一种基于聚类和PNN的药品风险分级方法与流程
本发明涉及一种基于聚类和pnn的药品风险分级方法,属于药品风险分级技术领域。
背景技术:
随着医学领域的不断发展,大量化学合成药品不断上市,在人类预防疾病、治疗疾病、保障人民健康过程中发挥了重要作用。但是,随之而来的是大规模药害事件的发生。所以,药品的风险评估与检测亟待加强。药品的风险评估与管理是减少药物不良反应,增强人们用药安全性的重要措施。即使目前有部分国家已经制定了药品分级系统,但是仍存在分级标准难以制定和统一、分级方法多未进行量化分析和局限在某类药品的问题。这不仅不利于有关部门对药品的监管,还影响医务工作者临床药物治疗方案的决策。
技术实现要素:
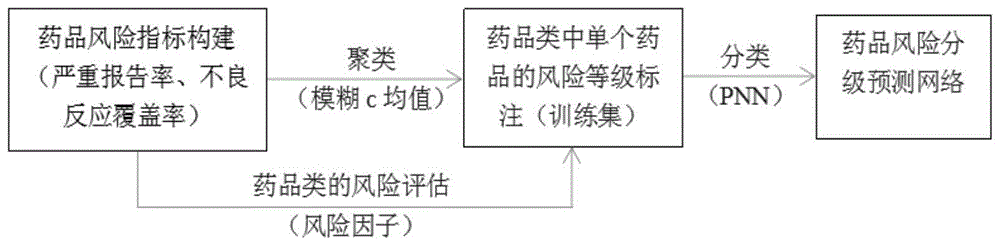
本发明所要解决的技术问题是提供一种基于聚类和pnn的药品风险分级方法,实现对于药品风险分级的信息化智能化管理。该方法采用无监督学习与有监督学习相结合的策略,利用模糊c均值聚类方法,解决为原始药品数据自动风险级别标注的问题,再利用概率神经网络算法对打上标签的数据集进行训练,实现药品风险级别预测。
本发明为解决上述技术问题采用以下技术方案:一种基于聚类和pnn的药品风险分级方法,包括如下步骤:
步骤1、构建药品风险指标,基于我国药品不良反应adversedrugreaction,adr,自发报告数据中每个药品发生的不良反应报告信息,通过定义药品严重报告率seriousreportingrate,srr和不良反应覆盖率adversereactioncoveragerate,acr两个指标对每个药品的风险进行量化;
步骤2、利用模糊c均值进行聚类,基于每个药品的srr和acr两个指标值,采用模糊c均值算法进行聚类;
步骤3、物品类的风险特征提取和单个药品的风险等级标注,定义药品类的风险因子,对聚类后的每个药品类分别计算总的风险值,并根据风险值大小对每个药品类中所有药品的风险标签进行统一标注,为分类模型奠定数据基础;
步骤4、基于概率神经网络的药品风险等级预测,基于上述步骤产生的带有风险标签的药品数据,利用概率神经网络构建药品风险分级分类器,概率神经网络使用parzen窗估计法得出某一类别的条件概率密度函数估计值,再通过判别函数计算输入样本,训练网络模型,最后用判别函数最大值所对应的类别对样本进行标记来实现药物风险级别的预测。
进一步的,所述步骤1中,
严重报告率描述了某个药品严重报告数量占所有adr报告总数的百分比。若严重报告率越大,则该药品产生的不良反应越严重,该药品越危险。假设现存在某一药品d,则严重报告率(srr)的公式为:
其中,药品d的adr报告总数量为r(d),其中严重报告数量为rs(d)
不良反应覆盖率描述了某个药品产生不良反应的个数占全部adr总数的百分比。若不良反应覆盖率越大,则该药品相对产生的不良反应种类越多,该药品越危险。假设现存在某一药品d,则不良反应覆盖率(acr)的公式为:
其中,该药品导致的adr的种类数为k(d),全部adr种类数为m。
进一步的,所述步骤2的具体步骤为:
步骤2.1:将模糊c均值聚类方法应用于上述数据集,算法输入包括药品名称及两个指标数据,聚类数目,模糊系数,迭代终止条件即最大迭代次数,目标函数最小误差;
设n种药品的数据样本为x={x1,x2,...,xn},c(2≤c≤n)是要将数据样本分成的类型的数目,a={a1,a2,..,ac}表示相应的c个类别,u是其相似分类矩阵,各类别的聚类中心为{v1,v2,...,vc},μk(xi)是第i种药物xi对于类ak的隶属度(简写为μik),则目标函数jb可以用下式表达:
其中,dik是欧几里得距离,用来度量第i种药品xi与第k类中心点之间的距离;m是样本的特征数;b是加权参数,取值范围是1≤b≤∞;
步骤2.2:随机初始化隶属度u和聚类中心v;
步骤2.3:通过式(5)计算每个数据相对于各个类簇的隶属度,并更新隶属度矩阵;
步骤2.4:通过式(6)计算新的聚类中心,用新的聚类中心更新聚类中心位置矩阵;
模糊c均值聚类方法就是寻找一种最佳的分类,以使该分类能产生最小的函数值jb,它要求一个样本对于各个聚类的隶属度值和为1,即满足:
样本xi对于类ak的隶属度u={μik}为
设ik={i|2≤c<n;dik=0},对于所有的i类,i∈ik,μik=0,c个聚类中心v={vi}为
步骤2.5:通过式(3)计算新的目标函数值jb;
步骤2.6:每次迭代后,计算新的目标函数与原目标函数的差值,如果|j[i]-j[i-1]≤ε|,或者迭代次数满足最大迭代次数,终止迭代过程,算法结束;否则,跳转步骤2.3继续执行。
进一步的,所述步骤3中,根据adr自发报告的数据特征,药品的风险可以由高到低分为“adr覆盖率低且不良反应严重”、“adr覆盖率高且不良反应不严重”、“adr覆盖率低且不良反应不严重”三种情形;基于此创建药品类的风险程度评价模型,所述模型根据以下公式构建每个药品类的风险因子:
其中,risk(j)是第k类药品的得分,m是样本特征数,numj是第j类药品个数,arrtibutei是第i类药品特征j的标准化值;通过指数级增加,扩大类别之间的差异,得出有明显差异的类别得分,根据得分函数的大小,即可进行药品风险程度评价;严重报告率越大,adr覆盖率越大,即该药物风险级别越大,呈现正相关。
进一步的,所述步骤4的具体步骤如下:
步骤4.1:确定隐含层神经元径向基函数中心,
设训练集样本输入矩阵p和输出矩阵t分别为:
其中,pij表示第j个训练样本的第i个输入变量;tij表示第j个训练样本的第i个输出变量;r为输入变量的维数;k为输出变量的维数,对应k个类别;q为训练集样本数;
隐含层的每个神经元对应一个训练样本,即q个隐含层神经元对应的径向基函数中心为:
c=p'(k)(9)
步骤4.2:确定隐含层神经元阈值,
为了简便起见,q个隐含层神经元对应的阈值为:
b1=[b11,b12,...,b1q]'(10)
其中
步骤4.3:确定隐含层与输出层间权值,
当隐含层神经元的径向基函数中心及阈值确定后,隐含层神经元的输出便可以由式(11)计算:
ai=exp(-||c-pi||2b1),i=1,2,...,q(11)
其中pi=[pi1,pi2,...,pir]'为第i个训练样本向量;
隐含层与输出层间的连接权值w取为训练集输出矩阵,即:
w=t(12)
步骤4.4:输出层神经元输出计算,
当隐含层与输出层神经元间的连接权值确定后,便可以计算出输出层神经元的输出,即:
ni=lw2,1ai,i=1,2,...,q(13)
yi=compet(ni),i=1,2,...,q(14)
通过以上4.1-4.4步骤,依次计算隐含层神经元的径向基函数中心、阈值,隐含层与输出层间权值,再通过测试集样本类别,不断修正网络参数,即完成了基于概率神经网络的分类器构建。对于一种风险标签未知的新药物,只需要输入其srr和acr两个指标值,即可预测该药物风险等级。
与现有技术相比,本发明具有有益效果入戏:
1、使用定量分析的方法,采用信息化处理方式,将非监督方法(模糊c均值聚类方法)和监督方法(概率神经网络)的优点结合起来,基于全局的药品数据实现了药品风险分级的一致性和可靠性,并得到了满意的分类结果。
