基于指示性语言范式的孤独症早期评估装置及系统的制作方法
本发明涉及图像处理、语音识别领域,尤其涉及一种基于指示性语言范式的孤独症早期评估装置及系统,通过采集实验环境内指示性语言范式试验过程中的被试者、评估者、照顾者及指示道具的多模态音视频数据并加以分析,以评估预测孤独症谱系障碍的系统。
背景技术:
随着医学的进步,社会对孤独症谱系障碍(autismspectrumdisorder,asd,简称孤独症)日益关注。孤独症是一种在儿童中高发,早期治疗更容易康复的病症。然而,由于低龄人群的沟通能力有限,尽早发现儿童中的孤独症患者是一件非常困难的事。孤独症的早期筛查,要求诊治医生有极高的专业性和经验积累,且评估结果具有一定的主观性。这也使得对孤独症的评估需要遵循合适结构化流程和量表,以减小诊断误差,保持客观。孤独症诊断观察量表(autismdiagnosticobservationschedule,ados)是目前广泛使用的诊断量表之一。孤独症的早期诊断中,儿童的语言能力及语言理解能力,是一项需要判断的重要指标。为了结构化诊断,医生通常会采用范式试验对儿童的能力进行打分。程序化的试验,使得计算机的辅助诊断有了可能。使用语音处理和图像处理技术,能够更准确更范化更客观对儿童进行诊断。
目前,关于儿童语音理解能力进行评估的计算机方案已经有一定程度的进展。专利号为cn201811547871.x的专利申请文件公开了一种自闭症儿童日常用语康复训练装置,通过对儿童的日常用语进行分析;专利号为cn201811220434.7的专利申请文件公开了一种刻板特异用语检测系统、方法、计算机设备和存储介质,通过对儿童语言刻板性、韵律进行分析;专利号为cn201821565743.3的专利申请文件公开了一种自闭症儿童语言交流训练系统、玩具、装置,通过语音合成器对儿童进行刺激并观察;专利号为cn201110328413.9的专利申请文件公开了一种提高孤独症儿童社会互动能力的人机互动多模态早期干预系统,通过人机互动帮助儿童学习对社交语言的理解;专利号为cn201910108857.8的专利申请文件公开了一种自闭症儿童早期语言与认知能力筛查的方法及装置,通过研究儿童看图片的眼动信息对儿童的语言与认知能力进行分析。可见,由于社会互动场景的多变性和复杂性,对于真实场景中真人语音刺激下儿童对语言的理解相关计算机研究尚不足。尤其是对于指示性语言理解的分析,需要考虑到语音内容及环境的对应关系,单一范围和维度的数据采集难以得到有效的分析。
因此,如果能够使用一种方案,创建一个儿童能自由活动的互动环境,无需穿戴设备即可完整采集语言互动环境的数据,建立语音内容和环境的对应关系,通过计算及对儿童的指示性语言的能力进行分析,将会更有效、更准确、更范化地对儿童的孤独症风险系数进行评估。
技术实现要素:
针对现有技术的不足,本发明提出一种指示性语言范式的孤独症早期评估装置及系统,通过机器学习模型进行训练分类器,以评估被试者对指示性语言的理解和行为反应来预测被试者患有孤独症的风险系数,可用于孤独症早期评估。
本发明的技术方案是这样实现的:
一种基于指示性语言范式的孤独症早期评估装置,包括
数据获取模块,用于获取实验环境内指示性语言范式试验过程中的被试者、评估者、照顾者及指示道具的多模态音视频数据;
预处理模块,用于基于时间戳同步对齐所获取的多模态音视频数据,并通过语音识别获取指示性语言发出后预设时间内的特定多模态音视频数据;
特征获取模块,用于根据预处理模块处理后的特定多模态音视频数据,获取指示性语言内容所针对对象的位置信息,并逐帧获取视频帧中被试者的相关特征信息,所述相关特征信息包括面部朝向信息、眼神朝向信息、手势信息、姿势信息中的一种或多种;
