基于深度学习技术的肺结节筛查算法的制作方法
本发明涉及一种肺结节筛查算法,具体来讲是一种基于深度学习技术的肺结节筛查算法。
背景技术:
肺结节筛查任务本质上是计算机视觉领域的目标检测问题,流行的解决方案有两种:传统机器学习模型的目标检测算法、基于深度学习方法的目标检测算法。
传统的目标检测一般使用滑动窗口结合分类器的方法,主要包括三个步骤:
利用不同尺寸的滑动窗口框住图中的某一部分作为候选区域;提取候选区域相关的视觉特征,比如harr特征、hog特征等;利用分类器进行识别,比如常用的svm模型。该类方法准确率不高,主要原因是传统特征需要大量的专家领域知识方能形成有效的featureset,且难以提取数据内部复杂的结构特征,模型算法的transferlearning性质也不好。随着深度学习技术的发展,越来越多的机构和组织将其应用到医学影像的目标检测任务中。针对胸部ct的肺结节筛查任务主要有两种思路,第一种是分别对ct中每一层扫描图片进行2d图像结节筛查,最终将所有扫描层的筛查结果进行合并,给出最终筛查结果,由于这种方法未利用结节的三维结构特性,在筛查准确度上存在明显劣势。第二种方法使用了更全面的影像信息,首先将肺部组织从ct影像中分割出来,然后使用fpn网络针对提取出的肺部组织进行三维影像的结节筛查,效果往往较好,但现有算法的筛查效率及筛查效果仍然有较大的提升空间,这是由于肺部组织分割过程较为耗时,且肺部边缘分割不准确造成重要信息的丢失,特别是肺壁上存在较大体积的病灶时,影响更为显著,另外,微小结节小至3mm,大至80mm,在考虑显存及计算效率的情况下,fpn网络对尺度变化如此之大的目标检测效果不好。
技术实现要素:
因此,为了解决上述不足,本发明在此提供一种基于深度学习技术的肺结节筛查算法。本专利提出了一种高效的深度学习方法,该方法使用胸部ct作为输入,可以较为准确的筛查出所含肺结节,辅助医生提高阅片效率,解决医疗行业医生少需求多、医疗水平不平衡、误诊率高耗时长等问题。
本发明是这样实现的,构造一种基于深度学习技术的肺结节筛查算法,其特征在于:为三个阶段,首先是候选结节生成任务,用于提取大量疑似结节,在一定假阳率的情况下,保证99.5%以上的结节检出率;其次是falsepositivereduction任务,用于降低假阳率,筛选出真正的结节;结节定性,用于诊断肺结节的良恶性、观察征象,为医生提供诊断依据。
根据本发明所述基于深度学习技术的肺结节筛查算法,其特征在于:候选结节生成:针对候选结节提取任务,模型结合unet、retinanet的优势,训练时采用focalloss,实现了基于3d图像的结节筛查模型。过程可分为四个阶段:对图像的预处理、使用骨干网络进行特征提取、多尺度候选结节预生成、候选结节的非极大抑制;具体为;
(1)图像的预处理:由于输入ct大多是100-700层的512×512大小的图像,层数不同导致模型无法直接训练,而3d图像过大限制了模型的复杂度,甚至无法构建基于主流显卡显存的3d结节筛查网络,由此,对ct进行预处理的工作必不可少,从而得到模型可用于训练和预测的数据形式;
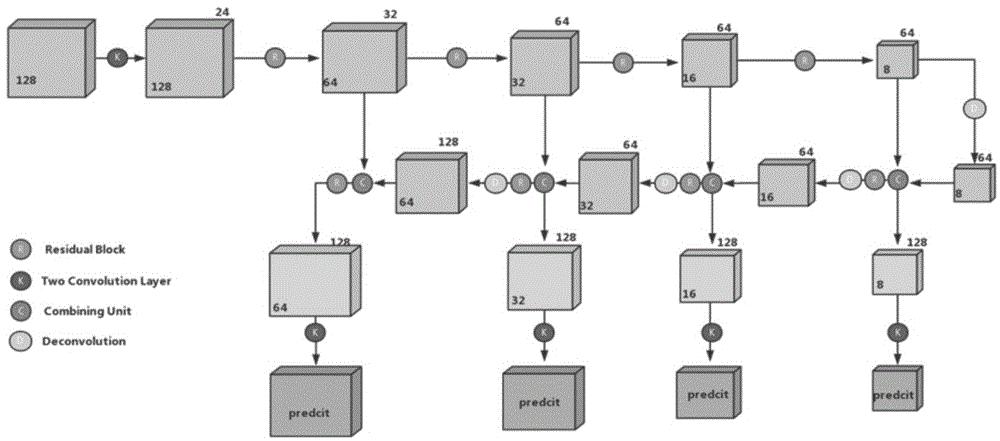
(2)骨干网络:结节筛查骨干网络使用基于三维resnet的unet,主要包含两部分:contract-ingpath和expansivepath。其中contractingpath是一个三维化的resnet,共4个block,每个block之前是max-pooling层,最后一个block之后是一层cnn,且每个block是由多层cnn组成。expansivepath的结构与expansivepath相反,只是每一个block的输入为前一个block输入和expansivepath对称block输出的和,block之间不使用max-pooling,而是使用deconvolution进行upsampling;
(3)多尺度候选结节预生成:骨干网络expansivepath中的4个block分别输出4个三维特征图,针对每个特征图,分别经过类似retina-head的cnn网络,进行分类和定位预测;
(4)非极大抑制:得到将整个ct不同patch预生成的候选结节后,可以采用non-maximum-suppression将重叠度高于threshold的boxes进行合并,抑制冗余box,最终得到候选结节。
根据本发明所述基于深度学习技术的肺结节筛查算法,其特征在于:falsepositivereduction任务,分为两个阶段:候选结节预处理、结节分类。预处理过程裁剪肺结节附近的图像patch,区域物理大小固定,再放缩到结节分类模型所需的大小。结节分类模型使用cnn网络,并与候选结节生成任务的预测结果ensamble,得到更好的肺结节检测效果。
根据本发明所述基于深度学习技术的肺结节筛查算法,其特征在于:结节定性;通过对结节周围体素的分析,在结节分类、结节边缘、实性成分边缘、分叶征、毛刺征、血管成像征、晕征、颗粒状、蜂窝征、空泡征、瘢痕样、叶间裂相关、生长长轴与支气管一致、与胸膜关系密切等十余种观察征象进行诊断,并给出结节良恶性和具体癌症分型信息。
