一种基于机器学习的社区爬虫行为识别方法及系统与流程
本发明涉及网络安全,尤其涉及一种基于机器学习的社区爬虫行为识别方法及系统畜。
背景技术:
1、随着互联网的迅速发展和大数据时代的兴起,网络爬虫的应用范围逐渐扩展,不仅在商业领域有广泛应用,还在社区和特定领域发挥着重要作用。然而,爬虫行为可能引发数据隐私泄露、服务器过载等一系列问题,因此对其行为进行有效识别和分析至关重要。当前,市面上的传统爬虫识别方法多基于事先设定的规则,但对于行为复杂多变的社区场景中的爬虫,这些方法通常难以有效识别。
2、因此,如何提供一种有效的爬虫行为识别方法,对复杂多变的爬虫行为进行高效、精确的识别是目前有待解决的技术问题。
技术实现思路
1、本发明的目的是提供一种基于机器学习的社区爬虫行为识别方法,包括:
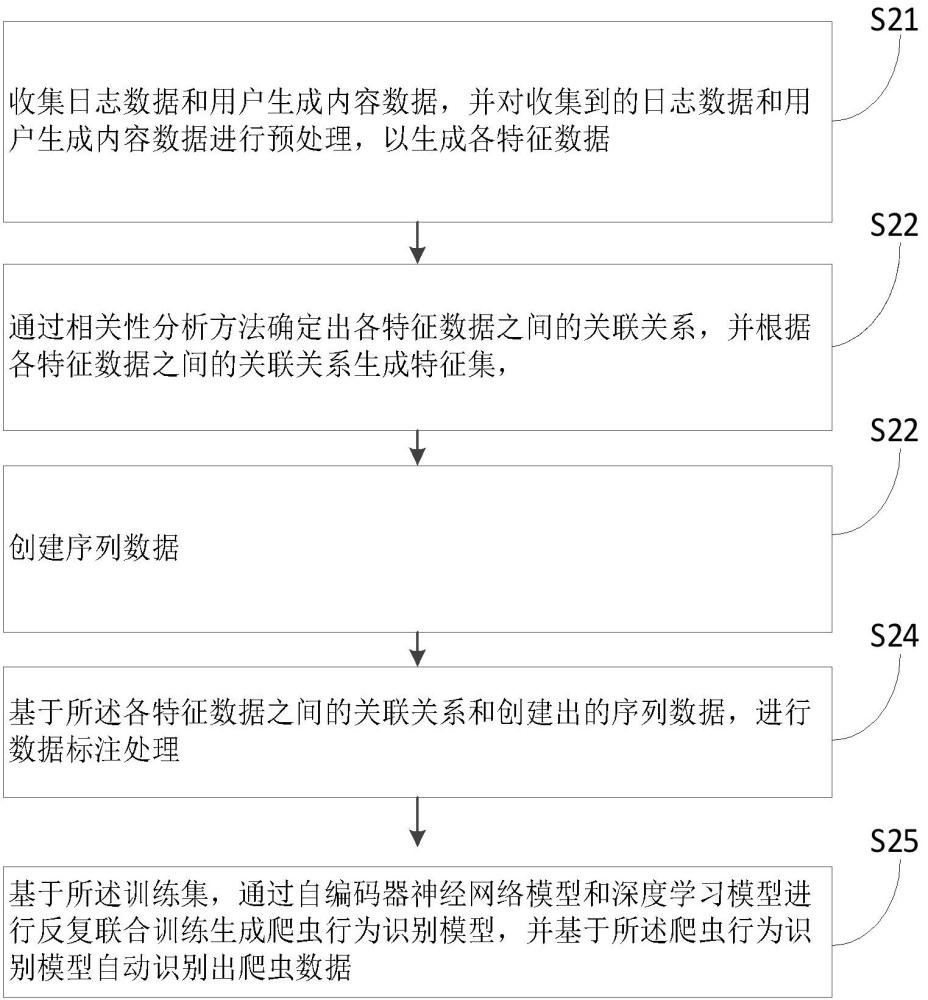
2、收集日志数据和用户生成内容数据,并对收集到的日志数据和用户生成内容数据进行预处理,以生成各特征数据,所述日志数据包括访问日志数据、错误日志数据和安全日志数据,所述用户生成内容数据至少包括文章标题、内容文章、发布时间和/或文章标签;
3、通过相关性分析方法确定出各特征数据之间的关联关系,所述各特征数据之间的关联关系包括与爬虫行为相关联的特征数据,以及与用户发帖行为相关联的特征数据;
4、创建序列数据,所述序列数据包括访问序列数据和内容序列数据,所述访问序列数据为收集到的日志数据在时间上的排序,所述内容序列数据为用户生成内容在时间上的排序,所述内容序列数据用于捕获用户的发帖数据随时间的变化情况;
5、基于所述各特征数据之间的关联关系和创建出的序列数据,进行数据标注处理,所述数据标注处理为对与爬虫行为相关联的特征数据进行第一数据标记,以及对识别出的与用户发帖行为相关联的特征数据进行第二数据标记,对进行标记的第一数据和第二数据生成数据集,并将所述数据集按照预设比例分为训练集和测试集,所述训练集和测试集中的数据均包括访问序列数据和内容序列数据;
6、基于所述训练集,通过自编码器神经网络模型和深度学习模型进行反复联合训练生成爬虫行为识别模型,并基于所述爬虫行为识别模型自动识别出爬虫数据,其中,所述测试集用于对所述爬虫行为识别模型进行优化调整。
7、一些实施例中,通过相关性分析方法确定出各特征数据之间的关联关系,包括:
8、对各特征数据进行规范化处理;
9、采用apriori算法确定进行规范化处理后的各特征数据之间的关联规则;
10、基于所述各特征数据之间的关联规则,根据关联度量值选择强关联特征,以确定各特征数据之间的关联关系。
11、一些实施例中,对收集到的日志数据和用户生成内容数据进行预处理,包括:
12、对收集到的日志数据和用户生成内容数据至少进行数据清洗、数据空值处理和/或数据异常值处理。
