一种仿真文本病历的生成方法及系统与流程
本发明涉及机器学习技术领域,具体地说,涉及一种仿真文本病历的生成方法及系统。
背景技术
随着时代的发展,信息化程度的不断提高,电子病历的使用越来越广泛。与此同时,随着近年来机器学习与深度学习的快速发展,人们开始尝试用机器学习的方法解决医疗领域的问题,并取得了一些成效。然而,电子病历数据的获取与使用,一方面由于涉及病人隐私等问题,可能受到患者个人意愿和法律法规的层层限制,从而制约了基于大数据的机器学习等相关算法的使用;另一方面由于病历数据本身具有较大的差异性,对于某类疾病可能会出现正负样本(患病样本与非患病样本)不均衡的情况,影响机器学习相关算法的效果。针对以上问题,生成尽量还原真实病历样本分布的仿真病历数据,是一种有效的解决方案,然而当前却很少有技术尝试解决这一问题。少量的病历生成与文本生成的相关技术也存在以下问题:1.作用仅为辅助生成格式化病历,使之符合标准格式需要,减轻医生手写排版的工作,并未涉及自动生成仿真病历。2.可以根据已有文本进行合并,生成新文本,但并未涉及机器学习相关算法,生成文本多样性也十分有限。3.相关基于人工智能的文本生成方法作用范围有限(仅为文本扩展,而无法生成全文本),且应用范围不明确,与医疗领域结合不紧密。
技术实现要素:
为解决以上问题,本发明提供一种仿真文本病历的生成方法及系统,包括以下步骤:
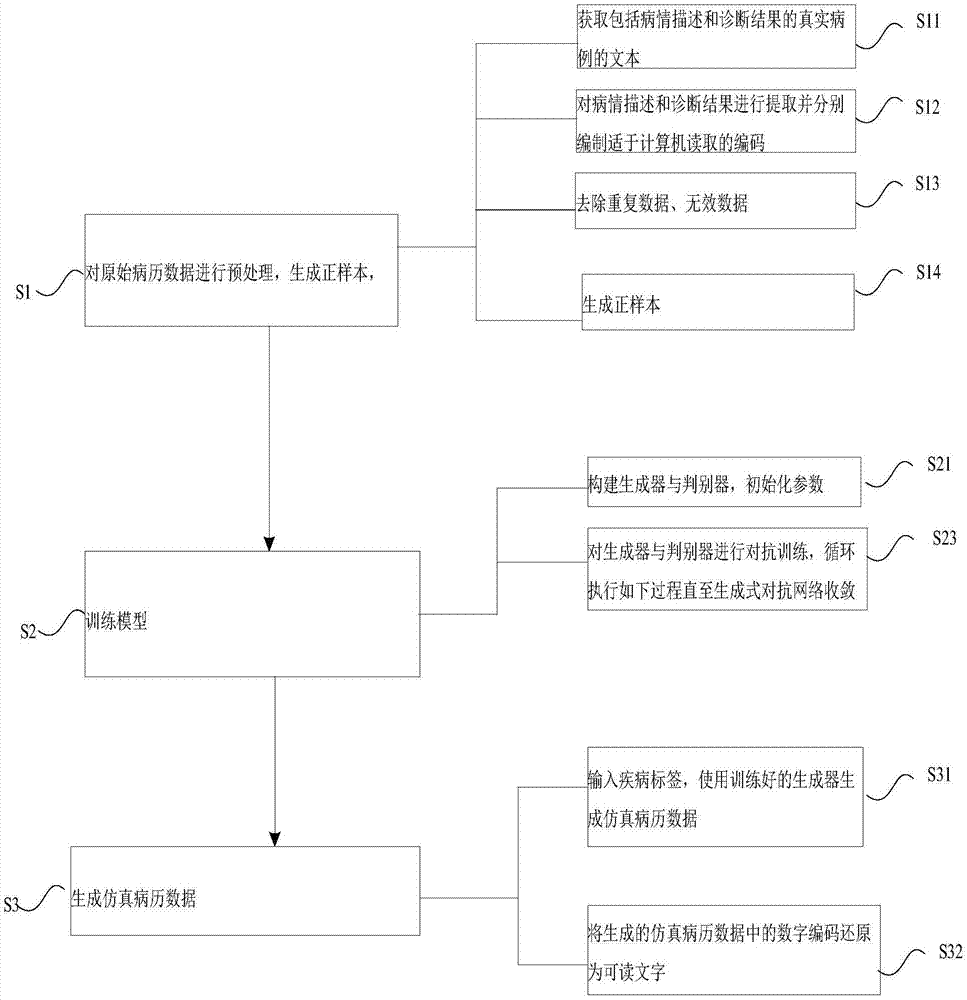
步骤s1,对原始病历数据进行预处理,生成由真实病历数据组成的正样本,具体包括如下步骤:
步骤s11,获取包括病情描述和诊断结果的真实病历的文本;
步骤s12,对病情描述和诊断结果进行提取并分别编制适于计算机读取的编码;
步骤s14,生成所述正样本,
步骤s2,训练模型,具体包括以下步骤:
步骤s21,构建生成器与判别器,初始化参数;
步骤s23,对生成器与判别器进行对抗训练,循环执行如下过程直至生成式对抗网络收敛:
步骤s231,对生成器执行多次迭代,直至收敛,具体包括如下步骤:
步骤s2311,生成器执行t次循环,每次循环以上一次循环输出的词向量和疾病标签向量为输入,输出新的词向量,从而重复t次生成长度为t的句子x1:t,其中,
以已经生成的词向量序列(x1,x2,…,xt-1)为初始状态固定不变,重复运行生成器进行采样,生成以x1:t-1为前缀的n个完整的句子,判别器对每个句子给出一个奖励值,对n个句子的奖励值取平均值,作为第t步所生成词向量xt的奖励值,
其中,词向量从事先设定的包含病历词汇的词典中选取,疾病标签向量是与病情诊断结果对应的向量;
步骤s2312,根据得到的序列总长度为t的句子,和序列中每个词向量获得的来自于判别器的奖励值,更新生成器,然后返回步骤s2311,直至收敛;
步骤s232,执行多次迭代,直至收敛,具体包括如下步骤:
步骤s2321,用步骤s231计算收敛所得的生成器生成由虚构病历数据组成的负样本,并与所述正样本组成混合病历数据集;
步骤s2322,在判别器中,以疾病标签向量和混合病历数据集中的词向量序列为输入,经过神经网络计算得到混合病历数据集中每一病历来自真实病历的概率,训练更新判别器,然后返回步骤2321,直至收敛;
步骤s3,生成仿真病历数据;
步骤s31,输入疾病标签,使用训练好的生成器生成仿真病历数据;
步骤s32,将生成的仿真病历数据中的数字编码还原为可读文字。
优选地,在步骤s12后还包括步骤s13,去除重复数据、无效数据。
优选地,在步骤s21构建生成器与判别器后还包括步骤s22,预训练生成器和判别器,具体包括如下步骤:
步骤s221,在真实病历数据上,通过极大似然估计对生成器进行预训练;
步骤s222,生成器生成由虚构病历数据组成的预训练负样本,并将该预训练负样本与正样本组合成预训练混合病历数据集,在预训练混合病历数据集上,通过极小化交叉熵对判别器进行预训练。
优选地,步骤s12中对病情描述和诊断结果进行提取并编码具体包括:
步骤s121,利用分词的方法对病情描述进行分词处理并编码;
步骤s122,对诊断结果进行编码。
优选地,生成器为循环神经网络;判别器是二分类模型。
优选地,步骤s2312中,生成器的更新公式如下:
其中,
θ为生成器g的参数;
t为句子总长度;
st-1是第t-1步生成器的状态,即前t-1步已经生成的词向量序列和疾病标签向量;
xt是第t步将要生成的词向量;
q为动作奖励函数,即对生成器g生成的句子中某一具体的词的奖励值,由判别器d给出的reward的均值计算得出;
g(xt|st-1)是生成器模型给出的xt出现的概率;
e为梯度的数学期望;
α为学习率。
优选地,步骤s2322中,根据下式更新判别器:
其中,
θ为生成器g的参数;
pdata为真实病历数据分布;
x1:t为病历数据样本;
yn为疾病标签向量。
优选地,生成器为长短时记忆网络,判别器为卷积神经网络或循环神经网络。
优选地,在步骤s121中,使用jieba对病情描述进行分词处理并编码。
一种仿真文本病历的生成系统,包括:
正样本生成模块,获取包括病情描述和诊断结果的真实病历的文本,对病情描述和诊断结果进行提取并分别编制适于计算机读取的编码,进而生成所述正样本;
构建模块,构建生成器与判别器,初始化参数;
生成器训练模块,生成器执行t次循环,每次循环以上一次循环输出的词向量和疾病标签向量为输入,输出新的词向量,从而重复t次生成长度为t的句子x1:t,其中,
以已经生成的词向量序列(x1,x2,…,xt-1)为初始状态固定不变,重复运行生成器进行采样,生成以x1:t-1为前缀的n个完整的句子,判别器对每个句子给出一个奖励值,对n个句子的奖励值取平均值,作为第t步所生成词向量xt的奖励值,
其中,词向量从事先设定的包含病历词汇的词典中选取,疾病标签向量是与病情诊断结果对应的向量;
根据得到的序列总长度为t的句子,和序列中每个词向量获得的来自于判别器的奖励值,更新生成器,如此反复直至收敛;
判别器训练模块,用生成器训练模块计算收敛所得的生成器生成由虚构病历数据组成的负样本,并与所述正样本组成混合病历数据集,在判别器中,以疾病标签向量和混合病历数据集中的词向量序列为输入,经过神经网络计算得到混合病历数据集中每一病历来自真实病历的概率,训练更新判别器,如此反复直至收敛;
仿真病历生成模块,根据输入的疾病标签,使用训练好的生成器生成仿真病历数据,将生成的仿真病历数据中的数字编码还原为可读文字。
本发明相对于现有技术具有以下有益的技术效果:
(1)本发明可以自动生成仿真文本病历数据,避免了涉及病人隐私等因素,为机器学习等任务提供了充足稳定的数据源,方便其他研究的开展。
(2)本发明可以根据人们需要,根据输入的疾病标签和病历词汇生成指定特征的病历数据,方便对该疾病的研究。
(3)本发明采用生成式对抗网络与深度学习方法,生成的数据具有较高的质量与多样性。
附图说明
通过结合下面附图对其实施例进行描述,本发明的上述特征和技术优点将会变得更加清楚和容易理解。
图1是表示本发明实施例的仿真文本病历的生成方法的步骤流程示意图;
图2是表示本发明实施例的对生成器和判别器训练的流程示意图。
具体实施方式
