一种基于自编码器的肝病评估方法与流程
本发明涉及一种基于自编码器的肝病评估方法,属于大数据医疗技术领域。
背景技术:
肝病是指发生在肝脏的病变,是一种常见的危害性极大的疾病,它具有感染人群广、危害性巨大、种类繁多的特点。如果能够指定一套完整的规范来及时准确的评估病情从而指定相应的救治方案,这将对肝病的治疗和预防产生重要影响。
近年来深度学习和数据挖掘领域的兴起让人们意识到挖掘出医疗数据深层次的特征,可以有效地提高医学数据的利用率,减少患者的就诊时间并提高医生的行医效率和评估的准确率。
现有技术中,深度学习已经广泛应用到了医疗领域并取得了不错的成效,其中自编码器网络作为深度学习网络之一也在被不断的改进和完善。然而传统自编码器提取的特征没有考虑到数据样本之间的关系,这可能会导致信息的丢失,而且肝病数据本身具有一定的相关性,因此如果不考虑数据之间的关系将会影响到最终的分类效果。
技术实现要素:
针对现有技术中存在的问题,本发明提出了一种基于自编码器的肝病评估方法,利用改进的自编码器提取门诊数据特征,并根据提取的特征对其进行正确的分类来达到评估的目的。
为实现上述发明目的,本发明提供了一种基于自编码器的肝病评估方法,包括以下步骤:
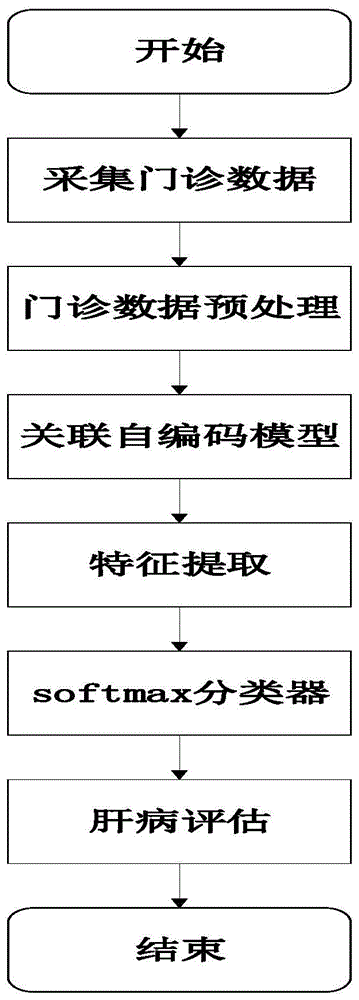
1)对医院的肝病门诊数据进行采集、汇总;
2)对采集的门诊数据进行预处理,包括缺失值的填充、噪声的过滤、无效数据的清除;
3)将预处理过的门诊数据输入到关联自编码器中进行训练来提取门诊数据的特征;
4)将经过关联自编码器提取的特征输入到softmax分类器中训练并对模型进行整体的反向传播调整和优化;
5)将测试数据输入到训练好的关联自编码器和和softmax分类器模型中进行评估测试,分类器的结果即为肝病的评估结果。
进一步地,上述步骤3)中关联自编码器训练提取门诊数据特征包括以下步骤:
3.1)将预处理后的门诊数据转换成一个矩阵,矩阵的每一行即为一个病人的门诊数据,用向量x来表示一个病人的门诊数据,每个特征与关联自编码器的输入层单元一一对应;
3.2)关联自编码器训练过程如下:
3.2.1)将样本数据x输入到输入层,用sigmoid激活函数得出隐含层数据的输出;隐含层的输出为y=s(w1x+b1),其中w1、b1分别为输入层到隐含层的权重和偏置项,第一轮训练时w1和b1通过随机初始化得到,之后通过随机梯度下降法不断调整;
3.2.2)输出层数据由隐含层通过sigmoid激活函数获得,输出层的输出为x'=s(w2y+b2),其中隐含层到输出层的权重w2和偏置项b2在第一轮训练时也是通过随机初始化获得,之后通过随机梯度下降法不断调整,y为隐含层的输出;
3.2.3)计算输入层x和输出层x'的相关系数
cov(x,x')=e(xx')-e(x)e(x')
3.2.4)将相关系数加入自编码器目标函数中组成关联自编码器,关联自编码器的损失函数为:
3.2.5)采用随机梯度下降法进行反向传播训练,更新输入层到隐含层和隐含层到输出层的权重w1、w2和偏置b1、b2,权重和偏置的求导过程如下:
权重求偏导:
偏置求偏导:
其中ai为每个单元的激活值,δi为每个单元的残差。权重和偏置的更新由下式求得:
权重更新:
偏置更新:
其中α为人为设定的动量因子;
3.2.6)利用更新的权重和偏置重复过程3.2.1,计算损失函数l的值是否达到指定阙值或者达到指定的迭代次数,若满足指定的阙值或者迭代次数则模型训练完成,停止训练,否则继续执行3.2.1。
3.3)训练完成的自编码器将得到一个合适的权重w1和偏置项b1,自编码器提取的特征即为隐含层的输出y=s(w1x+b1)。
