用于为个人用户生成个性化的饮食和健康建议或推荐的自动方法和系统与流程
相关申请的交叉引用
本申请要求于2018年12月19日提交的美国临时专利申请第62/782,275号的权益和优先权,并且要求于2019年12月10日提交的美国专利申请第16/709,721号的权益和优先权,所述申请的内容在此以全文引用的方式并入。
本文中所描述的主题的实施例总体上涉及提供个性化的饮食和健康建议或推荐以及用于自动创建所述个性化的饮食和健康建议或推荐的技术和工艺。更具体地,主题的实施例涉及自动收集和处理数据以为个人用户生成个性化的饮食和健康建议或推荐的无服务器架构。
背景技术:
近年来,已经开发了许多装置和软件应用来向客户递送健康相关数据。这些装置和软件应用可以监测活动、允许人们监测其食物消耗和运动习惯、监测睡眠模式并且被动地从用户收集健康信息。然而,目前尚无用于标准化和共同处理所有这种数据的行业标准。特别地,收集到的数据难以合并,因为数据是从各种来源以各种不同格式获得的。这使用户难以获取有关其营养需求的完整信息,并且因此抑制用户做出关于食物消耗以及不同食物对其健康的影响的及时且合理的决策的能力。
整合和处理各种食物相关数据、营养数据和健康数据构成许多挑战。例如,可以将数据提供为不同的数据类型(例如,结构化或非结构化、时间序列等),并使用不同的方法或工具对所述数据进行处理,以便提取和转达有用的信息。另外,用这些装置和软件应用收集到的数据量可能巨大,以有规律间隔或随机间隔频繁地收集了近似数千个或数百万个数据点。随着装置和软件应用与用户的日常生活变得越来越紧密,要收集的数据量会随时间呈指数增长。在一些情况下,当对应用编程接口(api)进行更新时,改变可能会导致某些api发生故障,从而导致数据丢失。
因此,期望提供用于解决包含与合并和处理来自各种不同来源的食物相关数据、营养数据和健康数据有关的挑战在内的此类问题的工艺、系统、方法和技术。此外,结合附图和前述技术领域以及背景技术,其它期望特征和特性将从随后具体实施方式和所附权利要求书变得显而易见。
技术实现要素:
本文中公开了一种平台,其可以以可扩展方式处理大量食物相关数据、营养数据和健康数据,并且管理生成和处理数据的速率的不可预测性。所公开的平台还能够处理许多不同的数据类型并且可以被适配成从多个不同来源接收数据。所述平台还可以支持对底层api所做的改变,而不会经历与数据处理或数据丢失相关的问题。
本文中所公开的平台可以包含允许处理、合并和结构化大量食物相关数据、营养数据和健康数据的一个或多个模块。所述模块可以彼此解耦,由此确保易于维护每个组件或模块以及其可复用性。本文中所公开的平台可以通过采用无服务器架构来处理大量数据。在无服务器架构中,利用如
平台组件可以被配置成与许多数据类型交互。在检索模块中,一组λ函数可以被配置成从所连接的应用提取数据,并且实施定期检索数据的基于时间的任务调度器。另一组λ函数可以从所连接的应用接收通知,并且准备接收推送的数据。另一组λ函数可以将提取和推送的数据合并,并且将数据发送到通过平台级联的流。另外的λ函数可以将数据从流中转移出来进行处理,这可能会将数据转换成标准化结构化格式。可以进一步分析经转换的结构化数据,以便为用户提供对营养与健康的见解或推荐。
在本公开的一个实施例中,提供了一种数据收集和处理方法。所述方法可以使用无服务器架构来实施。所述无服务器架构可以使得方法能够扩展并且支持新的数据类型或形式或在引入新来源时提供支持。本文中所公开的方法可以包含从多个不同来源收集和聚合数据,其中所述数据包括不同类型或形式的数据。所述不同类型或形式的数据可以包含结构化数据和非结构化数据以及时间序列传感器数据。所述数据可以包含特定于多个个人用户的食物、健康或营养数据。所述方法可以进一步包含通过将所述不同类型或形式的数据转换成与健康和营养平台兼容的标准化结构化格式,以不知其来源的方式连续处理所述不同类型或形式的数据中的每种类型或形式的数据。所述方法还可以包含部分地使用来自所述健康和营养平台的信息,分析已经转换成所述标准化结构化格式的所述数据。使用一个或多个机器学习模型对所述标准化结构化数据进行分析。基于所述分析,可以为多个个人用户中的每个个人用户生成个性化的饮食和健康建议或推荐。
在一些实施例中,多个不同来源可以包含以下中两个或更多个:移动装置、可佩戴装置、医疗装置、家用电器或医疗保健数据库。所述移动装置可以包含智能装置(例如,智能电话、平板电脑),并且其中所述可佩戴装置包括以下中的一个或多个:活动跟踪器、智能手表、智能眼镜、智能环、智能贴片、抗氧化剂监测器、睡眠传感器、生物标志物血液监测器、心率变异性(hrv)监测器、应力监测器、温度监测器、自动秤、脂肪监测器或智能织物。所述医疗装置可以包含以下中的一个或多个:葡萄糖监测器、心率监测器、血压监测器、汗液传感器、胰岛素泵、酮监测器、乳酸监测器、铁监测器或皮肤电反应(gsr)传感器。本文中所描述的主题的示例性实施例可以与医疗装置(如便携式电子医疗装置)结合实施。尽管许多不同的应用是可能的,但是一个实施例可以并入胰岛素输注装置(或胰岛素泵)作为输注系统部署的一部分。为了简洁起见,与输注系统操作、胰岛素泵和/或输注器操作以及系统的其它功能方面(和系统的单独的操作组件)有关的常规技术在此可能不会详细描述。输注泵的实例(例如,胰岛素泵)可以属于但不限于以下美国专利中所描述的类型:第4,562,751号;第4,685,903号;第5,080,653号;第5,505,709号;第5,097,122号;第6,485,465号;第6,554,798号;第6,558,320号;第6,558,351号;第6,641,533号;第6,659,980号;第6,752,787号;第6,817,990号;第6,932,584号;和第7,621,893号;这些美国专利中的每个美国专利通过引用并入本文中。所述医疗保健数据库可以包含基因数据库、血液测试数据库、生物群系数据库或电子医疗记录(emr)。
在一些实施例中,来自所述多个不同来源的所述数据可以包含在一天中不均匀分布的至少近似106个每日数据点。可以通过多个应用编程接口(api)从所述多个不同来源收集和聚合所述数据。在一些情况下,数据的处理不受底层api的改变或更新的影响,使得在对底层api进行改变或更新时,能够在不丢失数据的情况下对数据进行处理。
在一些实施例中,所述收集和聚合所述数据可以包含将所述数据存储在多个流中。所述处理所述数据可以进一步包含在出现不同条件时,对存储在所述多个流中的所述数据执行λ函数。仅在所述数据收集和存储在所述多个流中时才执行所述λ函数。所述对所述存储的数据执行所述λ函数被配置成将每行数据引导和传递到来自所述多个流的相关流。可以通过从所述多个流中的一个流级联到另一个流来使所述数据沿数据流水线行进。
在一些实施例中,所述收集和聚合来自所述多个不同来源的所述数据可以包含(1)从允许提取数据的第一组来源提取数据,以及(2)接收从第二组来源推送的数据,使得来自多个提取请求和推送请求的数据流式传输到集中式位置中。可以使用任务调度器以预定时间间隔从所述第一组来源提取所述数据。随着或当数据从所述第二组来源推送时,也可以从所述第二组来源接收数据。在一些情况下,从所述第二组来源推送所述数据之前可以是与所述数据相关联的一个或多个通知。在其它情况下,如果与对应通知相关联的数据没有与所述对应通知一起到达,则所述数据。在一些情况下,所述第一组来源和所述第二组来源可以包含所述第一组和所述第二组两者共有的一个或多个来源。在其它情况下,所述第一组来源和所述第二组来源可以包含彼此不同的来源。
在一些实施例中,所述多个流中的每个流可以具有定义时间帧的保持策略,在所述时间帧中,所述数据存储在每个流中。所述时间帧的范围可以为例如从约24小时到约168小时。可以以解耦的方式将所述数据存储在所述多个流中,而不需要每个数据的一个或多个来源的先验知识。所述多个流可以包含多个碎片。每个碎片可以包含(1)进入到队列中并且(2)在所述保持策略到期时退出所述队列的数据记录串。所述数据记录串可以包含特定于多个个人用户的食物消耗、健康或营养记录。可以通过控制所述多个流中的碎片的数量来控制处理所述数据的速度。
在一些实施例中,所述方法可以包含通过与一个或多个不同实体相关联的令牌模块与所述多个api通信。来自所述多个api的所述数据可以是使用检索模块收集和聚合的,由此所述检索模块可以与所述令牌模块解耦并且独立于所述令牌模块。所述令牌模块可以被配置成刷新现有令牌并且提供关于令牌改变的通知更新。每当新令牌生成时,除存储在所述令牌模块中之外,所述新令牌也可以在所述检索模块中单独地复制。在一些情况下,检索模块可以仅被配置成收集和聚合数据,并且没有被配置成保存、存储或处理数据。
