一种适合毕赤酵母高表达的基因序列优化方法与流程
[0001]
本发明涉及生物信息处理技术领域,具体而言,涉及一种适合毕赤酵母高表达的基因序列优化方法。
背景技术:
[0002]
作为单细胞真核生物的毕赤酵母(pichia pastoris)表达系统由于其兼具真核生物和原核生物的特点,现在成为最重要的外源蛋白表达系统之一。由于不同的宿主对同义密码子(编码同一氨基酸的密码子)的使用具有偏好性,外源蛋白编码序列中存在的稀有密码子影响翻译速度进而阻碍了其在宿主细胞中的表达。毕赤酵母也不例外,毕赤酵母对同义密码子的使用也具有很强的偏好性。为了提高外源蛋白在毕赤酵母中的表达,需对编码序列进行优化,传统的做法是根据毕赤酵母密码子使用偏好性用最优密码子替换外源蛋白编码序列中的同义密码子。根据密码子使用偏好性进行基因序列优化并不一定能得到想要的高表达,其原因是该方法只简单的考虑到了单个密码子的使用,并没有考虑到密码子上下文对其的影响。研究发现,密码子上下文影响翻译的速度和精确度(fabienne f. v. chevance1, soazig le guyon2, kelly t. hughes1, et al. the effects of codon context on in vivo translation speed. plos genetics 2014; 10(6): e1004392)。毕赤酵母密码子对其上下文序列有很强的偏好性,即密码子对偏好(kristof de schutter, yao-cheng lin, petra tiels, et al. genome sequence of the recombinant protein production host pichia pastoris. nature biotechnology 2009; 27(6): 561-569)。基于密码子对偏好进行基因序列优化,信息量很大,常规的人工方法很难得到最优的基因序列。
技术实现要素:
[0003]
本发明的目的在于提供一种适合毕赤酵母高表达的基因序列优化方法,所述方法以毕赤酵母密码子对偏好性为参数,应用动态规划算法进行序列优化,具体包括以下步骤:步骤1:将要表达的蛋白质序列读入后进行处理。
[0004]
步骤2:根据密码子先后组合权重,建立密码子转换矩阵。
[0005]
步骤3:定义图g,其中根据要表达的蛋白质序列含有的氨基酸数量n,图g分为n层,每一层对应序列中的每一个氨基酸,每一层的节点数由氨基酸所对应的密码子个数决定,即每一层的节点数是该氨基酸所对应的密码子个数,每一层与下一层构成全连接子图,即每一层的节点都有一条边连接到下一层的节点。
[0006]
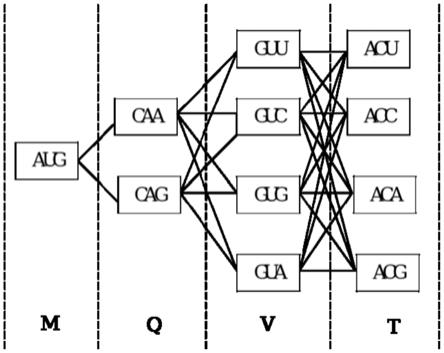
假设本层有两个节点,下一层有四个节点,那么就有2
×
4=8条边连接。如图1:苏氨酸(thr,用字母t表示),对应密码子有acu,acc,aca,acg四个,因此在t这一层,有4个节点。前一层为谷氨酰胺(gln,用字母q表示),对应密码子有两个,在q这一层有2个节点,两层之间有2
×
4=8条边连接。
[0007]
步骤4:设计最大权重数组max weight[i,j],其中数组元素下标i,j表示i层节点
通过当前层j节点到图g最后一层的最大权重。
[0008]
步骤5:从图g的倒数第二层开始向图g的第一层遍历,初始化当前层i层maxweight[i, j]为负值,并更新当前层的maxweight元素;步骤6:从图g的第一层向最后一层进行遍历,通过已经计算好的max weight,输出具有最大权值的密码子组合,即优化序列。
[0009]
本发明通过毕赤酵母密码子对偏好性对基因序列进行优化。本发明应用动态规划技术,将求解最优化序列问题的复杂度从o(k
l
)降到o(kl2),其中k为密码子与氨基酸对应的最大数量,l为蛋白质序列长度,充分解决了最优化序列候选路径呈指数增长的问题。
附图说明
[0010]
图1为氨基酸序列mqvt片段优化示意图;图2为节点关系示意图。
具体实施方式
[0011]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0012]