下面将参考附图来描述本发明所述仿真文本病历的生成方法及系统的实施例。本领域的普通技术人员可以认识到,在不偏离本发明的精神和范围的情况下,可以用各种不同的方式或其组合对所描述的实施例进行修正。因此,附图和描述在本质上是说明性的,而不是用于限制权利要求的保护范围。此外,在本说明书中,附图未按比例画出,并且相同的附图标记表示相同的部分。
本发明所提出的仿真文本病历的生成方法,主要基于生成式对抗网络模型(generativeadversarialnetwork,gan)。一个典型的生成式对抗网络要解决的是如下形式的二元极小化极大的博弈问题:
其中pdata(x)是真实的数据分布,pz(z)是随机噪声。g(z)是生成器模型,以随机噪声z为输入,输出与真实数据同维数的仿真数据,其目标是将随机噪声z尽量还原到输入样本的空间;d(x)是判别器模型,以真实样本或生成样本输入,输出样本来自于真实数据集的概率,其目标是尽量分辨出真实样本和生成样本。本发明中的生成器和判别器均为深度神经网络。
生成式对抗网络模型(gan),常应用在图像生成领域,而在文本生成领域应用却很少。其主要原因在于文本生成中的词标签是离散的,生成器最后会进行一步离散化操作得到词标签,使得判别器的梯度无法传导至生成器。本发明在原始gan模型中引入强化学习,并加入条件性约束,以生成疾病特征可控的仿真文本病历数据,保护病人隐私并用于其他机器学习任务,产生符合需求的病历样本。
强化学习是一种通过主体(agent)与环境(environment)交互而进行学习的方法。它的目标是要通过与环境(environment)交互,根据自身的状态(state),作出的动作(action)和环境的反馈(reward),优化自己的策略(policy),以获得更多更好的反馈奖励(reward)。本发明中,文本生成问题被视作一个序列决策问题。生成器为强化学习中的主体;生成器以何种规则生成句子即为策略;在每一个时间步,生成器选择生成的词即为动作,当前已经生成的句子片段和疾病特征为状态。判别器实质上提供了强化学习中的环境和奖励值信号。
生成器模型,可选用循环神经网络(recurrentneuralnetwork,rnn)或其它更常用的变体。本发明中使用了长短时记忆网络(long-shorttermmemory,lstm)。使用该模型生成句子的过程,实际是生成一系列词的过程。在时刻t生成词向量时,生成器会利用前t-1个时刻积累的信息,和第t个时刻的输入信息(后文对“输入信息”进行详细解释),通过神经网络的计算,得到生成每个词向量的概率分布。生成器依此概率进行采样,得到时刻t的词向量。由此,重复t个时间步,即可生成一个长度为t的句子。
判别器模型,可选用卷积神经网络或循环神经网络。本发明中使用了双向长短时记忆网络(bi-directionallstm)以提取更为精细的句子信息。判别器是一个二分类模型,它将整个完整的句子(词向量序列)作为输入,经过神经网络的计算,得到该样本是真实病历样本的概率。
每步迭代中,生成器生成的句子会交由判别器,判断其是否来自真实病历样本集。若判别器判断错误(即判别器无法识别该样本是真实的病历还是生成的病历),则说明此句子目前阶段可以“以假乱真”,因此会得到值为1的奖励;若判别器判断正确,则说明此句子仿真程度不高,因此会得到值为0的奖励。生成器会根据判别器给出的奖励信号,对自身参数进行调整,以生成仿真程度更好的病历样本。当生成器产生的句子质量足够高时,再用新产生的仿真病历与真实病历训练判别器,以使其能提供更精准的奖励信号。如此反复进行对抗训练,便可不断提高仿真文本病历的质量。
本实施例的仿真文本病历的生成方法包括以下步骤:
步骤s1,对原始病历数据进行预处理,生成训练数据集,具体包括如下步骤:
步骤s11,获取包括病情描述和诊断结果的真实病历的文本;
步骤s12,对病情描述和诊断结果进行提取并编码,具体包括:
步骤s121,利用分词的方法对病情描述进行分词处理并编码,例如,把一个完整的句子“腰椎间盘突出导致神经水肿和局部炎性反应”分解为腰椎间盘、突出、导致、神经水肿、和、局部炎性反应这些词语。并对应每个词语编码,以区分不同的词语。
步骤s122,对诊断结果进行编码。诊断结果可以包括确定的诊断信息,例如,十二指肠溃疡,双侧肺炎等,并且,还可以进一步包括开药信息。
步骤s14,生成真实的病历数据集,下文称为正样本s。
步骤s2,训练模型,具体包括以下步骤:
步骤s21,构建生成器g与判别器d,初始化神经网络参数。其中,生成器g为循环神经网络(rnn),如lstm网络;判别器d是二分类模型,如最终输出层神经元个数为2的双向lstm网络。
步骤s23,对生成器g与判别器d进行对抗训练,循环执行如下过程直至gan(生成式对抗网络)收敛:
步骤s231,执行g-step次迭代,直至收敛,具体包括如下步骤:
步骤s2311,通过生成器生成句子并计算每个词的奖励值。设句子长度为t,或者说,句子是词向量序列x1:t,x1:t=(x1,x2,…,xt-1),生成句子的所有词向量均是从包含病历词汇的词典中获取,词典大小为m,xt∈m。例如,有一长度为6的句子x1:6:“胃部/出现/痉挛/按压/具有/疼痛感”,其中的每个词语都有对应的词向量,并且词向量从词典中选取,有m种可能。疾病标签向量是对病情诊断结果的编码结果,设有n个疾病特征,则该向量为n维。例如诊断结果中主要有胃炎和胃溃疡两类,那么可以将其分别编码为[1,0],[0,1]。生成器g为循环神经网络,内部执行t次循环,每次循环以上一次循环输出的词向量和疾病标签向量为输入,输出新的词向量,从而重复t次生成句子x1:t。例如疾病特征为胃炎,编码为[1,0],第2时刻输出结果为“出现”,其对应的词向量编码为[0,0,0,0,0,0,0,0,0,1],而第2时刻的输出的词向量和疾病标签胃炎则作为第3时刻的输入向量,为[0,0,0,0,0,0,0,0,0,1,1,0],输出“痉挛”。
以上是一个特定的句子来说明生成器生成句子的形式。实际上,对第t步生成的词向量xt,在时间步t,状态state是当前已生成序列(x1,x2,…,xt-1)和疾病标签yn,记作st-1=(x1,x2,…,xt-1,yn),动作action是下一个选择的词向量xt,策略policy是生成器是gθ(xt|st-1)。由于判别器只能当序列被完全生成之后才能返回一个奖励,因此,为了估计中间时间步上的动作奖励值,以已经生成的词向量序列(x1,x2,…,xt-1)为初始状态固定不变,重复运行生成器进行采样,生成以x1:t-1为前缀的n个完整的句子。判别器对每个句子给出一个reward(奖励值),对n个句子的reward取平均值,作为第t步所采取的动作(即生成词向量xt)的reward。
例如,x1:t-1是“胃部出现痉挛”这个句子,是前t-1步已经生成的词向量序列,包含“胃部”、“出现”、“痉挛”这几个词向量。xt是第t步将要生成的词向量,即“按压”。为了评价“按压”这个词生成的好坏,采样得到3个句子“胃部出现痉挛按压具有疼痛感”,“胃部出现痉挛按压疼痛感剧烈”,“胃部出现痉挛按压力度较大”(此处仅以少量句子举例说明)。判别器判断其为真实病历的概率分别为0.9,0.8,0.1,即奖励值分别为0.9,0.8,0.1,则“按压”这个词获得的奖励值为0.6。