13、一些实施例中,所述训练集和测试集的预设比例为7:3,所述训练集为在时间序列上靠前的数据,所述测试集为在时间序列上靠后的数据。
14、一些实施例中,基于所述训练集,通过自编码器神经网络模型和深度学习模型进行反复联合训练生成爬虫行为识别模型,并基于所述爬虫行为识别模型自动识别出爬虫数据,包括:
15、基于所述训练集中的访问序列数据,构建自编码器神经网络模型,所述自编码器神经网络模型包括输入层、编码层和解码层,所述输入层的节点数对应访问序列数据的特征维度,编码层将访问序列数据压缩为低维向量,所述解码层将压缩为低维向量的访问序列数据进行结构化处理;
16、采用循环神经网络作为编码器,学习提取进行结构化处理后访问序列数据之间的长期依赖关系,
17、预训练所述编码器;
18、基于预训练后的编码器,使用标签数据fine-tune网络,调整参数以识别爬虫数据。
19、一些实施例中,还包括:
20、构建循环神经网络模型;
21、将训练集中的内容序列数据转换为词向量序列;
22、基于所述词向量序列,通过构建的循环神经网络模型,调整参数以识别爬虫数据。
23、一些实施例中,所述方法还包括:
24、通过自编码器神经网络模型和深度学习模型进行反复联合训练生成爬虫行为识别模型;
25、使用测试集评估爬虫行为识别模型的性能,并基于评估结果对爬虫行为识别模型进行优化调整,以提升所述爬虫行为识别模型的性能。
26、一些实施例中,基于评估结果对爬虫行为识别模型进行优化调整,包括:
27、挑选出所述测试集中的进行错误预测的样本;
28、将所述样本进行统计分析,并基于分析结果对爬虫行为识别模型进行重新训练。
29、一些实施例中,自动识别出爬虫数据之后,还包括:
30、针对不同类型的爬虫数据,采用相对应的处理措施,所述处理措施包括限制用户发帖速度、阻止请求、限制ip、对识别出的自动发帖内容打标记和/或设置陷阱页面。
31、相应的,本申请还提供了一种基于机器学的社区爬虫行为识别系统,包括:
32、收集模块,用于收集日志数据和用户生成内容数据,并对收集到的日志数据和用户生成内容数据进行预处理,以生成各特征数据,所述日志数据包括访问日志数据、错误日志数据和安全日志数据,所述用户生成内容数据至少包括文章标题、内容文章、发布时间和/或文章标签;
33、生成模块,用于通过相关性分析方法确定出各特征数据之间的关联关系,所述各特征数据之间的关联关系包括与爬虫行为相关联的特征数据,以及与用户发帖行为相关联的特征数据;
34、创建模块,用于创建序列数据,所述序列数据包括访问序列数据和内容序列数据,所述访问序列数据为收集到的日志数据在时间上的排序,所述内容序列数据为用户生成内容在时间上的排序,所述内容序列数据用于捕获用户的发帖数据随时间的变化情况;