在一些实施例中,可以将收集到的数据中的一些或全部提供给健康和营养平台并在其中使用。另外地或任选地,可以将收集到的数据的一部分传输到一个或多个第三方。在将数据提供给健康和营养平台并在其中使用之前,可以将所述数据转换成标准化结构化格式。
在一些实施例中,可以将来自所述多个数据来源的数据收集和聚合在存储模块中。所述存储模块可以被配置成验证、检查和移除副本数据。所述存储模块可以被配置成分批保存所述数据。所述存储模块可以被配置成通过合并所选择类型的数据来缩减所述数据。
在一些情况下,所述存储的数据的一部分可以包含使用一个或多个成像装置捕获的多个图像。可以对所述存储的数据的所述一部分执行所选择λ函数以检测所述多个图像中的任何图像是否包括要针对其营养成分进行分析的一个或多个食物图像。所述一个或多个食物图像可以与时间戳和地理位置相关联,由此使得能够对用户的食物摄入进行时间和空间跟踪。所述对所述用户的食物摄入进行时间和空间跟踪可以包含预测餐食的消耗时间或餐食的成分。
在本公开的另一个实施例中,提供了一种无服务器数据收集和处理系统。所述系统可以包含检索模块,所述检索模块被配置成从多个不同来源收集和聚合数据,其中所述数据包括不同类型或形式的数据。所述系统还可以包含标准化模块,所述标准化模块被配置成通过将所述不同类型或形式的数据转换成与健康和营养平台兼容的标准化结构化格式,以不知其来源的方式连续处理所述不同类型或形式的数据中的每种类型或形式的数据。
提供本发明内容以便以简化的形式介绍下文在具体实施方式中进一步描述的一系列概念。本发明内容不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用作确定所要求保护的主题的范围的辅助手段。应当理解,可以单独地、共同地或彼此结合地理解本公开的不同实施例。本文中所描述的本公开的各个实施例可以应用于下文所阐述的特定应用中的任何特定应用,或者可以应用于任何其它类型的健康、营养或食物相关的监测/跟踪/推荐系统和方法。
附图说明
在结合以下附图考虑时,通过参考具体实施方式和权利要求书可得到主题的更完整的理解,其中,在所有附图中,类似的参考数字指代类似的元件。
图1展示了根据一些实施例的生态系统;
图2示出了根据一些实施例的平台的框图;
图3示出了根据一些实施例的令牌模块的组件;
图4示出了根据一些实施例的接收模块的组件;
图5示出了根据一些实施例的流水线模块的组件;
图6示出了根据一些实施例的标准化模块的组件;
图7示出了根据一些实施例的存储模块的组件;
图8示出了根据一些实施例的图3的令牌模块的实例;
图9示出了根据一些实施例的图4的检索模块的实例;
图10示出了根据一些实施例的图5的流水线模块的实例;
图11示出了根据一些实施例的图6的标准化模块的实例;
图12示出了根据一些实施例的图7的存储模块的实例;
图13是展示了根据所公开的实施例的使用无服务器架构实施的计算机实施的数据收集和处理方法的流程图,所述无服务器架构包含用于通过基于硬件的处理系统生成个性化的饮食和健康建议或推荐的健康和营养平台;
图14是展示了根据所公开的实施例的用于收集和聚合来自多个不同来源的数据的方法的流程图;
图15是展示了根据所公开的实施例的用于将来自多个不同来源的数据收集和聚合在存储模块中的方法的流程图;
图16是展示了根据所公开的实施例的用于将从多个不同来源收集到的和聚合的数据存储在存储模块中并且对所述收集到的和聚合的数据进行处理的方法的流程图;
图17是展示了根据所公开的实施例的用于将从多个不同来源收集到的和聚合的数据存储在多个流中的方法的流程图;并且
图18是展示了根据所公开的实施例的用于分析图像以确定其营养成分的方法的流程图。
具体实施方式
以下具体实施方式在本质上仅仅是说明性的并且不旨在限制本主题或本申请的实施例或此类实施例的应用和使用。如本文所使用的,词语“示例性”意指“用作实例(example)、实例(instance)或说明”。本文中描述为示例性的任何实施方案不一定被解释为优于或胜过其它实施方案。此外,不旨在被存在于上述技术领域、背景技术、发明内容或以下具体实施方式中的任何表述或暗示的理论约束。另外,应当注意,本说明书中提及的所有公开、专利以及专利申请通过引用并入本文,其程度如同每个单独的公开、专利或专利申请被专门地且单独地指示通过引用并入。
现将详细参考本公开的示例性实施例,附图中展示了这些示例性实施例的实例。适当的时候,贯穿附图和公开,将使用相同的附图标记来指代相同或相似的部分。
现今,存在许多收集来自个人的健康、营养和健身数据的应用。一些应用可以在移动手机或可佩戴装置上实施,并且可以被动地跟踪活动水平和生命统计资料(如心跳、血压和胰岛素水平)。一些应用可以允许用户记录其饮食、运动例程和睡眠习惯,并且可以根据记录的数据计算健康度量。个人可能难以跟踪从多个应用获得的大量数据。离散数据集通常可能无法向用户提供必要的见解,尤其是在用户不能完全理解不同类型或组的健康和营养数据之间的影响和关系的情况下。因此,用户可能缺乏采取可行步骤以改善其健康或幸福感的必要工具。平台(如本文中所公开的)可以被配置成从多个应用收集和合并大量健康数据、食物相关数据和营养数据,并且对数据进行处理以便为用户提供更加精确和有用的营养和/或健康信息。在一些情况下,神经网络和其它机器学习算法可以用于分析数据并且为个人用户提供个性化的健康推荐。
本文中所公开的平台可以(1)收集和聚合由用户提交和/或从不同类型的第三方应用检索的数据,以及(2)通过将不同类型或形式的数据转换成与健康和营养平台兼容的标准化结构化格式,以不知其来源的方式处理数据。在一些实施例中,本文中所公开的平台可以与健康和营养平台集成或作为其一部分提供。在其它实施例中,本文中所公开的平台可以与健康和营养平台分开提供。可以设想对本文中所公开的平台或与本公开一致的健康和营养平台的任何修改。健康和营养平台的实例在美国专利申请第13/784,845和第15/981,832号中进行了描述,所述两个美国专利申请以全文引用的方式并入本文中。
本文中所公开的平台可以使用具有自主函数的无服务器架构来实施以在数据通过平台流式传输时处理大量健康和营养数据。采用无服务器架构可以允许平台处理大量数据,例如每天处理可能在一天中均匀分布或不均匀分布的近似106个数据点。使用无服务器架构在减小与数据流量的大波动相关联的不可预测性方面是有利的,因为服务器资源是根据传入的数据流按照需要和在需要时使用的。可以响应于特定事件(如何时接收或存储数据项)来触发自主函数。使用无服务器架构实施平台还可以提供成本益处,因为仅在调用某些函数时才会产生费用。此外,所述函数可以在短时间段内运行,这消除了与连续的处理器使用相关联的成本。当不接收数据时,不需要触发自主函数,并且因此不会产生处理成本。用无服务器架构实施平台的另外的优点是,此种架构可以在不会产生与使用常规的基于服务器的系统相关联的成本情况下允许可扩展性。随着更多数据由无服务器平台处理,触发自主函数以处理数据的调用次数将增加。另外的成本基于增加的函数调用次数。使用所公开的平台可以实现节省,因为可以使用无服务器架构来避免在另外的服务器资源、维护或人员方面的投资。
如本文中所描述的无服务器架构可以是软件设计部署,其中应用由第三方服务托管。第三方服务的实例可以包含
为了在无服务器架构内工作而开发的应用可以通过可以单独地调用和扩展的单独的自主函数进行分解。在本文中所描述的一些第三方服务的实例中,所述函数可以称为例如λ函数、twilio函数和azure函数。这些函数是在其响应于事件而被触发时会执行计算操作的无状态容器。所述这些函数是短暂的,这意指其可以在一次调用期间或含有有限制次数的调用的时间段内使用计算能力,而不是连续使用计算能力。自主函数可以由第三方服务完全管理。具有自主函数的无服务器架构有时可以被称为“功能即服务(faas)”。自主函数可以使用各种编程语言来实施,取决于底层无服务器架构所支持的语言。示例语言包含java脚本(javascript)、python、go、java、c和scala。
由自主函数执行的计算任务可以包含存储数据、触发通知、处理文件、调度任务和扩展应用。例如,自主函数可以从移动应用接收请求作为应用编程接口(api)调用、检验属于请求内参数的值、基于检验出的值执行操作、产生输出并通过修改数据库内的表条目来将输出数据存储在数据库中。由自主函数执行的处理操作的实例可以是pdf文件或图像文件上的光学字符识别(ocr),从而将符号转换成可编辑文本。调度的任务的实例可以是定期从数据库中移除副本条目、从所连接的应用请求数据以及更新访问令牌。自主函数可以充当应用的扩展,从而从应用检索数据并将数据发布到第三方服务进行处理。例如,可以使用自主函数将服务台票证转发到单独的帮助台聊天程序以供员工查看。
