一种针对增强现实的动态双耳音频渲染方法
本发明一般地涉及声学。更具体地,本发明涉及一种针对增强现实的动态双耳音频渲染方法。
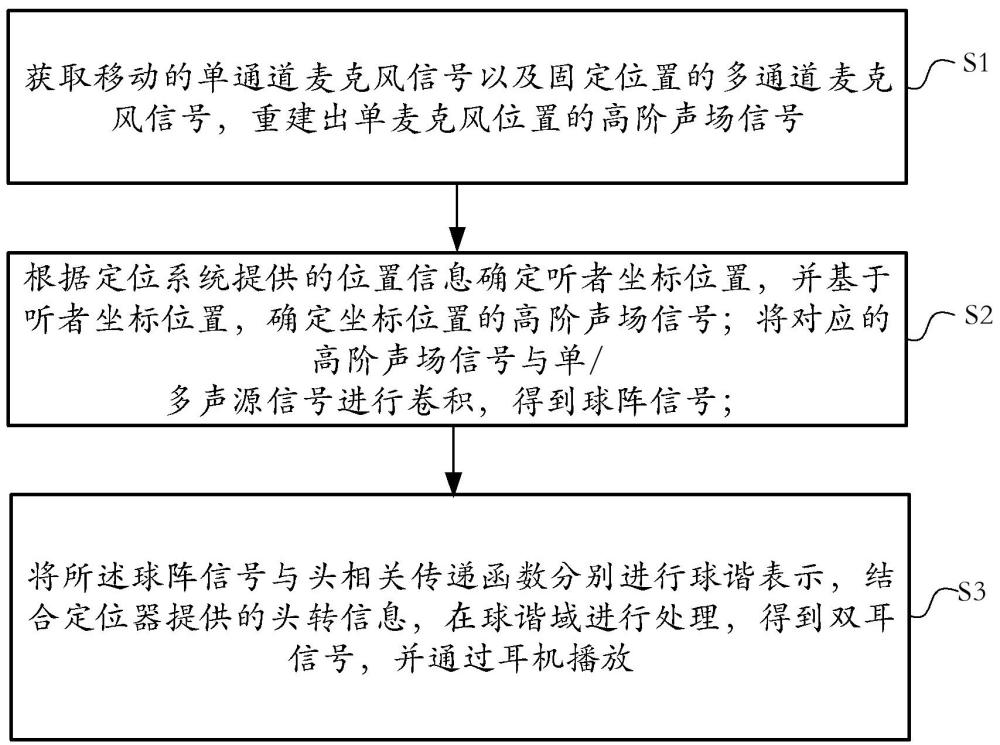
背景技术:
1、近年来,随着交互式设备和音频技术的发展,在增强现实(ar,augmentedreality)与虚拟现实(vr,virtual reality)场景中实现逼真的听觉体验十分重要。
2、其中,房间脉冲响应(rir,room impulse response)反应了房间内的声学信息,ambisonics格式则是作为一种三维环绕声场格式被广泛应用于空间声场的表示与重构技术。因此,在动态双耳渲染时,其主要包括两部分,第一部分是多通道房间脉冲响应(rir,room impulse response)的重建,第二部分是基于ambisonics进行双耳渲染。
3、其中,对于第一部分,其主要针对房间信息和声源、测量点位置信息均未知的情况下,只能测量房间内多点的rir,目前主要有三种方法进行多通道rir的插值,分别如下:
4、1)基于单点麦克风数据的声场参数化分析与合成
5、对于该方法,当插值的是一阶立体混响(foa,first order ambisonic)信号时,通常是基于dirac编码,每个时频点的foa信号由直达波和扩散两部分组成,其中声强矢量与声源方向(doa,direction of arrival)相关,基于平移定理随听者位置动态调整,混响部分保持不变。
6、当插值的是高阶双声波(hoa,higher order ambisonic)信号时,目前主要有如下的两种方法:a.将给定测量位置的hoa信号表示为(多个镜像源)直达波和混响分量,基于hoa信号的空间协方差矩阵以及主特征向量分析确定声源个数、定位以及直达波信号的提取,然后基于听者位置和姿态,更新直达波分量,混响部分则保持不变。这种方法需要声源距离信息作为先验信息。b.将给定测量位置的hoa信号表示为平面波和球面波的混合模式,即声源由近场和远场混合虚拟源表示,且假设声源空间分布是稀疏的。其中,近场声源用小半径(2m)的等效虚拟源分布来模拟,远场用大半径(20m)的平面波声源来模拟。在球谐域进行六自由度(6dof,six degrees of freedom)渲染,无需声源距离等先验信息,但需要听者在近场等效源半径范围内移动。
7、2)基于多点麦克风数据的声场插值
8、对多个均匀球阵录制的ambisonics信号进行线性插值时,以距离为权重,逐渐减小远距离麦克风对插值的影响,同时对不同阶数的球谐信号重调整,保证最近的麦克风对插值信号的影响最大,且使用与距离相关的低通滤波器模拟高频声音的自然衰减。
9、然而,当直接对ambisonics信号进行距离加权线性插值时,由于可能存在的问题,从而可能会产生类似梳状滤波的问题,从而影响听感、降低声场定位的准确性。因此,在插值时需要去掉更靠近声源的麦克风;具体为:首先使用多个球阵的doa定位结果,基于三角定理定位声源距离,将距离听者位置小于距离声源的麦克风选为有效麦克风,然后对p个麦克风数据基于距离定义权重w,基于球谐域平移矩阵m表示不同区域的声场,最后基于正则化最小二乘进行插值声场。
10、3)基于多点麦克风数据的声场参数化分析与合成
11、对于该方法,主要是基于参数化方法将声场建模为直达波和晚期混响,一种是针对各时频点的声场,一种是针对录制的ambisonics信号。
12、对于各时频点的声场,基于dirac编码,将各时频点声场建模为直达波和晚期混响,然后在插值点重构。具体为:
13、首先,进行声源doa估计:在每个测量点基于srp定位声源doa,基于三角定位法则对多个测量点的定位结果进行匹配分析;
14、其次,估计直达波和混响分量:基于时频点cdr估计每个高阶麦克风的直达波分量和混响分量;