训练分类器模块,根据所述相关特征信息,并结合指示性语言内容所针对对象的位置信息进行分析,确定相关特征信息是否与指示性语言内容所针对对象相关,并根据分析结果进行训练分类器,得到孤独症预测模型;
预测评估模块,用于根据指示性语言内容所针对的人或物的位置信息及被试者的相关特征信息,通过孤独症预测模型进行预测评估,并得出评估结果。
进一步的,特征获取模块包括
声纹识别单元,用于通过声纹识别对音频数据中说话人进行身份识别,以确定被试者及照顾者身份,进而再通过面部朝向信息获取单元、眼神朝向信息获取单元、手势信息获取单元、姿势信息获取单元和/或位置信息获取单元获取被试者及照顾者的相应特征信息;
语音内容信息获取单元,用于通过语音识别将说话者的语音进行文本转换,以获取语音内容信息;
面部朝向信息获取单元,用于通过脸部检测获取脸部特征点,并确定其空间的3d特征点云;通过脸部特征点的3d特征点云确定脸部平面的法线向量,从而获取面部朝向信息;
眼神朝向信息获取单元,用于根据视频帧中双眼特征点的像素点坐标和深度数据,确定双眼特征点的空间3d坐标;并以双眼特征点的空间3d坐标作为目光追踪神经网络模型的输入,从而获取眼神方向信息;
手势信息获取单元,用于通过物体检测神经网络所训练的手势检测器,获取视频帧中的手势及手指指向信息;
姿势信息获取单元,用于通过训练好的卷积神经网络对被试者的人体关键点进行估计,各关键点连结成骨架图进而识别人体姿势;
位置信息获取单元,用于获取指示性语言内容所针对对象的位置信息。
进一步的,特征获取模块还包括
反应时间获取单元,用于获取指示性语音发出后被试者的反应时间。
进一步的,还包括
身份重识别单元,用于根据在视频帧中所获取的指示性语言内容所针对对象进行身份重识别。
进一步的,所述身份识别单元包括
识别子单元,用于通过语音识别指示性语言内容所针对对象;
检测子单元,用于根据预设算法模型在视频帧中截取所针对对象的矩形框;
重识别子单元,用于通过深度神经网络将检测子单元中所截取的矩形框内容与预先设置的矩形框内容作为输入提取特征后进行特征比对,计算二者的欧式距离,根据欧拉距离确定检测子单元中的矩形框内容是否为指示性语言内容所针对对象;
其中,通过对视频帧中指示性语言内容所针对对象进行身份重识别后,再通过位置信息获取单元获取指示性语言内容所针对对象的位置信息。
进一步的,训练分类器模块中,所述确定所述相关特征信息是否与指示性语言内容所针对对象相关包括:被试者的面部朝向方向是否为指示性语言内容所针对对象所在方向、被试者的眼神朝向方向是否为指示性语言内容所针对对象所在方向、被试者的手势方向是否为指示性语言内容所针对对象所在方向和/或被试者的姿势方向是否为指示性语言内容所针对对象所在方向。
一种基于指示性语言范式的孤独症早期评估系统,包括所述基于指示性语言范式的孤独症早期评估装置、安装于实验场地四周的多个深度图像采集装置、设置于实验场地内的语音采集装置和放置于实验场地内的指示道具,其中
深度图像采集装置,用于采集实验环境内试验过程中的视频数据,所述视频数据中包括图像的深度信息;
语音采集装置,用于采集试验过程中的音频数据;
指示道具,用于进行指示性语言试验所用到的用于被指示的试验道具;
所述深度图像采集装置和语音采集装置皆与所述孤独症早期评估装置连接。
进一步的,所述语音采集装置为麦克风阵列和/或可穿戴式麦克风,均可用于在试验场景中采集多声道的环境声音、不同参与人员说话语音、任务声音等,可穿戴式麦克风可包括分别用于佩戴于被试者身上的第一麦克风、用于佩戴于评估者身上的第二麦克风、用于佩戴于照顾者身上的第三麦克风。与现有技术相比,本发明具有以下优点:本发明通过流程化的指示性语言范式试验测试被试者的指示性语言理解能力,并通过获取实验环境内指示性语言范式试验过程中的被试者、评估者、照顾者及指示道具的多模态音视频数据,深度学习框架分析试验中被试者的行为变化特征,得到孤独症预测模型;最后通过孤独症预测模型对未知孤独症情况的被试者进行孤独症评估,避免了评估人员的主观性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明基于指示性语言范式的孤独症早期评估装置一实施方式的结构框图;