使用无服务器架构(如本文中所描述的那些无服务器架构)的优点是其易于扩展。可以因需要资源而执行横向扩展或添加另外的资源。例如,如果所处理的请求的量扩大,则架构可以自动获得另外的计算资源。短暂自主函数可以使扩展更加容易,因为其可以根据运行时间需要来进行创建和销毁。因为无服务器架构是标准化的,所以在发生问题的情况下/在发生问题时,更易于维护。
使用无服务器架构的另一个优点是,无服务器架构可以具有成本效益。因为自主函数是短暂的,所以仅在调用函数时才可以使用计算能力。因此,当不调用函数时,计算能力不需要任何费用。当请求仅是偶尔的时或者当流量不一致时,这种支付结构具有优点。如果服务器正在连续运行,但是每分钟仅处理一个请求,则所述服务器可能效率较低,因为与服务器启动和运行的时间相比,处理请求的时间量较低。相比之下,在无服务器架构的情况下,短暂的自主函数将会使用计算能力来处理请求并在其余时间保持休眠。当流量不一致时,可能会在请求不频繁时使用很少的计算能力。当流量激增时,可能会使用大量的计算能力。在传统环境中,可能需要增加硬件计数来处理流量高峰,但是当流量减少时,硬件将会被浪费。然而,在无服务器环境中,灵活的扩展允许仅在流量高峰期间增加支付,并且在低流量时间段期间节省金钱。
本文中所公开的无服务器架构可以合并和处理流式传输数据。流式传输数据是由多个来源连续生成并同时处理的数据。当数据生成时,无服务器架构可以快速且及时地(例如,基本上实时地)收集和处理流式传输数据。这与收集数据、将其存储在数据库中并且随后对其进行分析形成对比。无服务器架构可以具有为了捕获、变换和分析数据而专门设计的服务。这些服务可以补充自主函数,以对流式传输数据进行压缩、加密并将其转换成可与不同种类的第三方应用互操作的格式。
自主函数可以使得平台能够执行许多任务,例如认证、授权、数据合并、数据传输、数据处理和标准化等。某些自主函数可以与外部应用编程接口(api)通信,并且交换、存储、更新和删除访问令牌以管理应用许可。自主函数中的一些自主函数可以从将数据推送和提取到平台中并将所有收集到的数据合并到流中的所连接的应用检索数据。其它自主函数可以将流式传输的数据传输到平台的其它组件。一些其它自主函数可以通过对数据进行分选、将数据转换成不同的文件格式、移除冗余数据和/或使数据标准化来处理数据。一些其它自主函数可以对数据进行预处理以进行存储和分析。
平台中的模块可以解耦以允许易于维护或更新。如本文中所描述的模块可以可互换地被称为组件。相反,如本文中所描述的模块可以包含一个或多个组件,使得所述模块包括组件组。通过解耦模块,数据可以流过平台组件,并且可以在不会丢失数据的情况下对其进行处理。例如,令牌可以从一个组件复制到另一个组件,并且两个组件可以解耦,使得其不依赖于彼此。在一些情况下,一个组件可以被配置用于对流进行重定向,而另一个组件可以被配置用于进行处理。第三个组件可以被配置用于进行存储。可以以模块化方式设计本文所公开的平台,其中每个模块被配置成在不需要对一个或多个其它模块的互操作依赖性的情况下执行特定函数。
所公开的具有无服务器架构的平台非常适于进行大数据处理,从而为平台提供了将多种不同类型或形式的数据聚合成与健康和营养平台或与其它第三方应用兼容的标准化结构化格式的灵活性。平台可以从用户收集数据,并且还可以与来自各种第三方应用的多个api集成以收集其它类型的数据。在一些实施例中,平台可以创建正在从各种来源(例如,从因特网、预先存在的数据库、用户输入等)持续更新的食物本体,以组织和分析所有食物类型(例如,初级食物、包装食物、食谱、餐厅菜肴等)的任何可获得的信息。在一些实施例中,平台还可以使得用户能够手动记录有关所消耗的餐食、进行的运动或活动、睡眠量以及其它健康数据的信息。在一些实施例中,平台与第三方应用的集成可以允许平台在多个数据收集装置和服务(例如,移动装置、葡萄糖传感器、医疗保健提供者数据库等)之间生成个性化的数据网络以集成可能受新陈代谢影响或可能影响新陈代谢的生物标志物(例如,睡眠、运动、血液测试、应力、血糖、dna等)的任何可获得的信息。平台与由如美敦力公司(medtronic)、雅培公司(abbott)、德康公司(dexcom)等公司制造的医疗装置的集成可以为平台提供如装置使用数据和健康相关数据等数据。平台可以通过连接或关联各种信息来综合食物本体、手动日志和个性化的数据网络以对不同食物如何影响每个个人提出见解,并且进一步为每个个人生成个性化的食物、健康和保健推荐。
平台的实施例可以利用例如
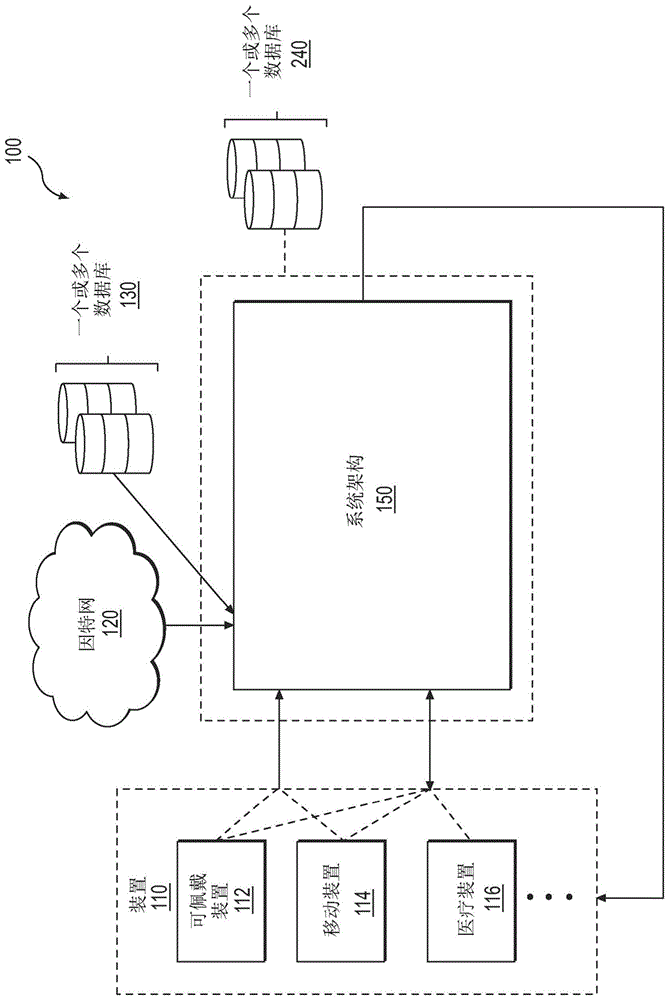
以下参考附图的描述提供了可以在其中实施平台的环境的上下文,并且详细描述了平台的结构以及通过平台的数据流。图1展示了根据一些实施例的生态系统100。一方面,生态系统100可以包含系统架构或平台150。平台可以从多个不同来源(例如,装置110、因特网120和一个或多个数据库130)收集和聚合数据。如图1中所示出的,生态系统100可以包含装置110。装置110可以包含可佩戴装置112(例如,智能手表、活动跟踪器、智能眼镜、智能环、智能贴片、智能织物等)、移动装置114(例如,手机、智能电话、录音机等)和/或医疗装置116(例如,葡萄糖监测器、胰岛素泵、血压监测器、心率监测器、汗液传感器、皮肤电反应(gsr)传感器、皮肤温度传感器等)。在一些情况下,装置110可以包含家用电器(例如,可以跟踪食物和饮食习惯的智能冰箱、可以跟踪所消耗的食物的量和类型的智能微波炉等)或可以跟踪用户的身体活动水平的游戏机。装置110可以彼此通信。平台150可以同时或在不同时间实例处与装置110中的一个或多个装置通信。
装置110可以包括一个或多个传感器。传感器可以是被配置成检测信号或获取信息的任何装置、模块、单元或子系统。传感器的非限制性实例可以包含惯性传感器(例如,加速度计、陀螺仪、可以形成惯性测量单元(imu)的重力检测传感器)、位置传感器(例如,全球定位系统(gps)传感器、启用位置三角测量的移动装置发射器)、心率监测器、温度传感器(例如,外部温度传感器、皮肤温度传感器)、被配置成检测与用户周围的环境相关联的参数(例如,温度、湿度、亮度)的环境传感器、电容式触摸传感器、gsr传感器、视觉传感器(例如,能够检测可见光、红外光或紫外线的成像装置、相机)、热成像传感器、位置传感器、距离接近度传感器(例如,超声传感器、光检测和测距(lidar)、飞行时间或深度相机)、高度传感器、姿态传感器(例如,罗盘)、压力传感器(例如,气压计)、湿度传感器、振动传感器、音频传感器(例如,麦克风)、场传感器(例如,磁力计、电磁传感器、无线电传感器)、hrv监测器中使用的传感器(例如,心电图(ecg)传感器、心冲击描记图传感器、光电血管容积图(ppg)传感器)、血压传感器、液体检测器、wi-fi、蓝牙、蜂窝网络信号强度检测器、环境光传感器、紫外线(uv)传感器、氧饱和度传感器或其组合或如本文中其它地方所描述的任何其它传感器或感测装置。传感器可以定位于可佩戴装置、移动装置或医疗装置中的一个或多个上。在一些情况下,传感器可以被放置在用户的身体内。
装置110还可以包含可以与平台150通信的任何计算装置。计算装置的非限制性实例可以包含移动装置、智能电话/手机、平板电脑、个人数字助理(pda)、膝上型计算机或笔记本计算机、台式计算机、媒体内容播放器、电视机、视频游戏站/系统、虚拟现实系统、增强现实系统、麦克风或能够分析、接收、提供或显示各种类型的健康、营养或食物数据的任何电子装置。装置可以是手持物体。装置可以是便携式的。装置可以由人类用户携带。在一些情况下,装置可以远离人类用户定位,并且用户可以使用无线和/或有线通信来控制装置。
平台150可以与互联网120和一个或多个数据库130(例如,其它食物、营养或医疗保健提供者)通信。例如,平台可以与含有电子医疗记录(emr)的医疗保健数据库通信。在一些实施例中,一个或多个数据库130可以包含以非结构化数据库或格式存储的数据,如海杜普(hadoop)分布式文件系统(hdfs)。hdfs数据存储可以为非结构化数据提供存储。hdfs是提供可扩展且可靠的数据存储并且可以被设计成跨越大型商用服务器集群的基于java的文件系统。hdfs数据存储区对于并行处理算法(如映射归约(mapreduce))可能是有益的。
