一种面向中文电子病历文本结构化解析的标注方法与流程
本发明属于大数据技术领域,特别涉及一种面向中文电子病历文本结构化解析的标注方法。
背景技术:
随着大数据时代的到来,数据的采集成本、计算成本、存储成本大幅降低,医疗行业的存量历史数据和增量数据越来越多,为辅助诊疗、个性化医疗等“智慧医疗”的开展提供了坚实的大数据支撑。以郑大一附院为例,近三年的电子病历(electronicmedicalrecords,emr)数量已经超过2000余万份。
电子病历作为医疗信息化的主要载体,包含了大量高价值的诊疗信息,这些信息可以作为辅助诊疗、疾病预防、健康管理等科研、临床应用的基础数据源。但是,电子病历源于医护人员的自然语言表达,绝大部分内容为非结构化的文本信息,无法直接作为临床、科研应用的输入。因此需要采用自然语言处理技术(naturallanguageprocessing,nlp)对电子病历中的非结构化信息进行解析和抽取,转化为结构化信息存入数据库,向上层多样化的智慧医疗应用开放统一的访问接口。
当前,深度学习算法已经成为文本结构化解析的有效途径和研究热点。基于深度学习算法模型的文本结构化解析效果很大程度上取决于高质量的分词、词性、命名实体标注。实际上,中文电子病历标注已经成为深度学习算法在智慧医疗应用落地的基本前提。标注是一项乏味、易出错的过程,需要耗费大量的人力、时间成本。
技术实现要素:
本发明的目的是提供一种面向中文电子病历文本结构化解析的标注方法,解决了对电子病历文本的分词、词性、命名实体标进行简洁的标注的技术问题。
为实现上述目的,本发明采用以下技术方案:
一种面向中文电子病历文本结构化解析的标注方法,包括如下步骤:
步骤1:建立标注系统,标注系统包括标注系统架构和标注数据库;
标注系统架构包括web开发框架和标注功能接口;
步骤2:web开发框架采用springmvcweb开发架构,具体执行步骤如下:
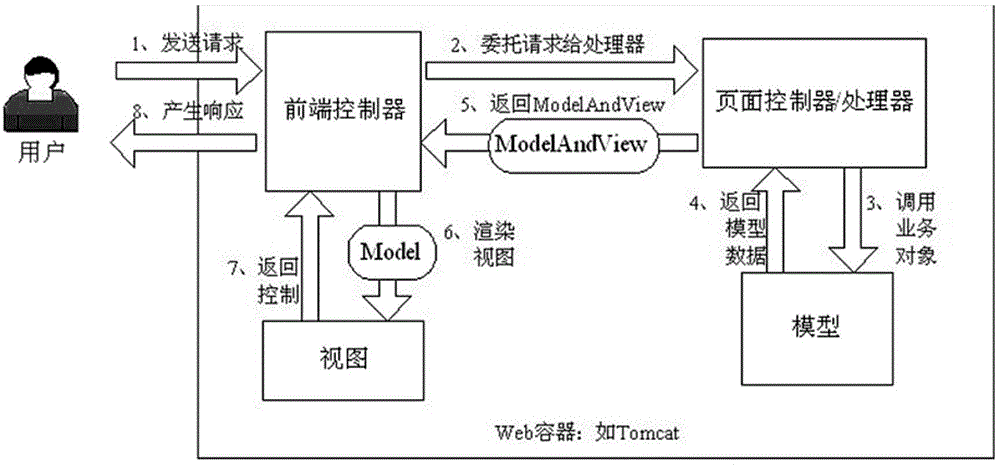
步骤s1:首先用户发送请求信息至前端控制器,前端控制器根据请求信息来决定选择哪一个页面控制器进行处理。并把请求信息委托给该页面控制器;
步骤s2:页面控制器接收到请求信息后进行功能处理:首先需要收集和绑定请求信息到一个对象,设定该对象在springwebmvc中叫命令对象,并进行验证,然后将命令对象委托给业务对象进行处理;最后处理完毕后返回一个modelandview,即,模型数据和逻辑视图名;
步骤s3:前端控制器收回控制权,然后根据返回的逻辑视图名,选择相应的视图进行渲染,并把模型数据传入以便视图渲染;
步骤s4:前端控制器再次收回控制权,将响应返回给用户;
步骤3:标注功能接口全部遵循restful标准化接口规范,接口规范采用标准的http规范方法,并遵循http规范方法中的语义;
步骤4:用户通过web页面将入院记录标注原始表输入标注系统,标注数据库读取并存储入院记录标注原始表;
步骤5:参与标注的人员通过web页面对入院记录标注原始表进行中文分词、词性和命名实体标注,并生成标注结果表,其具体步骤如下:
步骤a1:中文分词标注:参与标注的人员登录web页面后进入中文分词标注功能页面,加载入院记录标注原始表,采用bems标记法进行分词标注;
所有标注信息暂存为临时变量,直到参与标注的人员在web页面上确认标记完毕后,标注系统架构调用后台的restful标注保存接口,将数据写入中文分词标注表的分词标注结果字段,加bmes标记处理后写入分词标注结果字段,生成中文分词标注结果表;
中文分词标注接口包括分词标注加载接口和修改保存接口;分词标注加载接口用于从标注原始表读取原始标注文本或从分词标注结果表中读取标注中间结果集;
修改保存接口用于保存修改后的入院记录标注原始表中文分词标注结果;