图2为本发明基于指示性语言范式的孤独症早期评估系统一实施方式的结构框图;
图3为利用本发明基于指示性语言范式的孤独症早期评估系统进行指示性语言试验过程的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
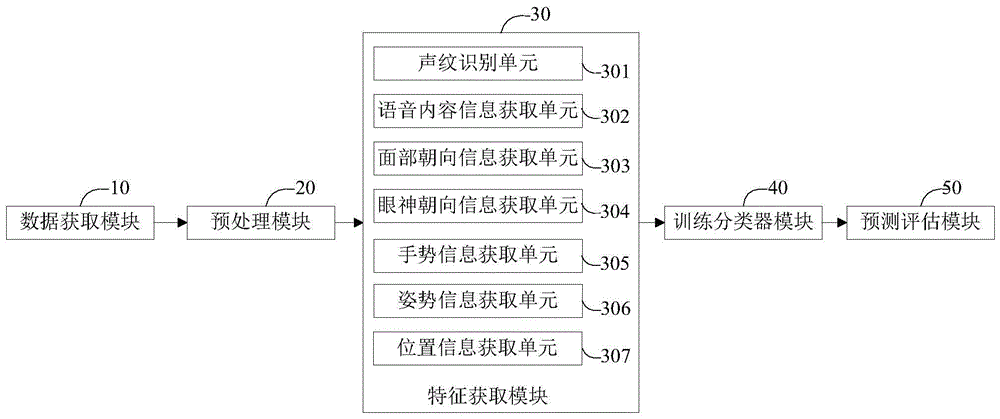
参阅图1,本发明实施方式公开的一种基于指示性语言范式的孤独症早期评估装置,包括
数据获取模块10,用于获取实验环境内指示性语言范式试验过程中的被试者、评估者、照顾者及指示道具的多模态音视频数据;
本发明实施方式中,通过对创建一个被试者能自由活动的互动性实验环境,无需复杂穿戴设备即可完整采集语音互动环境的数据,建立语音内容和环境的对应关系,然后通过图像采集装置及语音采集装置记录指示性语言范式试验过程的多模态音视频数据。本发明实施方式的试验过程是在一个自由活动的互动环境下,能保证数据的准确性。
预处理模块20,用于基于时间戳同步对齐所获取的多模态音视频数据,并通过语音识别获取指示性语言发出后预设时间内的特定多模态音视频数据;
本发明实施方式中,为了能准确地采集被试者及照顾者的数据,本发明实施方式将摄像头设置于标准化环境的四周,以便能多角度记录试验过程中被试者的行为变化,因此,在获取被试者的相关特征信息之前,先将多个摄像头所录制的视频数据基于时间戳进行同步对齐,再将视频数据与音频数据在时间轴上同步对齐后。
通过语音识别评估者发出指示性语言的时间点,并以此作为试验起始时间点,获取起始时间点之后预设时间内的多模态音视频数据,作为分析数据。其中预设时间即为对被试者进行指示性语音范时试验过程所持续的时间。
特征获取模块30,用于根据预处理模块20处理后的特定多模态音视频数据,获取指示性语言内容所针对对象的位置信息,并逐帧获取视频帧中被试者的相关特征信息,所述相关特征信息包括面部朝向信息、眼神朝向信息、手势信息、姿势信息中的一种或多种;
本发明实施方式中,由于在指示性语言范式试验过程中,是根据评估者的指示性语言,来观察儿童的理解能力和行为反应能力,因此在此过程中,需要看被试者是否看向、指向或朝向指示性语言所针对对象。例如,当评估者发出指示性语言“妈妈在哪里?”,根据被试者的面部朝向信息、眼神朝向信息、手势信息或姿势信息确定其是否理解评估者的话,并作出相应反应,如看向妈妈或手指指向妈妈等。
训练分类器模块40,根据所述相关特征信息,并结合指示性语言内容所针对对象的位置信息进行分析,确定相关特征信息是否与指示性语言内容所针对对象相关,并根据分析结果进行训练分类器,得到孤独症预测模型;
本发明实施方式中,根据被试者的面部朝向信息、眼神朝向信息、手势信息或姿势信息,并结合指示性语言内容所针对对象的位置信息,确定相关特征信息是否与指示性语言内容所针对对象相关,即确定被试者是否理解评估者所说的指示性语言,如被试者的手指指向是否为针对对象所在位置方向、或者脸是否朝向针对对象所在位置方向等。
因此,训练分类器模块40中,所述确定所述相关特征信息是否与指示性语言内容所针对对象相关包括:被试者的面部朝向方向是否为指示性语言内容所针对对象所在方向、被试者的眼神朝向方向是否为指示性语言内容所针对对象所在方向、被试者的手势方向是否为指示性语言内容所针对对象所在方向和/或被试者的姿势方向是否为指示性语言内容所针对对象所在方向。