平台150还可以与一个或多个另外的数据库240通信以存储由平台150收集或生成的任何数据或信息。一个或多个另外的数据库240可以是安全云数据库的集合。来自多个不同来源的数据可以包括不同类型或形式的数据(结构化数据和/或非结构化数据)。在一些情况下,数据可以包含由一个或多个装置110、传感器或监测系统收集的时间序列数据。时间序列数据可以包含定期的传感器读数或其它数据。平台可以任何数量或类型的装置(范围为数十个、数百个、数千个、数十万个或数百万个装置)接收数据。平台150可以通过将不同类型或形式的数据转换成标准化结构化格式,以不知其来源的方式连续处理不同类型或形式的数据中的每种类型或形式的数据。采用标准化结构化格式的经转换的数据可以与健康和营养平台兼容。如本文中其它地方所描述的,平台150可以与健康和营养平台集成或作为其一部分提供。在一些实施例中,平台150可以与健康和营养平台分开提供。
平台150可以包含可以从彼此和在彼此之间传递流式传输数据的组件(或模块)组。在一些实施例中,可以使用
人工智能属于计算机科学的领域,其强调创建像人类一样工作和作出反应的智能机器。具有人工智能的活动计算机中的一些活动计算机是为包含学习而设计的。人工智能算法的实例包含但不限于关键学习、演员-评论家方法(actorcriticmethod)、强化、深度确定性策略梯度(ddpg)、多智能体深度确定性策略梯度(maddpg)等。机器学习是指针对人类知识的技术发展而改变的人工智能学科。
机器学习通过暴露于新场景、测试和适应来促进计算的不断进步,同时采用模式和趋势检测来改进决策和随后的(尽管不完全相同)情形。机器学习(ml)算法和统计模型可以由计算机系统使用以在无需使用明确指令、而是依靠模式和推理的情况下有效地执行特定任务。机器学习算法基于样本数据(被称为“训练数据”)建立数学模型,以便在无需明确地被编程为执行任务的情况下进行预测或决策。当开发用于执行任务的特定指令的算法不可行时,可以使用机器学习算法。
例如,监督学习算法建立含有输入和期望的输出两者的一组数据的数学模型。所述数据被称为训练数据并且由一组训练实例组成。每个训练实例具有一个或多个输入和期望的输出(也被称为监督信号)。在半监督学习算法的情况下,训练实例中的一些训练实例缺少期望的输出。在数学模型中,每个训练实例由阵列或向量表示,并且训练数据由矩阵表示。通过目标函数的迭代优化,监督学习算法学习了可以用于预测与新输入相关联的输出的函数。优化函数将允许算法正确地确定不是训练数据的一部分的输入的输出。据说随时间提高其输出或预测的准确性的算法已经学会了执行所述任务。监督学习算法包含分类和回归。分类算法在输出被限制为一组有限值时使用,并且回归算法在输出可能具有在范围内的任何数值时使用。相似性学习属于与回归和分类密切相关的监督机器学习的领域,但是目标是使用测量两个对象的相似或相关程度的相似性函数来向实例学习。
强化学习属于机器学习的领域,其与软件智能体应当如何在环境中采取行动以最大化累积奖励的一些概念有关。由于其通用性,所述领域在许多其它学科中进行了研究,如博弈论、控制论、运筹学、信息论、基于仿真的优化、多智能体系统、群体智能、统计和基因算法。在机器学习中,环境通常表示为马尔可夫决策过程(mdp)。许多强化学习算法使用动态编程技术。强化学习算法不假设mdp的精确数学模型为常识,并且在精确模型不可行时使用。
在预测建模和其它类型的数据分析中,基于一个数据样本的单个模型可能会具有可能会影响其分析发现的可靠性的偏差、高可变性或完全不准确性。通过组合不同模型或分析多个样本,可以减少这些限制的影响以提供更好的信息。如此,集成方法可以使用多种机器学习算法来获得相较于仅从任何组成型学习算法获得的更好的预测性能。
集成是一种监督学习算法,因为可以对其进行训练并且然后将其用于进行预测。因此,经过训练的集成表示单个假设,所述单个假设不一定含有在根据所述单个假设建立的模型的假设空间内。因此,集成可以示出在其可以表示的函数中具有更大的灵活性。集成模型可以包含其预测合并的一组经过单独训练的分类器(如神经网络或决策树)。
例如,集成建模的一个常见实例是随机森林模型,所述随机森林模式是一种利用多个决策树的分析模型并且旨在基于不同的变量和规则来预测结果。随机森林模型将可以分析不同的样本数据、评估不同的因素或有区别地对共同变量进行加权的决策树融合。然后,将各个决策树的结果转换成简单的平均值或通过进一步的加权进行聚合。hadoop和其它大数据工艺的出现允许存储和分析更大的数据量,这允许在不同的数据样本上运行分析模型。
取决于实施方案,可以将任何数量的机器学习模型组合以优化集成模型。可以在机器学习模型处实施的机器学习算法或模型的实例可以包含但不限于:回归模型,如线性回归、逻辑回归和k均值聚类;一个或多个决策树模型(例如,随机森林模型);一个或多个支持向量机;一个或多个人工神经网络;一个或多个深度学习网络(例如,至少一个递归神经网络、使用深度学习的序列到序列映射、使用深度学习的序列编码等);基于模糊逻辑的模型;基因编程模型;贝叶斯网络(bayesiannetwork)或其它贝叶斯技术;概率机器学习模型;高斯处理模型(gaussianprocessingmodel);隐马尔可夫模型(hiddenmarkovmodel);时间序列方法,如自回归移动平均(arma)模型、自回归积分移动平均(arima)模型、自回归条件异方差(arch)模型;广义自回归条件异方差(garch)模型;移动平均(ma)模型或其它模型;以及上述中的任何一种的启发式推导的组合等。机器学习算法的类型的差别在于其方法、其输入和输出的数据的类型以及其打算解决的任务或问题的类型。
隐马尔可夫模型(hmm)是统计马尔可夫模型,在所述统计马尔可夫模型中,被建模的系统被假设为具有未观察到的(隐藏)状态的马尔可夫过程。hmm可以被视为最简单的动态贝叶斯网络。贝叶斯网络、信念网络或有向非循环图模型是一种概率图形模型,其表示一组随机变量以及所述一组随机变量与有向非循环图(dag)的条件独立性。建模变量序列的贝叶斯网络被称为动态贝叶斯网络。可以表示和解决不确定性下的决策问题的贝叶斯网络的泛化被称为影响图。
支持向量机(svm)(也被称为支持向量网络)是用于进行分类和回归的一组相关监督学习方法。给定一组训练实例,每个训练实例标记为属于两个类别之一,svm训练算法将建立预测新实例是否属于一个类别或另一个类别的模型。svm训练算法是一种非概率的二进制线性分类器。除了执行线性分类外,svm还可以使用所谓的核技巧高效地执行非线性分类,从而隐式地将其输入映射到高维特征空间中。
决策树学习使用决策树作为预测模型以从对项(在分支中表示)的观察行进到对项的目标值(在叶子中表示)的结论。其中目标变量可以采用一组离散值的树模型被称为分类树;在这些树形结构中,叶子表示类标签并且分支表示导致所述类标签的特征的结合。其中目标变量可以采用连续值(通常是实数)的决策树被称为回归树。在决策分析中,决策树可以用于可视化地和显式地表示决策和决策的做出。
深度学习算法可以是指机器学习中使用的算法的集合,所述算法用于通过使用由多个非线性变换构成的模型架构来对高级抽象和数据进行建模。深度学习是一种用于建立和训练神经网络的特定方法。深度学习由人工神经网络中的多个隐藏层组成。深度学习算法的实例可以包含例如孪生网络(siamesenetwork)、转移学习、递归神经网络(rnn)、长短期记忆(lstm)网络、卷积神经网络(cnn)、变换器等。例如,深度学习方法可以利用自回归递归神经网络(rnn),如长短期记忆(lstm)和门控递归单元(gru)。一种使用rnn(和变体)进行时间序列预测的神经网络架构是自回归seq2seq神经网络架构,其充当自动编码器。
在一些实施例中,集成模型可以包含一种或多种深度学习算法。应当注意,也可以使用任何数量的不同的机器学习技术。取决于实施方案,集成模型可以被实施为自举聚合集成算法(也被称为装袋分类器方法)、增强集成算法或分类器算法、堆叠集成算法或分类器算法、模型存储桶集成算法、贝叶斯优化分类器算法、贝叶斯参数平均算法、贝叶斯模型组合算法等。
自举聚合(通常被称为装袋)涉及使集成投票中的每个模型具有相等权重。为了提高模型方差,装袋使用训练集的随机绘制子集训练集成中的每个模型。作为实例,随机森林算法将随机决策树与装袋组合以实现非常高的分类准确性。装袋分类器或集成方法通过在训练集的随机再分布上训练每个分类器来为其集成创建个体。每个分类器的训练集可以通过随机绘制(在放回的条件下)n个实例(其中n是原始训练集的大小)来生成;许多原始实例可能会在所产生的训练集中重复,而其它实例可能会被排除在外。集成中的每个单独的分类器是在对训练集进行不同的随机采样的情况下生成的。装袋对其中训练集的小改变会导致预测的大改变的“不稳定的”学习算法(例如,神经网络和决策树)有效。