35、数据标记模块,用于基于所述各特征数据之间的关联关系和创建出的序列数据,进行数据标注处理,所述数据标注处理为对与爬虫行为相关联的特征数据进行第一数据标记,以及对识别出的与用户发帖行为相关联的特征数据进行第二数据标记,对进行标记的第一数据和第二数据生成数据集,并将所述数据集按照预设比例分为训练集和测试集,所述训练集和测试集中的数据均包括访问序列数据和内容序列数据;
36、识别模块,用于基于所述训练集,通过自编码器神经网络模型和深度学习模型进行反复联合训练生成爬虫行为识别模型,并基于所述爬虫行为识别模型自动识别出爬虫数据,其中,所述测试集用于对所述爬虫行为识别模型进行优化调整。
37、有益效果:
38、本发明提供了一种基于社区的新颖且有效的爬虫行为识别与分析方法,其利用机器学习 技术,可对复杂多变的爬虫行为进行高效、精确的识别,提高了网络安全防护水平,保护了社区网站的内容安全、用户隐私及正常运行,并有助于防止恶意攻击行为。
技术特征:
1.一种基于机器学习的社区爬虫行为识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,通过相关性分析方法确定出各特征数据之间的关联关系,包括:
3.根据权利要求1所述的方法,其特征在于,对收集到的日志数据和用户生成内容数据进行预处理,包括:
4.根据权利要求1所述的方法,其特征在于,所述训练集和测试集的预设比例为7:3。
5.根据权利要求1所述的方法,其特征在于,基于所述训练集,通过自编码器神经网络模型和深度学习模型进行反复联合训练生成爬虫行为识别模型,并基于所述爬虫行为识别模型自动识别出爬虫数据,包括:
6.根据权利要求5所述的方法,其特征在于,还包括:
7.根据权利要求6所述的方法,其特征在于,所述方法还包括:
8.根据权利要求7所述的方法,其特征在于,基于评估结果对爬虫行为识别模型进行优化调整,包括:
9.根据权利要求1所述的方法,其特征在于,自动识别出爬虫数据之后,还包括:
10.一种基于机器学的社区爬虫行为识别系统,其特征在于,包括:
技术总结
本发明公开了一种基于机器学习的社区爬虫行为识别方法,包括:收集日志数据和用户生成内容数据,并对收集到的日志数据和用户生成内容数据进行预处理,以生成各特征数据,通过相关性分析方法确定出各特征数据之间的关联关系;创建序列数据;基于所述各特征数据之间的关联关系和创建出的序列数据,进行数据标注处理;基于训练集,通过自编码器神经网络模型和深度学习模型进行反复联合训练生成爬虫行为识别模型,并基于所述爬虫行为识别模型自动识别出爬虫数据。本申请能够对复杂多变的爬虫行为进行高效、精确的识别,提高了网络安全防护水平,保护了社区网站的内容安全、用户隐私及正常运行,并有助于防止恶意攻击行为。
技术研发人员:陈德勇,李元海
受保护的技术使用者:北京无忧创想信息技术有限公司
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!