根据被试者的面部朝向、眼神朝向、手势朝向、姿势朝向是否朝向指示性语言内容所针对对象,进行训练分类器,确定孤独症预测模型。
本发明实施方式中,使用有监督学习分类器训练分类器。其中,监督学习分类器包括支持向量机、逻辑回归、k近邻、神经网络等。具体地,在本发明实施方式中,使用支持向量机(supportvectormachine,svm)对已标记的特征进行分类。上述被试者的面部朝向、眼神朝向、手势朝向、姿势朝向是否朝向指示性语言内容所针对对象作为输入特征x,每个被试者的孤独症情况打分分数y作为标签,使用支持向量机svm进行分类模型的训练,通过对最大间隔超平面
ω·x-b=0
进行学习可以求得最优ω和b,进而得到孤独症预测模型。
预测评估模块50,用于根据指示性语言内容所针对的人或物的位置信息及被试者的相关特征信息,通过孤独症预测模型进行预测评估,并得出评估结果。
本发明实施方式中,通过对已知孤独症情况的被试者进行试验,根据所试验出的数据进行训练分类器,得到孤独症预测模型;最后再根据未知孤独症情况的被试者面部朝向、眼神朝向、手势朝向、姿势朝向是否朝向指示性语言内容所针对对象,通过孤独症预测模型进行预测评估,得出评估结果,为医生提供参考。
由于本发明实施方式主要用于儿童孤独症的早期筛选,因此本发明实施方式中的被试者为儿童,但不限于儿童;评估者可为医生或其他医疗工作人员,照顾者可父母或者与父母共同生活两周以上的人。
本发明通过流程化的指示性语言范式试验测试被试者的指示性语言理解能力,并通过获取实验环境内指示性语言范式试验过程中的被试者、评估者、照顾者及指示道具的多模态音视频数据,深度学习框架分析试验中被试者的行为变化特征,得到孤独症预测模型;最后通过孤独症预测模型对未知孤独症情况的被试者进行孤独症评估,避免了评估人员的主观性。
进一步的,特征获取模块30包括声纹识别单元301、语音内容信息获取单元302、面部朝向信息获取单元303、眼神朝向信息获取单元304、手势信息获取单元305、姿势信息获取单元306、位置信息获取单元307,其中
声纹识别单元301,用于通过声纹识别对音频数据中说话人进行身份识别,以确定被试者及照顾者身份,进而再通过面部朝向信息获取单元、眼神朝向信息获取单元、手势信息获取单元、姿势信息获取单元和/或位置信息获取单元获取被试者及照顾者的相应特征信息;
语音内容信息获取单元302,用于通过语音识别将说话者的语音进行文本转换,以获取语音内容信息;
面部朝向信息获取单元303,用于通过脸部检测获取脸部特征点,并确定其空间的3d特征点云;通过脸部特征点的3d特征点云确定脸部平面的法线向量,从而获取面部朝向信息;
眼神朝向信息获取单元304,用于根据视频帧中双眼特征点的像素点坐标和深度数据,确定双眼特征点的空间3d坐标;并以双眼特征点的空间3d坐标作为目光追踪神经网络模型的输入,从而获取眼神方向信息;
手势信息获取单元305,用于通过物体检测神经网络所训练的手势检测器,获取视频帧中的手势及手指指向信息;
姿势信息获取单元306,用于通过训练好的卷积神经网络对被试者的人体关键点进行估计,各关键点连结成骨架图进而识别人体姿势;
位置信息获取单元307,用于获取指示性语言内容所针对对象的位置信息。
本发明实施方式中,由于不同的被试者面对评估者的指示性语言提问时,会有不同的反应,此时所对应的特征信息不同,根据被试者面部朝向、眼神朝向、手势朝向、姿势朝向是否朝向指示性语言内容所针对对象进行训练分类器。其中,在获取被试者的特征信息前,先将视频数据与音频数据在时间轴上同步对齐后,逐帧获取在指示性语言后预设时间内视频帧中被试者的相关特征信息。具体的