相比之下,增强涉及通过训练每个新模型实例以强调先前模型错误分类的训练实例来递增地建立集成。在一些情况下,增强已经示出产生相比于装袋更好的准确性,但是其也倾向于更有可能过度拟合训练数据。增强分类器可以是指可以用于产生一系列分类器的一系列方法。用于系列的每个成员的训练集基于系列中的一个或多个较早分类器的性能来挑选。在增强中,与正确地预测的实例相比,更多地挑选由系列中的先前分类器不正确地预测的实例。因此,增强尝试产生能够更好地预测当前集成的性能较差的实例的新分类器。尽管据报道一些较新的算法会实现更好的结果,但是增强的常见实施方案是adaboost。
堆叠(有时称为堆叠泛化)涉及对学习算法进行训练以将几种其它学习算法的预测组合。堆叠工作分两个阶段进行:使用多个基础分类器对类进行预测,并且然后以减少泛化误差为目标使用新的学习器将其预测组合。首先,使用可用数据对所有其它算法进行训练,然后对组合器算法进行训练以使用其它算法的所有预测作为另外的输入进行最终预测。如果使用任意组合器算法,则在理论上,堆叠可以表示本文中所描述的集成技术中的任何集成技术,尽管在实践中,逻辑回归模型通常用作组合器。
“模型存储桶”是一种在其中使用模型选择算法为每个问题选择最佳模型的集成技术。当在仅一个问题的情况下进行测试时,模型存储桶可以产生的结果不会比集中的最佳模型产生的结果更好,但是当跨许多问题进行评估时,平均而言,其产生的结果通常会比集合中的任何模型产生的结果更好。用于模型选择的一种常见方法是交叉验证选择(有时被称为“烘烤竞赛(bake-offcontest)”)。交叉验证选择可以被总结为在训练集中尝试所有模型并且然后挑选最有效的模型。门控是交叉验证选择的泛化。其涉及训练另一种学习模型以决定最适于解决问题的存储桶中的模型中的哪些模型。通常,感知器用于门控模型。其可以用于挑选“最佳”模型,或者其可以用于向来自存储桶中的每个模型的预测给予线性权重。当使用模型存储桶有很多问题时,避免训练一些花费很长时间进行训练的模型可能是令人期望的。特征点学习是一种力图解决这种问题的元学习方法。其涉及仅训练存储桶中的快速(但不精确)算法,并且然后使用这些算法的性能来帮助确定哪种慢速(但准确)算法最有可能做得最好。
贝叶斯优化分类器是一种分类技术。其是假设空间中的所有假设的集成。平均而言,其它任何集成都无法胜过所述贝叶斯优化分类器。朴素贝叶斯优化分类器是这种贝叶斯优化分类器的一个版本,其假设数据在条件上不依赖于类并且使计算更加可行。如果所述假设为真,则对每个假设进行投票,所述投票与将会从系统中采样训练数据集的可能性成比例。为了促进训练有限大小的数据,每个假设的投票也乘以所述假设的先验概率。然而,由贝叶斯优选分类器表示的假设是集成空间(所有可能的集成的空间)中的优化假设。
贝叶斯参数平均(bpa)是一种寻求通过从假设空间中采样假设并使用贝叶斯定律组合所述假设来近似贝叶斯优化分类器的集成技术。与贝叶斯优化分类器不同,贝叶斯模型平均(bma)可以实际地实施。假设通常使用蒙特卡洛采样技术(montecarlosamplingtechnique,如mcmc)进行采样。例如,吉布斯采样(gibbssampling)可以用于得出表示分布的假设。已经示出,在某些情况下,当以这种方式得出假设并根据贝叶斯定律求平均时,这种技术的预期误差必然为贝叶斯优化分类器的预期误差的至多两倍。
贝叶斯模型组合(bmc)是对贝叶斯模型平均(bma)的算法校正。其不是单独地对集成中的每个模型进行采样,而是从可能的集成的空间中采样(其中模型权重从具有均匀参数的狄利克雷分布(dirichletdistribution)中随机得出)。这种修改克服了bma向将所有权重给予单个模型汇集的倾向。尽管从计算方面上将,bmc比bma稍微昂贵,但其倾向于产生显著更好的结果。已经示出,来自bmc的结果平均而言(具有统计显著性)比bma和装袋更好。使用贝叶斯定律来计算模型权重需要计算给予每个模型的数据的概率。通常,集成中的所有模型都不精确地是从中生成训练数据的分布,因此所有模型都正确地接收到这个项的接近于零的值。如果集成足够大以对整个模型空间进行采样,则这将会有效,但是此种情况几乎不可能。因此,训练数据中的每个模式将会使集成权重朝最接近于训练数据的分布的集成中的模型移位。它在本质上减少了用于进行模型选择的不必要的复杂方法。集成的可能的权重可以可视化为取决于单纯形。在单纯形的每个顶点处,所有权重被给予集成中的单个模型。bma向最接近于训练数据的分布的顶点汇集。相比之下,bmc向其中这种分布投影到单纯形上的点汇集。换句话说,其不是选择最接近于生成分布的一种模型,而是寻找最接近于生成分布的模型的组合。来自bma的结果通常可以通过使用交叉验证从模型存储桶中选择最佳模型来估算。同样,来自bmc的结果可以通过使用交叉验证从可能的权重的随机采样中选择最佳集成组合来估算。
再次参考图1,基于对标准化结构化数据的分析,平台150可以进一步为多个个人用户中的每个个人用户生成个性化的饮食和健康建议或推荐。
数据可以通过使用api网关连接到平台来进入平台150。因此,可以通过经由api网关连接到平台的多个应用编程接口(api)从多个不同来源收集和聚合数据。可以使用自主函数将数据聚合、处理和存储在平台中,所述自主函数在传入数据通过平台内的不同模块或组件进行流式传输时会被触发。平台内的组件/模块可以彼此解耦,由此确保易于维护、更新和可复用性。平台对数据的处理不受底层api的改变或更新的影响。在平台中使用无服务器架构可以允许在对底层api进行改变或更新时数据不会丢失的情况下处理数据。
平台150可以被配置成实时地或接近实时地处理大量流式传输数据。在一些实施例中,平台可以从多个不同来源收集、聚合和处理数据。数据可以包括在一天中均匀或不均匀分布的至少近似106个每日数据点。数据中的一些数据可以在数毫秒左右从api网关检索到。在一些情况下,平台150可以接收不能实时处理的批量数据。平台可以以如parquet等的文件格式输出数据,所述文件格式被配置成允许分析大数据量。
图2示出了根据一些实施例的平台150的框图。平台可以包含令牌模块210、检索模块230、流水线模块250、标准化模块270和存储模块290。模块可以表示可以认证、引导、存储或处理数据的函数、存储单元或应用的分组。数据可以串行地流过所述模块,但是每个组件内提供的自主函数可以以串行或并行方式排列。连接到平台的api可以使用令牌模块210进行认证和授权。检索模块230可以被配置成从所连接的应用检索数据。流水线模块250可以被配置成将数据引导到托管应用和第三方应用以进行进一步的处理或存储。标准化模块270可以处理数据并将数据转换成标准化结构化格式。标准化结构化数据可以在平台内进行进一步分析,例如使用本文中所描述的一种或多种机器学习模型。可替代地,可以将标准化结构化数据导出到一个或多个第三方应用进行分析。最后,存储模块290可以存储经处理的数据、监测被动数据收集并准备要用于进行不同类型的分析的数据。
令牌模块210可以集成外部api和数据服务,并且负责授权和认证这些外部api。当认证第三方应用时,令牌模块210可以或可以不将自身表示为令牌模块。例如,当与外部api和数据服务通信时,令牌模块210可以将其自身表示为平台150,或者表示为从第三方应用收集数据的不同服务。这可以允许令牌模块210在保持其身份不变的同时通过第三方应用来使服务匿名化。因此,令牌模块可以用于管理对由不同实体(例如,公司)提供的一个或多个第三方应用的访问。
令牌模块210可以创建、更新和删除令牌。令牌模块可以刷新现有令牌并且提供关于令牌改变的通知更新。由令牌模块210创建的令牌可以被复制并传递到检索模块,所述检索模块与令牌模块解耦并且独立于所述令牌模块。每当新令牌生成时,除存储在所述令牌模块中之外,所述新令牌也可以在所述检索模块中单独地复制。所创建的令牌可以具有到期日期。为了维护许可,令牌模块210可以在调度的基础上向检索模块230发行令牌。在一些实施例中,当检索模块230没有必要的令牌时或者如果令牌不能正常工作时,所述检索模块可以使用简单通知服务将消息发送到令牌模块210。
令牌模块210可以使用oauth来集成外部api。用户可以使用平台150登录到应用中。使用平台的api,应用可以请求启动用户与一个或多个另外的第三方应用之间的认证过程。当用户通过一个或多个第三方应用进行认证时,使用平台的应用会接收到访问令牌,所述访问令牌存储在平台150上。认证过程可以使用oauth1.0或oauth2.0。
检索模块230可以从连接到平台150的api检索数据。检索模块230可以充当平台的集线器以与许多类型的应用、可佩戴装置、移动装置、医疗装置、数据集、数据来源等集成。检索模块可以与各种装置交互并接收数据。数据可以以对应的应用通常导出的形式接收。检索模块230可以包括可以将来自许多不同应用的数据合并到流中的一组处理函数。数据可以以异步方式合并,并在流中保存固定的时间段。在接收到数据并将其合并到流中后,可以将其作为数据包引导到其它模块进行处理。检索模块可以与其它模块解耦并且独立于所述其它模块。例如,检索模块可以仅被配置成收集和聚合数据,并且可以没有被配置成保存、存储或处理数据。