步骤a2:词性标注:参与标注的人员登录web页面后进入词性标注功能页面,加载入院记录标注原始表,参与标注的人员基于分词结果逐个对分词的词性进行选择确认,词性的标注信息暂存为临时变量,直到参与标注的人员在web页面上确认标注结束后,标注系统架构调用后台的restful标注保存接口,将数据写入词性标注表的标注结果字段,生成词性标注结果表;
词性标注接口包括词性标注加载接口和修改保存接口;词性标注加载接口用于从词性标注结果表中读取词性标注中间结果集;
修改保存接口用于保存修改后的入院记录标注原始表分词词性标注结果;
步骤a3:命名实体标注:参与标注的人员登录web页面后进入命名实体标注功能页面,加载入院记录标注原始表,参与标注的人员在web页面上对基于定义的命名实体类型进行识别与类型匹配,标注信息暂存为临时变量,直到参与标注的人员在web页面上确认标注完成,标注系统架构调用后台的restful标注保存接口,将数据写入命名实体标注表的命名实体标注结果字段,加命名实体标签处理后写入标注结果字段,生成命名实体标注结果表;
命名实体标注接口包括命名实体标注加载接口和修改保存接口;
命名实体标注加载接口用于从标注原始表读取原始标注文本或从命名实体标注结果表中读取标注中间结果集;
修改保存接口用于保存修改后的入院记录标注原始表命名实体标注结果;
步骤6:标注系统架构将中文分词标注结果表、词性标注结果表和命名实体标注结果表打包后作为标注结果表,标注数据库存储标注结果表。
优选的,在执行步骤3时,http规范方法包括get、put、post和delete标准的http方法,接口规范遵循get、put、post和delete在http方法中的语义。
优选的,所述入院记录标注原始表为标注操作的唯一数据源,记录对原始电子病历文本进行预处理,即拆分和消冗后的数据,由emrid或txt格式原始emr文本、预处理后emr文本和备注字段组成。
优选的,所述中文分词标注结果表包括如下格式:id+emr_id+seg_annotation_raw+seg_annotation_tag+annotor+anno_time+remark;
其中:id为标识;emr_id为入院记录标注原始表的编号;seg_annotation_raw为以空格作为分词划分符号的中文分词标注中间结果集;
seg_annotation_tag为加bems标记处理后的中文分词标注结果;annotator为标注者名称;anno_time为标准时间;remark为是否分词标注完毕的标识位,默认值为空。
优选的,所述词性标注结果表包括如下格式:id+emr_id+pos_annotation_raw+pos_annotation_tag+annotator+anno_time+remark;
其中:id为标识;emr_id为入院记录标注原始表的编号;pos_annotation_raw为标识用户的标注及修改操作;pos_annotation_tag为词性标注结果;annotator为标注者名称;anno_time为标准时间;remark为备注;
优选的,所述命名实体标注结果表包括如下格式:id+emr_id+ner_annotation_raw+ner_annotation_tag+annotator++remar+anno_time;
其中:id为标识;emr_id为入院记录标注原始表的编号;ner_annotation_raw为标注中间结果集;ner_annotation_tag为加命名实体标记处理后的标注结果集;annotator为标注者名称;anno_time为标准时间;remark为备注。
