技术问题,本发明所采用的技术方案如下:
2、一种基于深度学习的边缘云故障预测加速方法,包括如下步骤:
3、s1,收集历史故障数据,构建包括若干句子的故障预测文本;
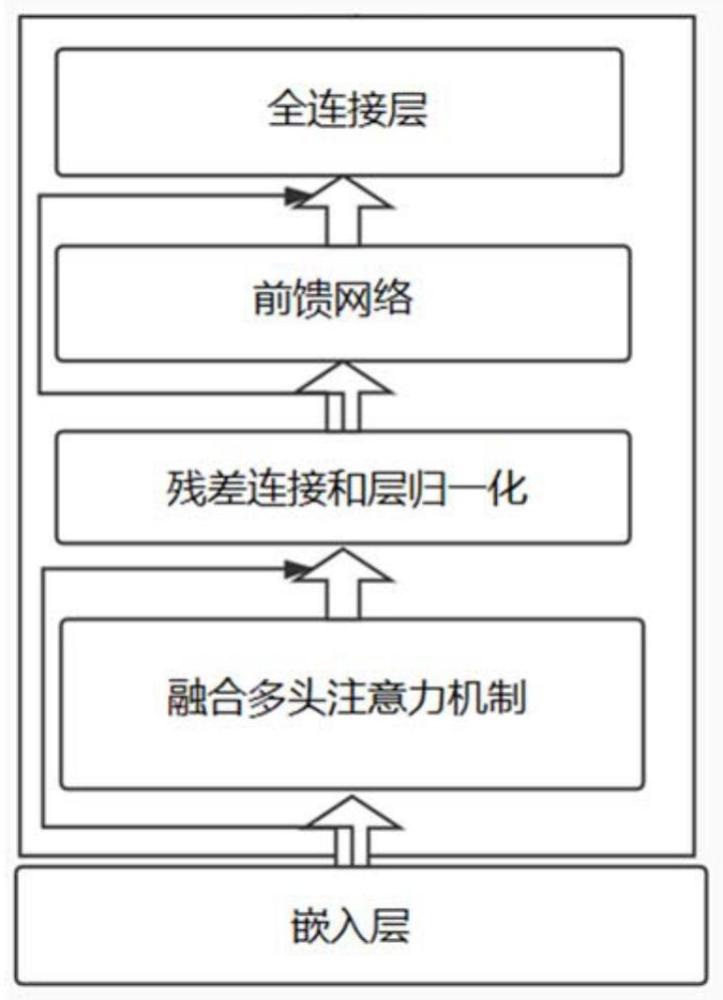
4、s2,利用变长优化算法对深度学习模型的嵌入层进行改进,将步骤s1得到的故障预测文本输入改进后的嵌入层获取等长的故障特征序列以及故障特征序列中故障信息的位置索引;
5、s3,基于预设的序列长度门限将所有的故障特征序列分别划分为长序列和短序列,同时利用fmha算子对深度学习模型的注意力层进行改进,改进后的注意力层根据步骤s2得到的位置索引对短序列进行处理,处理长序列时基于分组通用矩阵乘法对注意力矩阵乘操作任务进行线程分配,并以gpu线程块的动态负载平衡为目标构建负载优化函数对线程分配结果进行调节,分别输出短序列和长序列所对应的故障表示张量;
6、s4,利用核心融合法将归一化层和第一激活函数层进行融合,融合后的网络层基于步骤s3输出的故障表示张量中每个词元的访问频率预加载张量数据,同时利用前馈神经网络层对故障表示张量进行处理;
7、s5,利用全连接层对步骤s4输出的处理后的故障表示张量进行特征提取,并基于第二激活函数层输出故障概率分布,以对深度学习模型进行优化;
8、s6,在线收集故障数据,利用优化后的深度学习模型对边缘设备的故障进行预测。
9、所述步骤s2包括如下步骤:
10、s2.1,基于步骤s1得到的故障预测文本获取每个文本所对应的若干故障词;
11、s2.2,用变长优化算法对深度学习模型的嵌入层进行改进,将步骤s2.1得到的所述故障词转换为等长的故障数据序列,并输出故障数据序列中故障信息的位置索引;
12、s2.3,对步骤s2.2得到的等长的故障数据序列进行位置嵌入;
13、s2.4,对步骤s2.3得到的位置嵌入后的故障数据序列进行段嵌入得到故障特征序列。
14、所述步骤s2.2包括如下步骤:
15、i,利用词嵌入将故障词转换为对应的初始词序列,并对初始词序列进行填充以使所有初始词序列的长度等于填充前的最长初始词序列的长度;
16、ii,根据步骤i得到的填充后的初始词序列创建对应的掩码矩阵,并计算每个掩码矩阵的前缀和;
17、iii,根据步骤ii得到前缀和获取每个初始词序列的故障信息的位置索引以及非故障信息的位置索引,根据非故障信息的位置索引将非故障信息从每个初始词序列中移除即可得到等长的故障数据序列。
18、所述步骤s3包括如下步骤:
19、s3.1,利用fused multi-head attention(fmha)算子对深度学习模型的注意力层进行改进,基于预设的序列长度门限将所有的故障特征序列分别划分为长序列和短序列;