2、提出的基于模糊c均值聚类算法可以对现有药品数据进行自动标记类别,不需要人为干预,避免了人为主观性带来的弊端并且具有很好的稳定性。
3、本发明利用指标值之间的科学计算,设定分级标准,解决了目前分级标准难以制定和统一、分级方法多未进行量化分析的问题,对于有关部门对药品的监管,医务工作者临床药物治疗方案决策的制定有重要意义。
4、本发明选用概率神经网络进行训练和预测,pnn网络适用于低容错性医学领域的非线性问题求解。在对药物的风险分级研究中,该网络能高效精确的对聚类后带有类别标签的药品数据进行训练。
5、本发明针对的是所有药物,不受药物类别的影响,相较于目前国内外研究针对的是妊娠期药物、抗癌类药物、抗菌类药物等特殊药物,我们的方法更具有适用性和推广性。
附图说明
图1是本发明的整体流程图。
图2是本发明的pnn网络拓扑图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明。
一种基于聚类和pnn的药品风险分级方法,包括如下步骤:
步骤一:构建药品风险指标。由于要根据药品的危险性对药品进行分级,因此需要量化药品的风险程度。药品风险特征的组合和选取也是提高药品风险分类中的一个重要因素。有很多种因素影响着药品不良反应的分析,其中药物发生不良反应的概率情况和该药物不良反应的严重程度是主要的影响因素。因此,本发明选取药品严重报告率和不良反应覆盖率两个指标进行药品风险特征提取:
①严重报告率
严重报告率描述了某个药品严重报告数量占所有adr报告总数的百分比。若严重报告率越大,则该药品产生的不良反应越严重,该药品越危险。假设现存在某一药品d,则严重报告率(srr)的公式为:
其中,药品d的adr报告总数量为r(d),其中严重报告数量为rs(d)。
②不良反应覆盖率
不良反应覆盖率描述了某个药品产生不良反应的个数占全部adr总数的百分比。若不良反应覆盖率越大,则该药品相对产生的不良反应种类越多,该药品越危险。假设现存在某一药品d,则不良反应覆盖率(acr)的公式为:
其中,该药品导致的adr的种类数为k(d),全部adr种类数为m。
步骤二:利用模糊c均值进行聚类。基于每个药品的srr和acr两个指标值,采用模糊c均值算法进行聚类。
步骤2.1:将模糊c均值聚类方法应用于上述数据集,算法输入包括药品名称及两个指标数据,聚类数目,模糊系数,迭代终止条件即最大迭代次数,目标函数最小误差;
设n种药品的数据样本为x={x1,x2,...,xn},c(2≤c≤n)是要将数据样本分成的类型的数目,a={a1,a2,..,ac}表示相应的c个类别,u是其相似分类矩阵,各类别的聚类中心为{v1,v2,...,vc},μk(xi)是第i种药物xi对于类ak的隶属度(简写为μik),则目标函数jb可以用下式表达:
其中,dik是欧几里得距离,用来度量第i种药品xi与第k类中心点之间的距离;m是样本的特征数;b是加权参数,取值范围是1≤b≤∞;
步骤2.2:随机初始化隶属度u和聚类中心v;
步骤2.3:通过式(5)计算每个数据相对于各个类簇的隶属度,并更新隶属度矩阵;
步骤2.4:通过式(6)计算新的聚类中心,用新的聚类中心更新聚类中心位置矩阵;
模糊c均值聚类方法就是寻找一种最佳的分类,以使该分类能产生最小的函数值jb,它要求一个样本对于各个聚类的隶属度值和为1,即满足:
样本xi对于类ak的隶属度u={μik}为
设ik={i|2≤c<n;dik=0},对于所有的i类,i∈ik,μik=0,c个聚类中心v={vi}为