15、然后,进行声场插值:基于外部声场球谐分解和声源位置插值直达波分量,基于距离加权插值混响幅度分量,相位部分为最近测量点的测量数据。
16、对于录制的ambisonics信号,基于多点球谐域中的房间脉冲响应(arir,ambisonic room impulse responses)进行插值,根据检测出arir中的直达波和晚期混响,进行rir的插值。其基本思想是以距离为权重(1/r)的线性插值,根据声源、测量位置和插值位置的相对距离调整直达波/早期反射的时间和幅值。
17、具体地,对于单个arir:
18、首先,由于大多数实测的arir是一阶的,因此基于一阶arir进行参数估计,当然这也同样适用于高阶声场信号(简称为高阶arir或者hoa rirs)。根据arir的全向和一阶分量估计直达波的到达时间(toa,time of arrival)和doa,并检测其峰值。
19、可通过伪强度向量的平均幅值检测直达波的toa,即
20、
21、
22、其中,没有带宽限制,表示超过0.5ms的哈明窗移动平均滤波器。
23、超过预定义阈值的的每个最大值被定义为峰值的到达时间,阈值的选择取决于房间的混响。根据ambisonic空间分解方法(asdm,ambisonic spatial decompositionmethod),由有限带宽的一阶arir的平滑伪强度向量估计对应于该峰值toa的doa,即
24、
25、
26、其中,是一阶arir的零阶全向arir通道,分别是指向x, y和z的一阶arir通道。下标表示200 hz到3 khz之间的零相位带通滤波,是长度为0.25ms的零相位平均滤波器。
27、其次,根据所有arir中的时间差(tdoa,time difference of arrival)和toa来定位直达声,基于三个相邻的arir峰值匹配定位早期反射。
28、由于优先级效应,直达声在感知方向这一方面通常占主导地位,因此为了确保直达声(即声源位置)定位的准确性,这里根据多个arir的直达声峰值间的tdoas进行直达声定位。这可以通过使用线性修正最小二乘(linear correction least-squares,lcls)估计量通过约束优化最小化式(1-13)中的二维球面ls代价函数来实现。
29、
30、其中,是第i个arir直达声的doa,t是其直达声对应的toa,,为第i个arir的测量位置。
31、通过最小化角度误差函数(1-14)来选择唯一的直达声(即声源位置),即
32、
33、
34、
35、在匹配早期反射时,假设位置变动较小时对听感影响很小,基于三个相邻arir的tdoa就可以实现较为精确的定位。使用球面交点(spherical intersection,sx)估计器作为基于tdoa的峰值定位器,由于sx估计器最初是为三维接收器阵列和设计的,因此对于三元组,其形式应用于纯水平接收器,即
36、
37、
38、则其ls误差函数为,
39、
40、令其ls误差函数为0,得到对应峰值的估计位置。
41、然后,对插值点相邻的三个arir进行峰值匹配,并将匹配峰值周围的arir片段外推到插值点。峰值匹配的目的是在相邻arir三元组中找到早期反射对应的峰值。根据迭代峰值匹配算法,该算法总是以arir三元组中的最大未匹配峰作为参考峰,用表示这个参考峰toa,用表示相应的arir位置,根据与的tdoas,将其余两个次要arir b,c中对应峰值的toa限定在最大传播时间差窗口内,即
42、
43、依次迭代,直到匹配完较为主要的峰值。
44、对于检测出的早期反射峰值,在三元组的每个匹配峰附近切割等长arir片段,将每个段定义为在峰值toa之前开始16个样本,峰值结束后至少16个样本,但限制在总段长度在3ms以下,从而可保留arir峰值段中的时间、方向和幅值信息。