检索模块230可以被配置成提取数据并接收推送的数据。数据可以直接从所连接的api收集,或者也可以从移动装置接收。在这些实施例中,来自移动装置应用的数据可以存储在存储桶对象(如
检索模块230还可以从将数据推送到平台中的应用检索数据。可以将数据推送到平台中的服务和装置的实例可以包含abbottfreestylelibre、garmin、fitbit等。这些装置可以将通知发送到平台150,所述通知可以由检索模块230接收。作为响应,检索模块230可以从这些应用提取数据并将数据合并/存储到一个流或多个流中。在一些情况下,数据可以与通知同时发送到平台,从而消除了检索模块230作为响应而提取数据的需要。在一些实施例中,检索模块230还可以存储由令牌模块210创建的令牌。令牌可以存储在与检索模块一起提供的无服务器数据库中。
流水线模块250可以控制数据通过平台150的流动。流水线模块250可以促进到第三方应用的数据传递,实例可以包含welltok、美敦力公司等。流水线模块250还可以将数据传递到平台内的流式传输应用。可以使用响应于事件而触发的自主函数来传递数据。事件可以包含创建对象和接收通知消息(如sns消息)。在一些实施例中,流水线模块250可以使用
标准化模块270可以通过创建可以由第三方应用读取或对标准化数据文件进行分析的标准化的、合并的结构化数据文件来管理和处理通过平台150流式传输的数据。标准化模块270可以包含可以在数据流上实施不同处理函数的一组元素。处理函数可以包含分选、将数据转换成不同的格式以及移除冗余数据。可以将经处理的数据流存储、缓存或引导到另外的数据流中。
存储模块290可以管理平台的被动数据收集活动。数据收集活动的管理可以包含保持由被动数据收集sdk提取的流式传输的数据的日志,以及分析、分类和存储流式传输的数据。存储模块290可以对从所连接的应用或移动装置上的本地应用提取的数据自动执行分析。移动装置相机可以被动地收集图像数据,所述图像数据可以由被动数据收集软件开发工具包(sdk)推送到存储模块290。存储模块290可以使用利用神经网络建立的二进制分类器将图像分类为含有食物项或不含食物项。可以在分析之前对这些数据进行预处理或加密。
在随后的附图描述中,平台150内的每个模块可以被描述为包含一个或多个组件。这些组件可以各自包含在逻辑上连接并且被配置为一组来执行任务的一个或多个自主函数、数据流、流式传输应用、存储桶或其它组件的分组。通过平台150流式传输的数据可以触发这些分组内的一个或多个自主函数。例如,可以使用amazon(r)kinesis数据流或
图3示出了根据一些实施例的令牌模块210的组件。令牌模块210可以包含认证和令牌创建组件330、令牌刷新组件360和令牌存储组件390。
认证和令牌创建组件330可以与外部api通信。认证和令牌创建组件可以在url处接收连接请求并存储请求。令牌可以是用户访问令牌。令牌可以包含到期日期、许可和标识符。在一些实施例中,请求可以存储在表中。认证和令牌创建组件还可以维护授权url。在授权用户后,回调函数可以使用户返回到授权url。当外部api被认证和授权时,授权和令牌创建组件可以发行令牌,所述令牌存储在令牌模块210中。令牌也可以存储在表中。授权和令牌创建组件还可以复制令牌并将副本令牌传递到接收模块230。如令牌的到期日期等的令牌信息可以与令牌一起拷贝到接收模块230中。当令牌到期时,也可以使用组件330将其删除。
令牌刷新组件360可以是定期运行、检查现有令牌的到期日期并刷新即将到期的令牌的调度组件。令牌刷新组件360可以向订阅者更新令牌。通知可以提供关于令牌状态改变的更新。令牌刷新组件可以例如使用简单通知服务来更新组件。令牌存储组件390可以将令牌的记录保持在平台中。当令牌创建或刷新时,可以将其存储在令牌存储组件390中。
图4示出了根据一些实施例的接收模块230的组件。接收模块230可以包含令牌存储组件420、数据推送组件450、数据提取组件480和数据合并组件490。
令牌存储组件420可以存储由令牌模块210创建的令牌。令牌存储组件还可以从令牌模块210检索刷新的令牌。当令牌模块210授权api时,其可以将消息发送到检索器模块以创建新令牌。消息可以含有令牌信息。所创建的令牌可以存储在表中。重新发行的令牌也可以存储在表中。令牌存储组件420可以从令牌模块210接收通知以更新已经存储的令牌。例如,令牌存储组件420可以从令牌模块420接收命令以更新令牌的时间区字段。令牌存储组件420可以接收用新令牌替换现有的即将到期的令牌的通知。
数据推送组件450可以允许外部api将数据推送到接收模块230中。外部api可以用api网关与接收模块230通信。数据推送组件450可以订阅来自外部api的通知。当数据可用时,可以提示数据推送组件450检索正在由外部api推送的数据。这个数据可以本地存储。接收模块230可以将原始响应数据存储在一个或多个对象(如一个或多个存储桶)中。
数据提取组件480可以从外部api提取数据。可以在调度的基础上从具有存储在检索模块480上的有效令牌的api提取数据。数据提取组件480可以不提供所有可用数据用于进行流式传输。而是,数据提取组件480可以将这些数据的部分子集提交给数据合并组件490。
数据合并组件490可以将(a)来自数据推送组件450的推送数据和(b)从数据提取组件480提取的数据放置到数据流中。如本文中所使用的,术语“合并”可以包含将从第三方应用接收的数据移动到一个或多个数据流中。可以提示数据合并组件通过来自数据推送组件450、数据提取组件480或两者的推送通知将数据移动到流中。数据合并组件490可以含有自主函数以从api检索历史数据(例如,从前一个月收集的数据)。例如,当新用户注册到平台中时,历史数据函数仅可以被调用一次。来自一个或多个数据流的一些数据可以本地保存。数据合并组件490可以将数据流中的一个或多个数据流提供给平台内的其它所连接的模块。
图5示出了根据一些实施例的流水线模块250的组件。流水线模块250可以包含用于将数据从数据流发送到应用540的组件以及用于在平台570内发送数据的组件。流水线可以利用流水线设计模式,并且可以包含串联连接的元件组。示例性元件可以包含用于传递流式传输的数据的λ函数。在流式传输的数据上操作的λ函数可能会取决于哪个或哪几个外部api正在提供数据、处理速率和/或平台内的其它条件而有所不同。在平台的两个或更多个组件需要处理相同数据的情况下,可以复制正在从流传递的数据。
图6示出了根据一些实施例的标准化模块270的组件。标准化模块270可以包含原始数据存储模块620、数据分选模块640、日记650、数据缩减模块660、监测模块680和转换模块690。在其它实施例中,标准化模块270可以包含不同的或另外的数据处理组件。组件可以串行排列,使得在准备通过存储模块290进行数据分析或存储期间,可以由多个组件连续地对流进行分阶段处理。当数据被更新并呈现给接收模块210时,可以在标准化模块270中的流中反映更新。
原始数据存储模块620可以存储从第三方应用收集的数据。所存储的数据可以是尚未经历由平台组件进行的处理的“原始”数据。此类数据可以被动地从如苹果健康工具包(applehealthkit)等的移动装置上的应用收集。原始数据可以直接存储到原始存储模块620中,并且可以绕过令牌模块210和检索器230。
数据分选模块640可以对从流水线模块250接收的数据进行分选。可以按用户id、数据类型或活动时间戳对数据进行分选。分选可以由函数调用并且可以使用在平台上的流式传输的应用来执行。分选的数据可以被缓存以便快速访问。可以将分选的数据放置在流(如
日记650可以存储标准化的、经处理的数据以供第三方应用或供最终用户使用。日记可以存储手动记录数据和导出数据。手动记录数据可以包含餐食、锻炼、自我报告的感觉、睡眠持续时间和自我报告的质量、身高、体重、用药和胰岛素水平。导出数据可以根据记录数据计算出,并且可以包含如体脂百分比和基础代谢率(bmr)等的度量。从所连接的应用被动收集到的数据可以与这些数据合并,并且可以包含来自应用和可佩戴装置(如fitbit、apple手表、oura环和runkeeper)的同步健康信息。单个日记条目可以包含转换成标准化结构化格式的这些合并的、经过处理的数据。条目可以一次添加或批量添加。日记条目可以被缓存以便快速访问。日记条目可以由平台使用以创建向用户提供汇总信息和推荐的报告。例如,日记条目可以产生含有汇总的葡萄糖信息、餐食统计和改善进食习惯的提示以及血糖与身体活动、睡眠和情绪之间的相关性的报告。