本发明所述的一种面向中文电子病历文本结构化解析的标注方法,解决了对电子病历文本的分词、词性、命名实体标进行简洁的标注的技术问题,本发明的结果输出可以直接作为算法的训练语料输入,且健壮性高、可扩展性好,完全能够满足生产系统需要;本发明同时站在标注者和算法设计人员的视角,一方面标注系统简洁易用,最大限度降低标注者的标注工作强度,降低出错率,提高海量非结构化文本的标注精度和效率;另一方面,标注系统设计与知识库管理系统、核心算法系统实现数据流无缝对接,即原始电子病历数据经过预处理后直接流入标注系统,标注系统的输出直接作为核心算法系统的输入。
附图说明
图1是本发明的springmvc架构的消息处理流程图;
具体实施方式
如图1所示的一种面向中文电子病历文本结构化解析的标注方法,包括如下步骤:
步骤1:建立标注系统,标注系统包括标注系统架构和标注数据库;
标注系统架构包括web开发框架和标注功能接口;
步骤2:web开发框架采用springmvcweb开发架构,springmvc是一种基于java的请求驱动类型的轻量级web框架,符合model-view-controller架构模式思想,实现前台页面显示、控制逻辑、数据存储的解耦,从而简化开发,具体执行步骤如下:
步骤s1:首先用户发送请求信息至前端控制器,前端控制器根据请求信息来决定选择哪一个页面控制器进行处理。并把请求信息委托给该页面控制器;
步骤s2:页面控制器接收到请求信息后进行功能处理:首先需要收集和绑定请求信息到一个对象,设定该对象在springwebmvc中叫命令对象,并进行验证,然后将命令对象委托给业务对象进行处理;最后处理完毕后返回一个modelandview,即,模型数据和逻辑视图名;
步骤s3:前端控制器收回控制权,然后根据返回的逻辑视图名,选择相应的视图进行渲染,并把模型数据传入以便视图渲染;
步骤s4:前端控制器再次收回控制权,将响应返回给用户;
步骤3:标注功能接口全部遵循restful标准化接口规范,接口规范采用标准的http规范方法,并遵循http规范方法中的语义;
步骤4:用户通过web页面将入院记录标注原始表输入标注系统,标注数据库读取并存储入院记录标注原始表;
入院记录标注原始表的数据源为电子病历,其格式为如表1所示:
表1
步骤5:参与标注的人员通过web页面对入院记录标注原始表进行中文分词、词性和命名实体标注,并生成标注结果表,其具体步骤如下:
步骤a1:中文分词标注:参与标注的人员登录web页面后进入中文分词标注功能页面,加载入院记录标注原始表,采用bems标记法进行分词标注;
所有标注信息暂存为临时变量,直到参与标注的人员在web页面上确认标记完毕后,标注系统架构调用后台的restful标注保存接口,将数据写入中文分词标注表的分词标注结果字段,加bmes标记处理后写入分词标注结果字段,生成中文分词标注结果表;
中文分词标注接口包括分词标注加载接口和修改保存接口;分词标注加载接口用于从标注原始表读取原始标注文本或从分词标注结果表中读取标注中间结果集;
修改保存接口用于保存修改后的入院记录标注原始表中文分词标注结果;
步骤a2:词性标注:参与标注的人员登录web页面后进入词性标注功能页面,加载入院记录标注原始表,参与标注的人员基于分词结果逐个对分词的词性进行选择确认,词性的标注信息暂存为临时变量,直到参与标注的人员在web页面上确认标注结束后,标注系统架构调用后台的restful标注保存接口,将数据写入词性标注表的标注结果字段,生成词性标注结果表;
词性标注接口包括词性标注加载接口和修改保存接口;词性标注加载接口用于从词性标注结果表中读取词性标注中间结果集;
修改保存接口用于保存修改后的入院记录标注原始表分词词性标注结果;
步骤a3:命名实体标注:参与标注的人员登录web页面后进入命名实体标注功能页面,加载入院记录标注原始表,参与标注的人员在web页面上对基于定义的命名实体类型进行识别与类型匹配,标注信息暂存为临时变量,直到参与标注的人员在web页面上确认标注完成,标注系统架构调用后台的restful标注保存接口,将数据写入命名实体标注表的命名实体标注结果字段,加命名实体标签处理后写入标注结果字段,生成命名实体标注结果表;