进一步地,上述步骤4)中softmax分类器训练的方法以及关联自编码器和softmax分类器整体微调过程为:
4.1)将关联自编码器提取的特征y作为softmax分类器的输入;
4.2)根据关联自编码提取的特征向量,softmax在每个类别的输出概率为
4.3)softmax的损失函数采用交叉熵的形式,即
4.4)通过梯度下降法不断向前更新softmax分类器和关联自编码器的参数,当损失函数的值在指定的阙值范围内时整个网络训练完成,否则继续步骤4.1)。
进一步地,上述步骤5)中肝病评估的过程为:
5.1)将经预处理过的测试集作为待评估的患者数据;
5.2)将测试集输入到已经训练好的关联自编码器中,对测试集的数据进行特征提取;
5.3)将经过关联自编码提取到的特征输入到softmax分类器中进行分类识别;
5.4)softmax分类的结果即为评估出的患者所患肝病类型的结果;
进一步地,上述步骤2)中的缺失值的填充采用均值填充法,即取缺失值指标的平均值;噪声的过滤采用中位数法,即将离群点用该项特征的中位数替换;对于缺失值超过50%的样本直接删除,与检查指标无关的数据项直接删除。
本发明有以下有益效果:
本发明在传统自编码器中加入了数据相关性,提出一种关联自编码器以改进原有自编码器的不足,该模型使得模型在进行特征提取时考虑了数据样本本身之间的关系,使其能够生成更好的特征表达,以此来进一步降低分类的误差。本发明提高了肝病评估的精确度,可以为医生提供有效的辅助评估手段并减轻医生的压力。
附图说明
图1为本发明的方法流程图。
图2为关联自编码器模型的网络结构图。
图3为自编码器和关联自编码器的实验对比结果图。
具体实施方式
为使本发明的技术方案更加清晰明确,下面结合附图及实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明公开了一种基于自编码器的肝病评估方法,其具体步骤如下:
步骤1,对医院2016和2017年两年的肝病门诊数据进行采集、汇总,共计3万名患者。门诊数据主要涉及病人的信息以及各项肝脏检查指标值。本实施例将门诊数的70%约2万名患者作为训练集来进行模型的训练,剩下的1万名患者作为测试集来测试本方案的性能;
步骤2,对采集的门诊数据进行预处理,包括缺失值的填充、噪声的过滤、无效数据的删除;缺失值的填充采用均值填充法,即取缺失值指标的平均值;噪声的过滤采用中位数法,即将离群点用该项特征的中位数替换;对于缺失值超过50%的样本直接删除,与检查指标无关的数据项也直接删除;
步骤3,将预处理过的训练集输入到关联自编码器中进行训练来提取数据特征;关联自编码器训练过程和特征提取方法如下:
过程3.1,将预处理后的门诊数据转换成一个矩阵,矩阵的每一行即为一个病人的门诊数据,用向量x来表示一个病人的门诊数据。本实施例中,向量x共有98维特征,每个特征与关联自编码器的输入层单元一一对应;
过程3.2,关联自编码器的结构如图2所示,关联自编码训练过程如下:
3.2.1,首先随机初始化网络中的权重和偏置项,将样本输入到输入层,用sigmoid激活函数得出隐含层数据的输出。隐含层的输出为y=s(w1x+b1),其中第一轮训练时权重w1和偏置b1通过随机初始化得到,之后通过随机梯度下降法不断调整。
3.2.2,同样输出层数据由隐含层通过sigmoid激活函数获得,输出层的输出为x'=s(w2y+b2),其中权重w2和偏置b2在第一轮训练时也是通过随机初始化获得,之后也是通过随机梯度下降法不断调整,y为隐含层的输出;