数据缩减模块660可以从数据流中移除冗余或无关的条目。数据缩减模块660可以使用映射-归约算法以便移除冗余或无关的条目。例如,第三方应用myfitnesspal可以将营养物质与食物配对。对于每种营养物质,myfitnesspal可以列出食物内的每种营养物质。然而,由于同一食物项中可能含有许多营养物质,因此这可能会导致许多副本条目。数据缩减模块660可以通过创建“食物”键并列出食物的营养物质中的每种食物的营养物质作为值来合并这些条目,使得每种食物与其营养信息一起一次列出。
监测模块680可以确保标准化模块270的处理阶段正确地工作。为了做到这一点,监测模块680可以生成虚拟数据。虚拟数据可以被放置在流中,并且被引导到数据标准化模块内的处理模块中的一个或多个处理模块。由监测模块680产生的虚拟数据可以来自在处理中使用的一种或多种数据类型。监测模块可以根据测试虚拟数据来创建报告,并将所述报告提供给外部分析服务(如
转换模块690可以将流式传输数据转换成其它数据格式。数据转换成的文件格式可以取决于标准化模块270内的随后的处理阶段。例如,转换模块690可以将数据转换成foodprinttm数据格式。经转换的流式传输数据可以存储在缓存中以便快速访问,或传输到标准化模块270内的其它处理阶段。
图7示出了根据一些实施例的存储模块290的组件。存储模块290可以包含数据监测模块720、数据分类模块750和数据存储模块780。存储模块的组件可以对被动收集到的数据进行操作。被动数据可以从用户移动装置上的应用收集。
数据监测模块720可以包含一个或多个λ函数,其接收从平台内的不同组件报告的数据以便监测所述组件。数据可以由组件从外部装置收集。λ函数之一可以调用可以打印关于正在收集的数据的信息的应用。监测过程可以分析对被动收集到的数据执行的不同操作,包含获得数据、保存数据、打包数据、加密数据、上传数据以及将数据保存到一个或多个服务器。另外的λ函数可以将通过监测过程收集的信息保存在日志文件中,所述日志文件可以存储在url处。
数据分类模块750可以接收含有被动收集到的数据的加密文件。数据分类模块750可以含有一个或多个λ函数,其在可以对收集到的数据进行分类之前对这些文件进行预处理。预处理活动可以包含对文件进行解压缩和解密。数据分类模块可以使用λ函数对收集到的数据进行分类。分类可以涉及使用机器学习或深度学习技术(如卷积或递归神经网络)。例如,可以对用移动电话相机拍摄的图像执行图像识别分析以确定食物是否存在于那些图像中的任何位置处。可以将含有食物的图像存储在日记650中,在所述日记中,可以从这些图像中提取营养信息。分类完成后,可以将经分类的数据存储在调试桶中以便对分类器进行故障排除。数据分类模块750可以实施一种或多种安全策略以确保在数据被盗用或被窃取的情况下使数据匿名化。例如,图像中人脸可能会被模糊。如果要将数据上传到云,也可以对其进行加密。
数据存储模块780可以存储已经被分类的被动数据。存储的数据可以通过第三方应用进行分析,并且可以为用户提供分析(如地理位置、文件分辨率和相机模块数据)以改善数据分析模型。存储的被动数据可以包含图像数据以及记录信息。记录信息可以包含来自第三方应用的手动输入或自动记录的睡眠和活动信息。经分类的数据可以临时存储在数据存储模块290中,并且可以在固定的时间段之后被删除。
图8-12示出了平台150内的模块的示例实施例。示例实施例可以采用
λ函数可以是如使用
api网关可以将平台与外部api连接,以便将数据从外部应用传递到平台。api网关还是整个oauth过程的外部进入点以集成外部api和数据服务。平台还可以订阅通过api网关推送数据的api,并且因此在准备好推送数据时通过网关接收通知。api网关还可以允许外部api从平台本身接收数据。
应用api可以通过使用http调用来传递数据并与之交互。api可以遵循定义了一组与这些api进行交互的规则的rest。其可以通过发送请求消息将数据发布到资源、从资源获取数据、更新资源中的数据或将数据从资源中删除。这些消息可以包含带有消息、用户、凭证、时间戳和其它消息信息的文本字段。api网关可以使用http请求与应用通信。
web服务器可以存储如http资源等的资源,并且可以通过网络连接到平台。web服务器可以存储授权信息,并且可以向平台发行令牌,以便允许平台从外部api访问用户数据。web服务器还可以存储经处理的信息。在平台150上运行的应用可以访问存储在web服务器上的数据。流式传输应用可以托管在web服务器上。
流式传输应用可以由
图8示出了根据一些实施例的令牌模块210的实施例800。令牌模块可以包含将平台150连接到外部api的api网关810。λ函数连接822可以将来自外部api的连接请求保存在表中。外部api可以通过λ函数进行认证和授权。授权后,可以调用λ函数来创建令牌。在所展示的实施例中,被称为刷新的λ824可以发送消息以刷新令牌。另一个λ826可以在数据库中搜索现有令牌。可以向检索模块230发行令牌。也可以调用λ禁用828以禁用存储在检索模块上的一个或多个令牌。另一个λ可以用于进行创建、读取、更新和删除(crud)操作。
图9示出了检索模块230的实施例900。在图9的实例中,检索模块可以从令牌模块实施例800接收消息以更新、创建和禁用令牌。消息可以是简单通知服务(sns)消息910。可以在令牌数据表930中更新令牌。参考图9中的数据推送组件450,检索器可以连接到api网关,以便接收从所连接的外部api推送的数据。订阅者922λ可以将sns消息发送到指示将被推送到检索模块实施例900中的数据的通知924函数。参考图9中的数据提取组件480,函数已调度_轮询926可以轮询如令牌数据表930中所列出的所连接的外部api。sns消息获取数据928可以宣布新数据可用,并且可以使用λ函数获取_数据_sns929来检索推送和提取的数据。函数获取_历史_数据_sns927可以接收来自保留时间段中的较早时间点的数据并将其添加到数据流。存储桶检索器-数据940可以存储发送到检索器中的数据以进行调试或备份。
图10示出了流水线模块250的实施例1000。在这个实施例中,两个流式传输应用和两个λ函数可以被串行连接。来自检索器模块实施例900的数据可以发送到被称为数据_分布1052的流式传输应用。λ函数数据_分布1022可以将这个数据引导到标准化模块实施例1100。另一个流式传输应用第三_方_数据1054和对应的λ函数1024可以将流发送到第三方应用存储桶1042。
图11示出了标准化模块270的实施例1100。这个实施例可以包含串行处理链以及在串行处理链的各个阶段处的多个缓存和
图12示出了存储模块290的实施例1200。数据监测模块可以使用函数数据_收集1222监测来自系统组件的数据。可以由应用监测器_流1224监测流。另外的λ函数1226可以将来自监测过程的日志保存到es域。数据分类模块可以从“落选”1242收集数据,使用λ函数风暴1228对数据进行预处理,并且对食物图像进行分类。λ函数保存_图像1221可以将尚未分类为食物项的项放置到调试和图像调试存储桶中。可以由存储模块将被分类为食物的图像保存在食物_图像1244、日记1282和分析法存储桶1246中。
图13-18是展示了根据所公开的实施例的方法的示例的流程图。参考图13-18,所示出的每种方法的步骤不一定是限制性的。在不脱离所附权利要求的范围的情况下,可以添加、省略和/或同时执行步骤。每种方法可以包含任何数量的另外的或可替代的任务,并且所示出的任务无需按照所展示的顺序执行。每种方法可以结合到具有本文中未详细描述的另外的功能的更全面的程序或过程中。此外,只要预期的整体功能保持完整,所示出的任务中的一个或多个任务就可以从每种方法的实施例中省略。进一步地,每种方法是计算机实施的,因为结合每种方法执行的各个任务或步骤可以由软件、硬件、固件或其任何组合来执行。出于说明的目的,以下对每种方法的描述可能涉及上文结合图1所提到的元件。在某些实施例中,这个过程的一些或所有步骤和/或基本等同的步骤是通过执行存储在或包含在是或可能是非暂时性的处理器可读介质上的处理器可读指令来执行的。例如,在以下对图13-18的描述中,平台150的各个组件(例如,令牌模块210、检索模块230、流水线模块250、标准化模块270、存储模块290和其任何组件)可以被描述为执行各种动作、任务或步骤,但是应当理解,这是指这些实体的一个或多个处理系统执行指令以执行所述动作、任务或步骤。取决于实施方案,处理系统中的一些处理系统可以集中定位,或者分布在一起工作的多个服务器系统中。