面部朝向信息获取单元303,用于利用dlib的正脸检测获取rgb视频帧中的人正脸的68个特征标记点,根据这68个特征点的深度数据结合空间坐标变换公式计算每个特征点的空间3d坐标,组成脸部的特征点云坐标;根据所述特征点云坐标计算脸部平面的法线向量,该法线向量即为脸部朝向的方向向量,最后将法线向量转化为三个欧拉角yaw,pitch,roll,从而确定头部朝向信息。
眼神朝向信息获取单元304,用于利用dlib的正脸检测获取rgb视频帧中人的脸部特征点,从中确定双眼的特征点后结合深度数据利用空间坐标变换计算出双眼特征点的空间3d坐标,以双眼的空间3d坐标作为目光追踪神经网络模型的输入,从而获取眼神朝向信息。
手势姿势信息获取单元305,用于检测与识别被试者的手势。使用labelimg工具定位并切分出大量手部图片数据,标注成pascalvoc数据集的格式,每个数据都包含了手势的矩形框的坐标。然后使用yolov3算法训练出一个手势的检测器,该检测器能检测画面中的手部,识别出被试者指示人或物的手势,并给出其矩形框坐标以及所属的手指的指向。
姿势信息获取单元306,通过在coco关键点检测的数据集上训练高分辨率网络hrnet(high-resolutionnet),对于每一张输入的视频帧,该神经网络输出由回归量估算的热点图各个人体关键点位置,将各关键点连接起来构成人体骨架图,从而获取别试者的姿势。
进一步的,特征获取模块30还包括
反应时间获取单元,用于获取指示性语音发出后被试者的反应时间。
本发明实施方式中,可加入指示性语言发出后被试者的反应时间,作为训练模型的共同数据,进行训练分类器。
进一步的,基于指示性语言范式的孤独症早期评估装置还包括
身份重识别单元,用于根据在视频帧中所获取的指示性语言内容所针对对象进行身份重识别。
具体的,所述身份识别单元包括识别子单元、检测子单元和重识别子单元,其中
识别子单元,用于通过语音识别指示性语言内容所针对对象;
检测子单元,用于根据预设算法模型在视频帧中截取所针对对象的矩形框;
重识别子单元,用于通过深度神经网络将检测子单元中所截取的矩形框内容与预先设置的矩形框内容作为输入提取特征后进行特征比对,计算二者的欧式距离,根据欧拉距离确定检测子单元中的矩形框内容是否为指示性语言内容所针对对象;其中,通过对视频帧中指示性语言内容所针对对象进行身份重识别后,再通过位置信息获取单元获取指示性语言内容所针对对象的位置信息。
本发明实施方式中,无论指示的对象是人或物,都需要知道其空间位置,以便于根据被试者的相关特征信息了解被试者的理解能力及反应能力。因此,首先通过语音识别评估者的指示性语言,获取指示性语言所提及的对象后,再从视频帧中获取所提及的对象,并通过矩形框进行标识;然后还需要对所标识出的矩形框中的内容进行重识别,确定对象无误后再获取对象的3d坐标。
其中,对于指示性语言中所针对对象(如人或物或五官)进行识别时,都是通过训练好的yolov3(youonlylookonce)算法模型在rgb图像中提取指示性语言所针对对象(如人或物或五官)的矩形框,得到其矩形框的类别和坐标。
例如,当指示性语言所针对对象为人时,获取被指向的人物的矩形框后,还需要对该人物进行身份的重识别。人物重识别使用深度神经网络进行实现,使用resnet50为基础模型,将截取的人矩形框与预先设置的查询人物框作为输入提取特征后进行特征比对,计算二者的欧式距离,欧式距离在预设范围内则表明二者是属于同一个人物,否则为不同身份的人。同样,当指示性语言所针对对象为物体或五官时,同样可以采用深度神经网络进行身份重识别。
当身份重识别单元确定指示性语言内容所针对对象无误后,再根据检测子单元中所截取的矩形框内容的像素点在rgb图像中的横坐标u、纵坐标v以及对应深度图中的深度数据d,结合预先获取的摄像机的内参,代入公式计算出该像素点相对摄像机坐标系的3d坐标(x,y,z)。