45、为了在arir段之间平滑过渡,每个段的边界通过16个样本长度的半窗口重叠进行平滑。然后将每个arir的峰值外推到插值点处,
46、
47、
48、
49、其中,
50、
51、
52、其中,是外推的arir段,表示定位的早期反射对应的镜像源位置,表示插值点位置。
53、对于多点arir的插值:
54、首先,将外推到插值点的三个arir匹配的峰值和早期反射残余部分分别进行以距离为权重的线性插值,然后,对于不能定位的混响部分,例如t>100ms的部分仅取自距离插值点最近的arir。
55、对于同一水平面,线性的插值的权重的计算公式为,
56、
57、其中,是第i个测量点位置,,为插值点位置,r为相邻arir的网格间距,g是一个常数,以保证。
58、因此,插值点位置处的arir段为:
59、
60、其中,表示相应的第i个arir段。
61、上述方法中,虽然通过对多点arir插值或单点arir外推,基本可以实现多通道rir的插值任务,但是上述方案仍然存在一些问题:
62、1)计算复杂度较高,对于使用eigenmike录制的4阶arir,很难实现实时的生成和后续的实时渲染。
63、2)混响不够准确,在该方法中,混响部分通常取自最近的arir的混响部分,与实际混响部分的波形区别较为明显。
64、同时,对于第二部分的基于ambisonics的双耳渲染方法,现有技术中通常使用高阶球形麦克风阵列录制声场,拾取声场的空间信息,引入与人体声学特性相关的数据——头相关传递函数(hrtf,head-related transfer function),将二者在球谐域展开,在球谐域使用旋转因子对hrtf旋转,进行基于场景的动态渲染;具体如下:
65、首先,声场与hrtf球谐分解的矩阵表达式如下:
66、
67、其中,表示麦克风表面的声压,为其球谐分解系数,y为球谐基函数。
68、其次,通过对测量数据进行最小二乘拟合,基于球谐函数伪逆求解声场球谐分解系数,即
69、
70、其中是矩阵的伪逆,在此基础上使用径向滤波器去除球阵表面的散射体影响,得:
71、
72、其中,对于开球,
73、
74、对于刚性球(如eigenmike),
75、
76、其中,是球贝塞尔函数,是n阶第二类球汉克尔函数,为波数,为球面半径,为阶球贝塞尔函数的一阶导数,为n阶第二类球汉克尔函数的一阶导数,i为虚数单位。
77、头相关传递函数与头相关脉冲响应(hrir,head-related impulse response)均用于描述人体外耳、头部和躯干对声波的影响。其中hrtf定义为自由场情况下从声源到双耳的频域传输函数,与空间中声场的球谐分解类似,其球谐分解系数求解如下,
78、
79、其中,是hrtfs,表示球谐分解系数。
80、假设声场由远场球面上连续分布的声源产生,左右耳接收到的信号为,
81、
82、使用声场与hrtfs的球谐分解系数,进行球谐域的双耳渲染,利用球谐函数的正交完备性得到左右耳接收到的信号,
83、
84、在基于场景的双耳渲染算法中,对于听者头部旋转的情景可以看做是头相关传递函数hrtfs进行球谐域的旋转。此时只考虑听者水平面上的头部转动角度,则旋转因子表示如下:
85、
86、由此可得,基于ambisonics方法3自由度(3dof,three degrees of freedom)动态场景下的双耳渲染结果:
87、
88、需要说明的是,基于ambisonics方法对声场与hrtfs进行球谐分解,得到与声源方向无关的球谐系数,从而不需要对声场进行预先分析,即可计算得到双耳信号,使用旋转因子对hrtf在球谐域进行旋转,即可进行动态场景下的双耳渲染。
89、但是,在进行双耳渲染时,上述的ambisonics的方法仍存在一些问题,具体如下:
90、1)球形麦克风阵列eigenmike受到阵列半径与阵元数量限制,其录制声场的空间阶数远小于hrtf采样的空间阶数;高空间分辨率的hrtf数据需要与低空间分辨率的球阵数据匹配,高阶hrtf被截断到低阶ambisonics表示,造成渲染结果音色失真,定位精度的下降,高频幅度衰减等问题。
91、2)仿真高阶球阵信号会提升声场的空间分辨率,但是声场与hrtf的高阶表示会占用更大的内存空间,同时需要更大的运算量。
技术实现思路
1、为解决上述一个或多个技术问题,本发明提出了一种针对增强现实的动态双耳音频渲染方法,用于解决在进行双耳渲染时,渲染效果较差以及渲染时占用资源大的问题。
2、一种针对增强现实的动态双耳音频渲染方法,包括以下步骤:
3、获取移动的单通道麦克风信号以及固定位置的多通道麦克风信号,重建出单通道麦克风位置的高阶声场信号;
4、根据定位系统提供的位置信息确定听者坐标位置,基于听者坐标位置,确定坐标位置的高阶声场信号;将对应的高阶声场信号与单/多声源信号进行卷积,得到球阵信号;
5、将所述球阵信号与头相关传递函数分别进行球谐表示,结合定位器提供的头转信息,在球谐域进行处理,得到双耳信号,并通过耳机播放。
6、可选地,所述双耳信号为:
7、
8、其中,,分别是hrtf与球形麦克风阵列信号基于ambisonics表示的球谐系数,为用户的旋转因子,n表示球谐阶数,m表示球谐级数,为共轭运算符,为径向滤波器,l为左耳,r为右耳,m’和m分别表示不同的球谐级数,分别对应绕不同的轴旋转的欧拉角。
9、可选地,所述重建出单通道麦克风位置的高阶声场信号的具体过程为:
10、确定声源位置;
11、利用镜像源法以及所述声源位置、固定位置和插值点位置的关系,得到早期反射toa、doa和幅度,实现未测量的区域高阶arir的直达声和早期反射的重建;采用预先构建的条件对抗网络,生成未测量的区域高阶arir晚期混响;
12、基于重建的直达声、早期反射以及晚期混响,确定重建的高阶声场信号。
13、可选地,所述采用预先构建的条件对抗网络,生成arir晚期混响的具体过程为:
14、构建条件对抗网络;
15、获取数据集,采用数据集对构建的条件对抗网络进行训练,得到训练好的条件对抗网络;
16、将当前移动的单通道麦克风信号的晚期混响输入训练好的条件对抗网络,生成当前移动的单通道麦克风的arir的晚期混响。
17、可选地,所述训练数据集包括公开数据集中的单通道rir的晚期混响数据集及其对应的实测arir的晚期混响数据集构成训练数据集以及当前实测的单通道rir的晚期混响以及对应实测的arir的晚期混响构成测试数据集。
18、可选地,所述条件对抗网络包括生成器和判断器;生成器和判断器均包括输入层、卷积层和输出层。
19、可选地,还包括获取早期残差分量的步骤;所述早期残差分量选取的是固定测量点实测的arir的早期残差分量;将外推的直达声和早期反射、早期残差分量和晚期混响结合在一起,得到的重建的高阶声场信号。
20、可选地,所述基于听者坐标位置,确定坐标位置的高阶声场信号的过程为:
21、对听者所在的目标区域进行网格划分,对划分的每个网络进行标记,确定每个网格的坐标位置;
22、利用定位系统确定听者的坐标位置;
23、基于听者的坐标位置,确定听者的坐标位置对应的高阶声场信号;其中,每个网格的坐标位置均对应一个高阶声场信号。
24、本发明的有益效果为:
25、本发明主要涉及针对移动用户位置处arirs的晚期混响插值以及动态实时渲染;即本发明的方案提出了结合辅助单麦克风位置处实测的单通道rir信息,外推出arirs的晚期混响,重建出更为准确的arir,从而实现更精准更鲁棒的声场重建,并且大大降低了实测arir的工作量。同时,在大屏或扬声器的播放过程中,实时感知所处房间的声学环境,产生任意虚拟源位置到移动终端的声学冲激响应,进而将远端语音、声信号真实自然地叠加到本地的三维音频重放系统中以进行播放。
- 还没有人留言评论。精彩留言会获得点赞!