基于标签共享的纵向联邦学习差分隐私保护方法及系统与流程
本发明属于数据隐私与安全,具体涉及一种基于标签共享的纵向联邦学习差分隐私保护方法及系统。
背景技术:
1、如今,人工智能技术的发展蒸蒸日上,并广泛应用于生活的方方面面,遍布日常生活、工业生产、医疗卫生等各个领域。然而,人工智能技术的发展需要庞大数据量的推动,越高精度、越优秀的模型往往越需要大量的数据来训练。因此,可以说,庞大的数据是机器学习模型训练的基础。而在实际中,数据可能分布在各个移动设备或者不同拥有者手上。一个独立的机构所拥有的数据量是有限的,也很难训练出理想的模型。数据共享的需求应运而生。但是随着对数据的隐私与安全问题日益注重,同时数据的价值也日益增加,数据拥有者尤其是个人对于分享敏感、隐私数据的意愿日益降低。而对于公司而言,不可能轻易与其他公司共享隐私数据。在法律方面,隐私数据保护问题也被落实到法律法规中。那么如何在保证隐私数据安全,且满足各参与方意愿的情况下,合法共同训练一个模型就成为了问题。
2、针对这个问题,2016年,谷歌提出了联邦学习,在联邦学习的框架下,通过建立一个全局模型解决不同数据拥有方在不交换数据的情况下进行协作的问题。
3、在联邦学习隐私保护中,纵向联邦学习与横向联邦学习的不同在于,横向联邦学习拥有模型完整的数据特征,包括数据标签,但数据样本不足。在具有完整数据标签的情况下,可以采用正常的机器学习算法训练出一个完整的模型。而纵向联邦学习的数据特征是零散的,分布在各个参与方手上,仅有限个参与方有数据标签,不具备数据标签的参与方无法独立训练一个完整的模型或者只能采用无监督学习的方法。因此,一般会采用加密交换来达成数据共享,但需要多次通信,通信成本高且计算和内存开销大。纵向联邦学习也可以说是按照特征划分的联邦学习,各方的用户群体相似,但获得的用户特征不同。纵向联邦学习使得参与者在对齐样本后,使用分散特征共同训练机器学习模型,且不暴露自身的原始数据。
4、尽管纵向联邦学习在某种程度上保证了安全性,由于参与方之间互不信任,为了保证各自的数据安全性,在进行参数共享的时候选择加密共享,但基于加密交换的纵向联邦学习往往需要多次通信,会产生昂贵的通信成本且加密会带来高昂的计算成本。
技术实现思路
1、本发明的目的在于针对上述现有技术中的问题,提供一种基于标签共享的纵向联邦学习差分隐私保护方法及系统,通过在数据标签和汇聚梯度上添加满足差分隐私的噪声,在保护参与方数据隐私的同时,减少通信代价和计算成本。
2、为了实现上述目的,本发明有如下的技术方案:
3、第一方面,提供一种基于标签共享的纵向联邦学习差分隐私保护方法,包括:
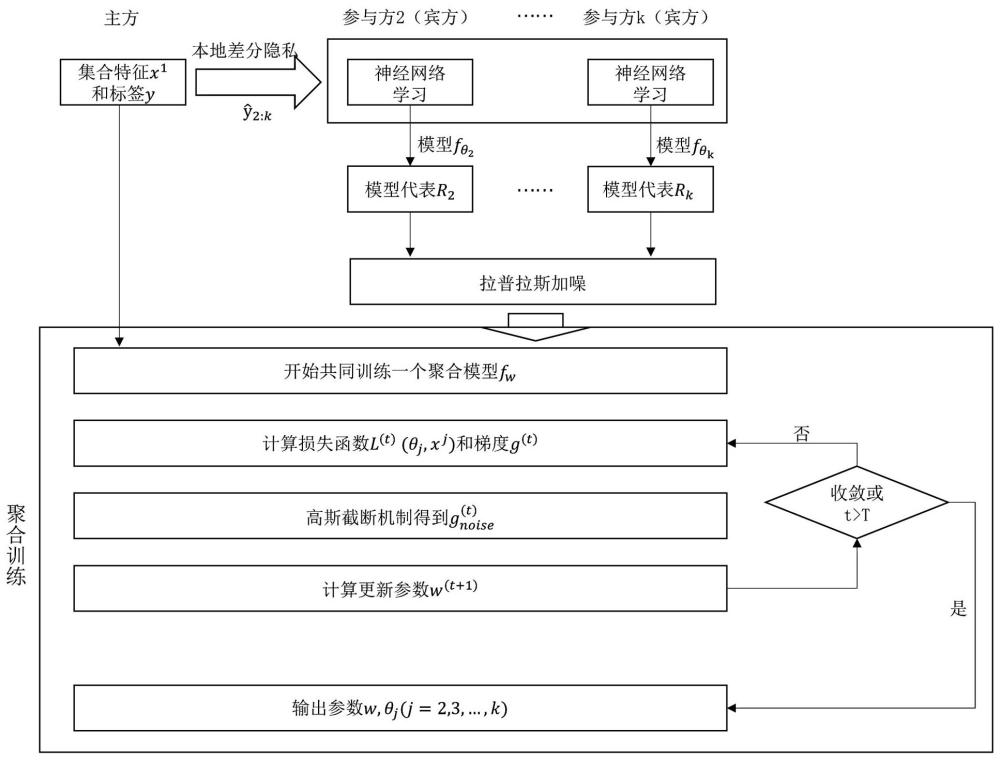
4、对主方的标签数据进行差分隐私加噪扰动,得到扰动后的标签数据,并将扰动后的标签数据共享给各个来宾方;
5、各个来宾方利用接收到的标签数据进行本地模型参数训练;
6、本地模型参数训练好之后,各个来宾方将本地模型参数进行差分隐私加噪扰动后发送给主方;
7、主方结合各个来宾方差分隐私加噪扰动后的本地模型参数和自身的模型数据进行聚合训练,获得差分隐私加噪扰动后的学习模型。
8、作为一种优选的方案,由主方与各个来宾方所有数据组成的全局数据集为,式中 n为样本数量,假设样本的特征分布在 m个来宾方中,即,仅有一个主方有标签,当主方结合各个来宾方差分隐私加噪扰动后的本地模型参数和自身的模型数据进行聚合训练,获得差分隐私加噪扰动后的学习模型时,由主方与各个来宾方组成参与方,其中,每个参与方均拥有本地数据集,通过所有来宾方与主方协同合作训练一个模型,式中指所训练模型的参数;
9、训练过程表达式为:
10、
11、式中,是损失函数,是正则项。
12、作为一种优选的方案,对主方的标签数据进行差分隐私加噪扰动,得到扰动后的标签数据,并将扰动后的标签数据共享给各个来宾方包括:
13、标签数据分桶,统计主方原始的数据标签分布;使用 k-rr本地差分隐私加噪扰动数据标签,假设标签有 k种结果,对于任意输入 r,以的概率响应真实的结果,以的概率响应到其余 k-1个结果;设共享给来宾方 j的最终的扰动结果为;其中:
14、
15、如果,第个来宾方样本的唯一标识符为,则主方将所拥有样本数据的发送给其余各来宾方,来宾方根据标识符配对,得到;为所消耗的隐私代价,通过设置隐私代价的大小控制隐私保护程度。
16、作为一种优选的方案,各个来宾方利用接收到的标签数据进行本地模型参数训练包括:
17、计算损失函数和梯度:
18、
19、
20、式中,为来宾方的参数,为来宾方在第 t轮的模型函数,为来宾方接收到的加噪后的标签数据,为损失函数的f范式平方,则表示梯度求导函数;
21、进行参数更新,为学习率:
22、
23、式中,为来宾方 j在第 t+1轮的参数,为来宾方 j在第 t轮的参数,为第 t轮的学习率;
24、直到收敛或达到设置的最大阶段数,得到模型,式中,为来宾方 j的模型代表,为参数为的模型函数。
25、作为一种优选的方案,本地模型参数训练好之后,各个来宾方将本地模型参数进行差分隐私加噪扰动后发送给主方包括:
26、对来宾方训练出的模型参数进行正则裁剪,引入裁剪阈值,使得,即:
27、
28、式中,为来宾方 j经过正则裁剪后的参数,为模型参数的第一范式;
29、添加满足拉普拉斯机制的噪声,即:
30、
31、式中,为参与方 j加噪后的参数,为拉普拉斯机制函数,为隐私代价;
32、得到模型参数,并将其发送给主方,式中,为来宾方 j的模型代表,为加噪参数的模型函数。
33、作为一种优选的方案,主方结合各个来宾方差分隐私加噪扰动后的本地模型参数和自身的模型数据进行聚合训练,获得差分隐私加噪扰动后的学习模型包括:
34、计算损失函数和梯度:
35、
36、
37、式中,为第 t轮的损失函数,为模型训练的参数,为参与方1的特征数据,为了方便,将表示为,为所有来宾方本地训练得到的模型代表结果,为在第 t轮中训练参数 w的模型函数,为主方的真实标签数据;
38、利用高斯截断机制保护梯度信息,其中噪声大小为,为学习率:
39、
40、
41、
42、式中,为在第 t轮经过正则裁剪后的梯度,为第 t轮梯度的二范式,为第 t轮加噪后的梯度,表示均值为0且方差为的高斯函数,为单位向量,为第 t+1轮的参数;
43、输出各个来宾方的加噪学习模型参数以及主方的加噪学习模型参数。
44、第二方面,提供一种基于标签共享的纵向联邦学习差分隐私保护系统,包括:
45、标签共享模块,用于对主方的标签数据进行差分隐私加噪扰动,得到扰动后的标签数据,并将扰动后的标签数据共享给各个来宾方;
46、来宾方本地模型训练模块,用于各个来宾方利用接收到的标签数据进行本地模型参数训练;
47、来宾方模型参数传输模块,用于本地模型参数训练好之后,各个来宾方将本地模型参数进行差分隐私加噪扰动后发送给主方;
48、主方模型聚合训练模块,用于主方结合各个来宾方差分隐私加噪扰动后的本地模型参数和自身的模型数据进行聚合训练,获得差分隐私加噪扰动后的学习模型。
49、第三方面,提供一种电子设备,包括:
50、存储器,存储至少一个指令;及处理器,执行所述存储器中存储的指令以实现所述基于标签共享的纵向联邦学习差分隐私保护方法。
51、第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现所述基于标签共享的纵向联邦学习差分隐私保护方法。
52、相较于现有技术,本发明至少具有如下的有益效果:
53、由于参与方之间互不信任,为了保证各自的数据安全性,在进行参数共享的时候选择加密共享,但基于加密交换的纵向联邦学习往往需要多次通信,会产生昂贵的通信成本且加密会带来高昂的计算成本。本发明适用于数据模型纵向联邦学习的差分隐私保护方法,通过在数据标签和汇聚梯度上添加满足差分隐私的噪声,减小了计算和内存开销。在模型参数汇聚过程中为了预防攻击者的重构攻击,对梯度信息添加噪声以防止信息的泄露。采用训练完整本地模型再加噪参数共享本地模型的方法,减少了通信次数进而降低了通信成本。
- 还没有人留言评论。精彩留言会获得点赞!