命名实体标注接口包括命名实体标注加载接口和修改保存接口;
命名实体标注加载接口用于从标注原始表读取原始标注文本或从命名实体标注结果表中读取标注中间结果集;
修改保存接口用于保存修改后的入院记录标注原始表命名实体标注结果;
步骤6:标注系统架构将中文分词标注结果表、词性标注结果表和命名实体标注结果表打包后作为标注结果表,标注数据库存储标注结果表。
优选的,在执行步骤3时,http规范方法包括get、put、post和delete标准的http方法,接口规范遵循get、put、post和delete在http方法中的语义。
get的语义为:安全,幂等、获取表示和变更时获取表示(缓存);
post的语义为:不安全,不幂等、使用服务端管理的(自动产生)的实例号创建资源、创建子资源、部分更新资源,如果没有被修改,则不过更新资源(乐观锁);
put的语义为:不安全,幂等、用客户端管理的实例号创建一个资源、通过替换的方式更新资源,如果未被修改,则更新资源(乐观锁);
delete的语义为:不安全,幂等、删除资源。
优选的,所述入院记录标注原始表为标注操作的唯一数据源,记录对原始电子病历文本进行预处理,即拆分和消冗后的数据,由emrid或txt格式原始emr文本、预处理后emr文本和备注字段组成。
优选的,如表2所示所述中文分词标注结果表包括如下格式:id+emr_id+seg_annotation_raw+seg_annotation_tag+annotor+anno_time+remark;
其中:id为标识;emr_id为入院记录标注原始表的编号;seg_annotation_raw为以空格作为分词划分符号的中文分词标注中间结果集;
seg_annotation_tag为加bems标记处理后的中文分词标注结果;annotator为标注者名称;anno_time为标准时间;remark为是否分词标注完毕的标识位,默认值为空。
表2
优选的,如表3所示的所述词性标注结果表包括如下格式:id+emr_id+pos_annotation_raw+pos_annotation_tag+annotator+anno_time+remark;
其中:id为标识;emr_id为入院记录标注原始表的编号;pos_annotation_raw为标识用户的标注及修改操作;pos_annotation_tag为词性标注结果;annotator为标注者名称;anno_time为标准时间;remark为备注;
表3
优选的,如表4所示的所述命名实体标注结果表包括如下格式:id+emr_id+ner_annotation_raw+ner_annotation_tag+annotator++remar+anno_time;
其中:id为标识;emr_id为入院记录标注原始表的编号;ner_annotation_raw为标注中间结果集;ner_annotation_tag为加命名实体标记处理后的标注结果集;annotator为标注者名称;anno_time为标准时间;remark为备注。
表4
本发明数据库表设计为不同的标注提供了统一的标注数据源视图,也保证了标注结果的相互隔离。
本发明所述的一种面向中文电子病历文本结构化解析的标注方法,解决了对电子病历文本的分词、词性、命名实体标进行简洁的标注的技术问题,本发明的结果输出可以直接作为算法的训练语料输入,且健壮性高、可扩展性好,完全能够满足生产系统需要;本发明同时站在标注者和算法设计人员的视角,一方面标注系统简洁易用,最大限度降低标注者的标注工作强度,降低出错率,提高海量非结构化文本的标注精度和效率;另一方面,标注系统设计与知识库管理系统、核心算法系统实现数据流无缝对接,即原始电子病历数据经过预处理后直接流入标注系统,标注系统的输出直接作为核心算法系统的输入。
- 还没有人留言评论。精彩留言会获得点赞!