图13是展示了根据所公开的实施例的使用无服务器架构实施的计算机实施的数据收集和处理方法1300的流程图,所述无服务器架构包含用于通过基于硬件的处理系统生成个性化的饮食和健康建议或推荐的健康和营养平台150。方法1300开始于1310,其中检索模块230将来自多个不同来源的数据收集和聚合在存储模块290中。数据可以包含不同类型或形式的数据(例如,包括特定于多个个人用户的食物、健康或营养数据的结构化数据和非结构化数据)。
在1320处,标准化模块270可以例如通过将不同类型或形式的数据转换成与健康和营养平台150兼容的标准化结构化格式,以不知其来源的方式连续处理不同类型或形式的数据中的每种类型或形式的数据。
在1330处,可以(至少部分地)使用来自健康和营养平台150的信息来分析已经转换成标准化结构化格式的数据。例如,可以使用一个或多个机器学习模型来分析标准化结构化数据,所述一个或多个机器学习模型包含但不限于一个或多个人工神经网络;一个或多个回归模型;一个或多个决策树模型;一个或多个支持向量机;一个或多个贝叶斯网络;一个或多个概率机器学习模型;一个或多个高斯处理模型;一个或多个隐马尔可夫模型;以及一个或多个深度学习网络。在1340处,可以为多个个人用户中的每个个人用户生成个性化的饮食和健康建议或推荐。
图14是展示了根据所公开的实施例的用于收集和聚合来自多个不同来源的数据的方法1310的流程图。方法1300开始于1410,其中可以从允许使用任务调度器以预定时间间隔提取数据的第一组来源提取数据。在1420处,可以接收与正在从第二组来源推送的数据相关联的一个或多个通知。在1430处,可以确定每个对应通知的数据是否已经与对应通知一起到达。当确定(在1430处)每个对应通知的数据尚未与对应通知一起到达时,则方法1310前进到1410,其中如果数据没有与对应通知一起到达,则提取与所述对应通知相关联的数据。当确定(在1430处)每个对应通知的数据尚未与对应通知一起到达时,方法1310前进到1440,其中可以接收从第二组来源推送的数据。来自多个推送请求的数据可以流式传输到集中式位置中。
图15是展示了根据所公开的实施例的用于将来自多个不同来源的数据收集和聚合在存储模块290中的方法1310的流程图。方法1310开始于1505,其中与一个或多个实体相关联的令牌模块210可以与与一个或多个不同实体相关联的多个应用编程接口(api)通信。令牌模块210可以刷新现有令牌并且提供关于令牌改变的通知更新。每当新令牌生成时,除存储在令牌模块210中之外,所述新令牌也在检索模块230处单独地复制。检索模块230与令牌模块210解耦并且独立于所述令牌模块。
在1510处,检索模块230可以通过与一个或多个不同实体相关联的多个api从多个不同来源收集和聚合特定于多个个人用户的不同类型或形式的数据(例如,包括食物、健康或营养数据的结构化数据和非结构化数据)。
在1515处,存储模块290可以验证和检查收集到的和聚合的数据,将副本数据从收集到的和聚合的数据中移除,合并所选择类型的收集到的和聚合的数据,缩减收集到的和聚合的数据,并且分批保存合并的数据。
图16是展示了根据所公开的实施例的用于存储从多个不同来源收集到的和聚合的数据并且对收集到的和聚合的数据进行处理的方法1600的流程图。方法1600开始于1610,其中检索模块230将从多个不同来源收集到的和聚合的数据以多个流的形式存储在存储模块290处。在一个实施例中,多个流中的每个流可以具有定义时间帧的保持策略,在所述时间帧中,数据存储在每个流中。在1620处,在出现不同条件时,可以通过对存储在多个流中的收集到的和聚合的数据执行λ函数来处理收集到的和聚合的数据。在1620的一个实施例中,仅在数据收集和存储在多个流中时才执行λ函数。例如,在1630处,在1630处对存储的数据执行λ函数以将每行数据引导和传递到来自多个流的相关流,并且在1640处,通过从多个流中的一个流级联到另一个流来使收集到的和聚合的数据沿数据流水线行进。
图17是展示了根据所公开的实施例的用于将从多个不同来源收集到的和聚合的数据存储在多个流中的方法1610的流程图。方法1610开始于1710,检索模块230将从多个不同来源收集到的和聚合的数据以多个流的形式存储在存储模块290处,其中多个流包括多个碎片,并且每个碎片包括(1)进入到队列中并且(2)在保持策略到期时退出队列的数据记录串。数据记录串可以包含特定于多个个人用户的食物消耗、健康或营养记录。在1720处,可以控制多个流中的碎片的数量以控制处理数据的速度。
图18是展示了根据所公开的实施例的用于分析图像以确定其营养成分的方法1800的流程图。存储的收集到的和聚合的数据中的一些可以包含使用一个或多个成像装置捕获的图像。在1810处,可以对存储的数据的所述一部分执行一个或多个所选择λ函数以检测多个图像中的任何图像是否包括要针对其营养成分进行分析的一个或多个食物图像。食物图像与时间戳和地理位置相关联,由此使得能够在1820处例如通过预测餐食的消耗时间或餐食的成分来对用户的食物摄入进行时间和空间跟踪。
尽管机器可读存储介质可以是单个介质,但是术语“计算机可读存储介质”等应被视为包含存储所述一或多个指令集的单个介质或多个介质(例如,集中式或分布式数据库和/或相关联的缓存和服务器)。术语“计算机可读存储介质”等还应被视为包含能够存储、编码或携带由机器执行且使机器执行本发明的方法中的任何一种或多种方法的一组指令的任何介质。因此,术语“计算机可读存储介质”等应被视为包含但不限于固态存储器、光学介质和磁性介质。
先前的描述阐述了许多具体细节(如特定系统、组件、方法等的实例),以便提供对本发明的若干实施例的良好理解。然而,对本领域技术人员显而易见的是,可以在没有这些具体细节的情况下实践本发明的至少一些实施例。在其它情况下,未详细描述或以简单的框图格式呈现了众所周知的组件或方法,以便避免不必要地模糊本发明。因此,所阐述的具体细节仅是示例性的。特定实施方案可以与这些示例性细节不同,并且仍然被设想为在本发明的范围内。
在以上描述中,阐述了许多细节。然而,对于受益于本公开的本领域普通技术人员而言将显而易见的是,本发明的实施例可以在没有这些具体细节的情况下实践。在一些情况下,以框图形式示出了众所周知的结构和装置,以便避免模糊描述。
在对计算机存储器内的数据位进行的操作的算法和符号表示方面呈现了详细描述的一些部分。这些算法描述和表示是数据处理领域中的技术人员所使用的方法,以最有效地向所述领域的其它技术人员转达他们的工作实质。算法在此处并且通常被认为是产生期望的结果的步骤的自相一致序列。所述步骤是需要对物理量的物理操纵的步骤。通常但不一定,这些量采用能够被存储、转移、组合、比较和以其它方式操纵的电或磁信号的形式。已经证明,主要出于通用的原因,有时将这些信号称为位、值、元素、符号、字符、术语、数字等是便利的。
然而,应当记住,这些术语和类似术语中的所有这些术语和类似术语应与适当的物理量相关联,并且仅仅是应用于这些量的方便标记。除非另外特别说明,否则如根据以上讨论而显而易见的,应理解,贯穿本说明书,利用如“确定”、“标识”、“添加”、“选择”等术语进行的讨论是指计算机系统或类似电子计算装置的动作和过程,所述动作和过程将被表示为计算机系统的寄存器和存储器内的物理(例如,电子)量的数据操纵和变换成被类似地表示为计算机系统存储器或寄存器或其它此类信息存储、传输或显示装置内的物理量的其它数据。
本发明的实施例还涉及用于执行本文中的操作的设备。这种设备可以被专门构造用于所需目的,或者其可以包括通过计算机中存储的计算机程序选择性地激活或重新配置的通用计算机。此类计算机程序可以存储在计算机可读存储介质中。所述计算机可读存储介质如但不限于任何类型的盘(包含软盘、光盘、cd-rom和磁光盘)、只读存储器(rom)、随机存取存储器(ram)、eprom、eeprom、磁卡或光卡或者适于存储电子指令的任何类型的介质。
本文所呈现的算法和显示并非固有地与任何特定的计算机或其它设备相关。根据本文的教导,各个系统可以与程序一起使用,或可以证明构造更专用的设备以执行所需的方法步骤是方便的。用于各种这些系统的所需结构将从本文中所提供的描述中显现。另外,本发明不参考任何特定编程语言进行描述。应理解,可以使用各种编程语言来实施如本文描述的本发明的教导。
虽然前述具体实施方式中已经呈现了至少一个示例性实施例,但是应当理解,存在大量变化。还应当理解,本文中描述的一个或多个示例性实施例并非旨在以任何方式限制所要求保护的主题的范围、适用性或配置。更准确地说,前述具体实施方式将向本领域的技术人员提供用于实施所描述的一个或多个实施例的方便的指南。应当理解,在不脱离由权利要求书限定的范围的情况下,可以对元件的功能和布置作出各种改变,所述改变包含在提交本专利申请时已知的等效物或可预见的等效物。
- 还没有人留言评论。精彩留言会获得点赞!