步骤2.5:通过式(3)计算新的目标函数值jb;
步骤2.6:每次迭代后,计算新的目标函数与原目标函数的差值,如果|j[i]-j[i-1]≤ε|,或者迭代次数满足最大迭代次数,终止迭代过程,算法结束;否则,跳转步骤2.3继续执行。
根据此算法,我们按照报告覆盖率和不良反应严重程度可以得到现有药品的风险级别,实现对于原始药品数据集的自动标注。
步骤三:物品类的风险特征提取和单个药品的风险等级标注。
针对选取的两个指标对已分类的药品集合进行打分,以确定哪类在我们看来更严重。adr覆盖率越小越好,越大越严重;不良反应严重程度也符合此描述。但是一般多发的不良反应都不具有严重性,严重的不良反应发病频率较低。结合此特性和自发报告数据特点,本发明药品的风险可以由高到低分为“adr覆盖率低且不良反应严重”、“adr覆盖率高且不良反应不严重”、“adr覆盖率低且不良反应不严重”三种情形;基于此创建药品类的风险程度评价模型,所述模型根据以下公式构建每个药品类的风险因子:
其中,risk(j)是第k类药品的得分,m是样本特征数,numj是第j类药品个数,arrtibutei是第i类药品特征j的标准化值;通过指数级增加,扩大类别之间的差异,得出有明显差异的类别得分,根据得分函数的大小,即可进行药品风险程度评价;严重报告率越大,adr覆盖率越大,即该药物风险级别越大,呈现正相关。
步骤四:基于概率神经网络的药品风险等级预测
概率神经网络使用parzen窗估计法得出某一类别的条件概率密度函数估计值,再通过判别函数计算输入样本,训练网络模型,最后用判别函数最大值所对应的类别对样本进行标记,即可实现药物风险级别的预测。算法流程如下:
步骤4.1:确定隐含层神经元径向基函数中心,
设训练集样本输入矩阵p和输出矩阵t分别为:
其中,pij表示第j个训练样本的第i个输入变量;tij表示第j个训练样本的第i个输出变量;r为输入变量的维数;k为输出变量的维数,对应k个类别;q为训练集样本数;
隐含层的每个神经元对应一个训练样本,即q个隐含层神经元对应的径向基函数中心为:
c=p'(k)(9)
步骤4.2:确定隐含层神经元阈值,
为了简便起见,q个隐含层神经元对应的阈值为:
b1=[b11,b12,...,b1q]'(10)
其中
步骤4.3:确定隐含层与输出层间权值,
当隐含层神经元的径向基函数中心及阈值确定后,隐含层神经元的输出便可以由式(11)计算:
ai=exp(-||c-pi||2b1),i=1,2,...,q(11)
其中pi=[pi1,pi2,...,pir]'为第i个训练样本向量;
隐含层与输出层间的连接权值w取为训练集输出矩阵,即:
w=t(12)
步骤4.4:输出层神经元输出计算,
当隐含层与输出层神经元间的连接权值确定后,便可以计算出输出层神经元的输出,即:
ni=lw2,1ai,i=1,2,...,q(13)
yi=compet(ni),i=1,2,...,q(14)
通过以上4.1-4.4步骤,依次计算隐含层神经元的径向基函数中心、阈值,隐含层与输出层间权值,再通过测试集样本类别,不断修正网络参数,即完成了基于概率神经网络的分类器构建。对于一种风险标签未知的新药物,只需要输入其srr和acr两个指标值,即可预测该药物风险等级。
以上显示和描述了本发明的基本原理、主要特征和优点。本领域的技术人员应该了解,本发明不受上述具体实施例的限制,上述具体实施例和说明书中的描述只是为了进一步说明本发明的原理,在不脱离本发明精神范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!