3.2.3,计算输入层x和输出层x'的相关系数
cov(x,x')=e(xx')-e(x)e(x')
3.2.4,传统自编码器包含编码和解码两个阶段,其目的是重构出输入数据本身,训练的目标是使得重构的误差尽量的小。传统自编码器损失函数采用标准差的方式,本文将相关系数加入自编码器目标函数中来改进原有自编码器的不足,并将其命名为关联自编码器。加入了相关性的关联自编码器损失函数为:
3.2.5,关联自编码器的训练过程采用随机梯度下降法进行反向传播训练。随机梯度下降法就是求损失函数的偏导数来不断地更新输入层到隐含层和隐含层到输出层的权重w1、w2和偏置b1、b2;权重和偏置的求导过程如下:
权重求偏导:
偏置求偏导:
其中ai为每个单元的激活值,δi为每个单元的残差。权重和偏置的更新由下式求得:
权重更新:
偏置更新:
其中α为人为设定的动量因子;
3.2.6)利用更新的权重和偏置重复过程3.2.1,计算损失函数l的值是否达到阙值或者达到指定的迭代次数,若满足指定的阙值或者迭代次数则模型训练完成,停止训练,否则继续执行3.2.1。本实施例中设置阙值为10-3,迭代次数为1000次;
过程3.3,训练完成的自编码器将得到一个合适的权重w1和偏置项b1,自编码器提取的特征即为隐含层的输出y=s(w1x+b1);
步骤4,将关联自编码器提取的特征输入到softmax分类器中训练并对关联自编码器和softmax分类器进行整体调整和优化;softmax分类器训练方法以及关联自编码器和softmax分类器整体微调过程为:
过程4.1,将关联自编码器提取的特征y作为softmax分类器的输入;
过程4.2,softmax为多分类器,输出单元的个数即为肝病的类别数,每个输出单元表示一种肝病类别,本实施例中肝病共有10个种类。根据关联自编码提取的特征向量,softmax在每个类别的输出概率为
过程4.3,softmax多分类器希望特征对于概率的影响是乘积性质的,因此它的损失函数也采用交叉熵的形式,即
过程4.4,softmax分类器的训练是通过梯度下降法不断微调整个关联自编码器和softmax层的参数实现的。模型用梯度下降法进行整体反向传播训练的目标是使得损失函数
其中,式子(1)为每个类别的概率对该类别特征向量的偏导结果,式子(2)为损失函数对特征向量的求偏导过程,将式(1)的结果带入式子(2)即可得到softmax损失函数对特征向量y的梯度。
步骤5,将测试数据输入到训练好的关联自编码器和和softmax分类器模型中进行评估测试,分类器的结果即为肝病的评估结果;肝病评估的过程为:
过程5.1,将经预处理过的训练集作为待评估的患者数据;
过程5.2,将测试集输入到已经训练好的关联自编码器中,对测试集的数据进行特征提取;
过程5.3,将经过关联自编码提取到的特征输入到softmax分类器中进行分类识别;
过程5.4,由softmax分类器输出层得出每个输出单元的概率si,概率最大的输出单元表示的肝病种类即为评估出的患者所患肝病类型。
在实施例中,本方案所提出的关联自编码器,使得传统自编码器能够生成更好的特征表达,特征提取能力有了较大的提高,从而在分类阶段进一步降低了分类的误差,提高了准确率。利用测试集对该模型进行测试发现,相比于传统自编码器模型该方案使得肝病的分类准确度提高了3%左右。具体实验结果如图3所示。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例应用于其它领域,但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!