z=d
其中,cx,cy,fx,fy都是摄像头组件光学参数。获取矩形框中人或物体的空间位置,先对矩形框中的所有像素深度求一个平均值
当指示性语言内容所针对对象的位置确定后,便可以根据指示性语言观察被试者的反应,获取被指者的脸部朝向信息,眼神朝向信息,手势信息和姿势信息等特征,从而进行孤独症评估。
参阅图2,本发明实施方式还公开了一种基于指示性语言范式的孤独症早期评估系统,包括所述基于指示性语言范式的孤独症早期评估装置、安装于实验场地四周的多个深度图像采集装置、设置于实验场地内的语音采集装置和放置于实验场地内的指示道具,其中
深度图像采集装置,用于采集实验环境内试验过程中的视频数据,所述视频数据中包括图像的深度信息;
语音采集装置,用于采集试验过程中的音频数据;
指示道具,用于进行指示性语言试验所用到的用于被指示的试验道具,包括指示物品,如桌子上的玩具小鸡,室内的灯泡等;
所述深度图像采集装置和语音采集装置皆与所述孤独症早期评估装置连接。
本发明实施方式中,指示道具、照顾者、被试者位于实验场地中的不同位置,便于准确确定被试者的理解能力。
本发明实施方式中,采集音视频数据为在自由活动场景中、在无需复杂穿戴设备的条件下、在隐藏采集设备的情况下,在对被试者进行指示性语言试验过程的完整音视频数据。在评估者发出指示性语言后,对预设时间内的被试者的行为反应进行判断被试者的理解能力。
语音采集装置为麦克风阵列和/或可穿戴式麦克风,均可用于在试验场景中采集多声道的环境声音、不同参与人员说话语音、任务声音等;可穿戴式麦克风可包括分别用于佩戴于被试者身上的第一麦克风、用于佩戴于评估者身上的第二麦克风、用于佩戴于照顾者身上的第三麦克风。
本发明实施方式中的深度图像采集装置可以是但不限于rgb-d摄像头,便于多角度全方位采集试验参与人员与场地的rgb和深度数据。在获取被试者的相关特征信息之前,先将多个摄像头所录制的视频数据及多个麦克风所获取的音频数据基于时间戳进行同步对齐后,再获取被试者的相关特征信息。
参阅图3,具体的,利于本发明实施方式基于指示性语言范式的孤独症早期评估系统进行指示性语言试验过程,包括以下步骤:
s1,评估者和被试者面对面坐在房间里,照顾者(本发明实施方式中为被试者的母亲)坐在房间某处,房间布置一指示物品(本发明实施方式中为一盏灯),评估者获得被试者的眼神关注。
s2,评估者在获得被试者的眼神关注后,评估者针对房间内的照顾者、指示物品、或者五官说出指示性语言,如:“宝贝,妈妈在哪里?”,“宝贝,灯在哪里?”“宝贝,鼻子在哪里?”,观察被试者是否看向被提及的人或者物品或者五官;
若是,则转到步骤s3;
若否,则转到步骤s4;
s3,观察被试者是否指向该人或物品或五官;
若是,则结束流程;
若否,则转到步骤s5;
s4,评估者提示被试者指向被提及的人或物或五官,观察被试者是否看向被提及的人或物品或五官;
若是,则转到步骤s5;
若否,则结束流程;
s5评估者提示被试者指向被提及人或物,观察被试者是否指向正确的人或物,结束流程。
本发明可在自由活动的真实场景中进行,使得实验数据更接近生活常态,更能反应被试者的综合情况,而且本发明采用半结构化的试验流程,使得评断对象和被评判数据的采集规则更统一,更具有客观性。
另外,本发明采用人工智能系统捕捉音视频并进行关键信息的提取和处理,保持了数据分析过程的尺度一致,排除人为主观性的干扰;而且由于使用计算机对数据进行分析,对评估人员的专业性和经验性要求显著降低,使得评估更容易普及。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!