本发明具有如下优点:本发明在此提供一种基于深度学习技术的肺结节筛查算法。本专利提出了一种高效的深度学习方法,该方法使用胸部ct作为输入,可以较为准确的筛查出所含肺结节,辅助医生提高阅片效率,解决医疗行业医生少需求多、医疗水平不平衡、误诊率高耗时长等问题。本专利具有如下优点及有益效果:
1)去掉肺部区域分割、特征提取等环节,提高运算效率。
2)三维图像目标识别,结合更多维度信息,提高效果。
3)end-to-end深度学习模型在根据数据自动调节的方面,拥有更大的空间,
增加模型整体契合度,且具有良好的transferlearning性质。
4)falsepositivereduction与候选结节生成两任务的集成,判断更为准确。
5)多种图像增强手段,使模型针对不同大小、方向的结节具有良好的适用性。
6)multi-task模型共享表示,提高泛化能力。
附图说明
图1是骨干网络示意图;
图2是残差网络示意图;
图3是拼接网络示意图。
具体实施方式
下面将结合附图1-图3对本发明进行详细说明,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明通过改进在此提供一种基于深度学习技术的肺结节筛查算法;如图所示;本专利将肺结节筛查问题分解为三个阶段,首先是候选结节生成任务,用于提取大量疑似结节,在一定假阳率的情况下,保证99.5%以上的结节检出率;其次是falsepositivereduction任务,用于降低假阳率,筛选出真正的结节;结节定性,用于诊断肺结节的良恶性、观察征象,为医生提供诊断依据。
一、候选结节生成:针对候选结节提取任务,模型结合unet、retinanet的优势,训练时采用focalloss,实现了基于3d图像的结节筛查模型。过程可分为四个阶段:对图像的预处理、使用骨干网络进行特征提取、多尺度候选结节预生成、候选结节的非极大抑制。
(1)图像的预处理:由于输入ct大多是100-700层的512×512大小的图像,层数不同导致模型无法直接训练,而3d图像过大限制了模型的复杂度,甚至无法构建基于主流显卡显存的3d结节筛查网络,由此,对ct进行预处理的工作必不可少,从而得到模型可用于训练和预测的数据形式。
(2)骨干网络:结节筛查骨干网络使用基于三维resnet的unet,主要包含两部分:contract-ingpath和expansivepath。其中contractingpath是一个三维化的resnet,共4个block,每个block之前是max-pooling层,最后一个block之后是一层cnn,且每个block是由多层cnn组成。expansivepath的结构与expansivepath相反,只是每一个block的输入为前一个block输入和expansivepath对称block输出的和,block之间不使用max-pooling,而是使用deconvolution进行upsampling。
(3)多尺度候选结节预生成:骨干网络expansivepath中的4个block分别输出4个三维特征图,针对每个特征图,分别经过类似retina-head的cnn网络,进行分类和定位预测。
(4)非极大抑制:得到将整个ct不同patch预生成的候选结节后,可以采用non-maximum-suppression将重叠度高于threshold的boxes进行合并,抑制冗余box,最终得到候选结节。
(二)falsepositivereduction:
falsepositivereduction任务,分为两个阶段:候选结节预处理、结节分类。预处理过程裁剪肺结节附近的图像patch,区域物理大小固定,再放缩到结节分类模型所需的大小。结节分类模型使用cnn网络,并与候选结节生成任务的预测结果ensamble,得到更好的肺结节检测效果。
(三)结节定性:通过对结节周围体素的分析,在结节分类、结节边缘、实性成分边缘、分叶征、毛刺征、血管成像征、晕征、颗粒状、蜂窝征、空泡征、瘢痕样、叶间裂相关、生长长轴与支气管一致、与胸膜关系密切等十余种观察征象进行诊断,并给出结节良恶性和具体癌症分型信息。
大多数观察征象的样本分布不均衡,甚至出现80:1的情况,罕见样本也较难收集,分别构建机器学习模型对不同的观察征象进行分类无法到达预期效果。本专利使用multi-task模型,同时对观察征象进行分类,共享骨干网络特征提取,只独立计算预测及损失,大大提高了模型的泛化能力与效果。
本专利具有如下优点及有益效果:
1)去掉肺部区域分割、特征提取等环节,提高运算效率。
2)三维图像目标识别,结合更多维度信息,提高效果。
3)end-to-end深度学习模型在根据数据自动调节的方面,拥有更大的空间,
增加模型整体契合度,且具有良好的transferlearning性质。
4)falsepositivereduction与候选结节生成两任务的集成,判断更为准确。
5)多种图像增强手段,使模型针对不同大小、方向的结节具有良好的适用性。
6)multi-task模型共享表示,提高泛化能力。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!