20、s3.2,注意力层对步骤s2输出的故障特征序列进行序列类型判断,当故障特征序列为短序列时,执行步骤s3.3,否则,执行步骤s3.4;
21、s3.3,基于短序列中故障信息的位置索引访问对应的q值、k值和v值,进而根据q值、k值和v值计算短序列所对应的故障表示张量;
22、s3.4,基于分组通用矩阵乘法对处理长序列时的矩阵乘操作任务进行gpu线程分配,同时以gpu线程块的动态负载平衡为目标构建负载优化函数对线程分配结果进行调节,输出优化后的长序列所对应的故障表示张量。
23、在步骤s3.4中,所述负载优化函数的表达式为:
24、
25、式中,n表示线程块的数量,blockn表示第n个线程块,表示更新后的长序列的总负载量,avg(·)表示均值函数,l(tj,c)表示第j个更新后的长序列执行第c个矩阵乘法操作任务tj,c时所对应的负载量。
26、在步骤s4中,所述融合后的网络层基于步骤s3输出的故障表示张量中每个词元的访问频率预加载张量数据,同时利用前馈神经网络层对故障表示张量进行处理,包括如下步骤:
27、①,确认步骤s3所输出的故障表示张量的数据访问模式;
28、②,根据步骤①得到的数据访问模式对故障表示张量的数据结构进行调整;
29、③,利用pca方法对调整故障表示张量进行识别获取故障重要信息集,根据故障重要信息集对故障表示张量在物理内存中的存储方式进行优化;
30、④,根据访问次数对存储后的故障表示张量的访问频率进行识别,基于预设的访问频率阈值确定高频访问数据;
31、⑤,将步骤④的高频访问数据从一级存储器预加载到二级存储器中,二级存储器对故障表示张量进行行计算,计算后的数据经前馈神经网络层处理后传输到输出层。
32、所述前馈神经网络层的输出的表达式为:
33、
34、式中,表示融合后的网络层的输出,w1和w2均为权重,b1和b2均为偏置;
35、所述融合后的网络层的输出的表达式为:
36、
37、式中,μ表示z的均值,σ表示z的标准差,γ和β均表示学习参数,且表示嵌入层输出的故障特征序列,表示故障表示张量。
38、本发明的有益效果:
39、1、高效的gpu加速:针对边缘云故障预测的实时数据处理需求,本技术通过gpu加速,专门优化了模型中的变长输入处理。这不仅提高了处理大规模、高频更新的工业数据的效率,还特别适用于快速准确地进行故障预测,确保系统的及时响应和稳定运行。
40、2、故障预测准确性与预测性能的平衡:在上面所提出的加速框架下,本技术还设计了专门的优化算法来保证推理加速以及预测的准确性,具体而言,设计了融合的多头自注意力(multi-head self-attention,mha)与变长计算方法,适用于处理大量传感器数据,减轻了内存负担,提高了处理速度。
- 还没有人留言评论。精彩留言会获得点赞!