步骤s2312,根据得到的序列总长度为t的句子,和序列中每个词获得的来自于判别器的奖励值,更新生成器。优选地,采用如下公式进行更新,其实质是为了使在某一状态下,获得奖励值高的动作被生成器采用的概率增大。在更新公式后,再次返回步骤s2311,如此反复,直至收敛:
其中,
θ为生成器g的参数;
t为句子总长度;
st-1是第t-1步生成器的状态,即前t-1步已经生成的词向量序列和疾病标签向量;
xt是第t步将要生成的词向量;
q为动作奖励函数,即对生成器g生成的句子中某一具体的词的奖励值,由判别器d给出的reward的均值计算得出;
g(xt|st-1)是生成器模型给出的xt出现的概率;
e为梯度的数学期望;
α为学习率。
步骤s232,执行d-step次迭代,直至收敛,具体包括如下步骤:
步骤s2321,用当前的生成器(即经过步骤s231计算收敛所得的生成器)生成负样本,即由虚构病历数据组成的负样本s',并与正样本s组成混合病历数据集s*;
步骤s2322,在判别器中,将疾病标签和全连接层之前得到的特征向量组合成为新向量,通过全连接层后给出样本得分。优选地,根据下式更新判别器:
其中,
θ为生成器g的参数,
pdata为真实病历数据分布,
x1:t为病历数据样本,
yn为疾病标签向量。
上述更新公式中,最大化
步骤s3生成仿真病历数据(应用阶段)
步骤s31,输入疾病标签,例如胃炎,使用训练好的生成器生成仿真病历数据;
步骤s32,将生成的仿真病历数据中的数字编码还原为可读文字。
在一个可选实施例中,在步骤s12对病情描述和诊断结果进行编码后还包括步骤s13,去除重复数据、无效数据。
在一个可选实施例中,在步骤s21构建生成器g与判别器d后还包括步骤s22,预训练生成器g和判别器d,具体包括如下步骤:
步骤s221,在真实病历数据上,通过极大似然估计(mle)对生成器g进行预训练;
步骤s222,生成器d生成预训练负样本s″,并将该预训练负样本s″与正样本s组合成预训练混合病历数据集s**,在预训练混合病历数据集s**上,通过极小化交叉熵对判别器进行预训练。
在一个可选实施例中,在步骤s121中,使用jieba对病情描述进行分词处理并编码。
一种仿真文本病历的生成系统,包括:
正样本生成模块,获取包括病情描述和诊断结果的真实病历的文本,对病情描述和诊断结果进行提取并分别编制适于计算机读取的编码,进而生成所述正样本;
构建模块,构建生成器与判别器,初始化参数;
生成器训练模块,生成器执行t次循环,每次循环以上一次循环输出的词向量和疾病标签向量为输入,输出新的词向量,从而重复t次生成长度为t的句子x1:t,其中,
以已经生成的词向量序列(x1,x2,…,xt-1)为初始状态固定不变,重复运行生成器进行采样,生成以x1:t-1为前缀的n个完整的句子,判别器对每个句子给出一个奖励值,对n个句子的奖励值取平均值,作为第t步所生成词向量xt的奖励值,
其中,词向量从事先设定的包含病历词汇的词典中选取,疾病标签向量是与病情诊断结果对应的向量;
根据得到的序列总长度为t的句子,和序列中每个词向量获得的来自于判别器的奖励值,更新生成器,如此反复直至收敛;
判别器训练模块,用生成器训练模块计算收敛所得的生成器生成由虚构病历数据组成的负样本,并与所述正样本组成混合病历数据集,在判别器中,以疾病标签向量和所述词向量序列为输入,经过神经网络计算得到混合病历数据集中每一病历来自真实病历的概率,训练更新判别器,如此反复直至收敛;
仿真病历生成模块,根据输入的疾病标签,使用训练好的生成器生成仿真病历数据,将生成的仿真病历数据中的数字编码还原为可读文字。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!