一种适合毕赤酵母高表达的基因序列优化方法,包括以下步骤:步骤1:读入要表达的蛋白质序列,其中蛋白序列用20个氨基酸简写字母表示,每一个字母,表示一种氨基酸,其字母缩写与从a到z的26个字母相对,其中b、j、o、u、x、z字母不对应氨基酸。以及氨基酸对应的密码子的列表。
[0013]
步骤2:根据密码子先后组合权重,建立密码子组合偏好性矩阵tran,该矩阵中左边行密码子代表序列中当前位置可能出现的氨基酸,右边列密码子代表当前位置的后一位可能出现的氨基酸。当组合权重值越高,代表该密码子对形成指定氨基酸组合的可能性越大。密码子对偏好数据来源于论文《kristof de schutter, yao-cheng lin, petra tiels, et al. genome sequence of the recombinant protein production host pichia pastoris. nature biotechnology 2009; 27(6): 561-569》。如图1,给定氨基酸序列mqvt片段,计算组合权重最大的密码子序列组合。如图1片段,相邻两条虚线中间的部分,表示一个层次,两个节点间的一条实线连接,表示一个可能的连接关系,通过权重表查询权重,若权重不等于0,连接关系存在,若权重等于0,则连接不存在。
[0014]
以节点aug-caa为例,计算权重的方法是,a表示0,c表示1,g表示2,u表示3,节点aug,通过计算0*16+3*4+2*4=20,将20作为密码子aug的编号。同理可以计算节点caa的编号,1*16+0*4+0*1=16。因为计算的结果区间是063,所以换算成矩阵的行数或列数需要加1,故而aug与caa之间连线的权重,就是caa的结果为行数,aug的结果为列数,即权重表中17列,21行,查表得值为1,说明这条连线可行,并且权重为1。
[0015]
步骤3:定义图g,其中根据要表达的蛋白质序列含有的氨基酸数量n,图g分为n层,每一层对应序列中的每一个氨基酸,每一层的节点数由氨基酸所对应的密码子个数决定,如图1:苏氨酸(thr,用字母t表示),对应密码子有acu,acc,aca,acg四个,因此在t这一层,有4个节点。
[0016]
步骤4:设计最大权重数组maxweight[i,j],其中数组元素maxweight[i,j]表示i层通过当前层j节点到图g最后一层的最大权重。如maxweight[1,2],表示第一层通过第2个
节点到末尾的最大权重之和。
[0017]
步骤5:从图g的倒数第二层(对应蛋白质序列倒数第二个氨基酸)开始向图g的第一层遍历,初始化当前层i层maxweight[i, j]为负值,并更新当前层的maxweight元素。
[0018]
步骤5.1:取当前层所有的节点(该层氨基酸对应的密码子)以及当前层的下一层的所有节点,计算当前层与下一层的全连接权重组合,即当前层某个密码子(密码子编号为j),到下一层某一个密码子(密码子编号为k)的密码子对偏好性tran[j,k]作为权重。
[0019]
步骤5.2:计算下一层最大权重max weight的对应节点j的密码子编号j与连接到节点k对应密码子编号k的连接权重tran[j,k]之和的最大权值,找到当前层的每一个节点j连接到最后一层的最大权值和连接路径,登记到当前层最大权重max weight。
[0020]
步骤6:从图g的第一层向最后一层进行遍历,通过已经计算好的max weight,输出具有最大权值的密码子组合序列,该序列为所求最优组合序列。由于在这里存在有多个最优组合,甚至随着层数的增加,最佳组合的数量会急剧增长,为了输出所有最佳路径,需要对算法进行修改,将每个节点设计为一个结构体,在这个结构体中,包含一个数组,用于所有最佳路径。
[0021]
步骤6.1:为图g的每一层构造一个二维数组p,设定第n层的数组为p[n,m],该层的数组元素数量与该层的节点数量一致。另外构造一个无意义的头结点p[0,0],将第1层中最大路径的节点,记录到p[0,0]的下一跳列表中。这样就可以实现从唯一的头结点开始,从第一层到最后一层节点的逐层访问输出。
[0022]
步骤6.2:由于结果组成的数据结构是一个有向的无环路的图(directed-acyclic graph , dag),采用先序遍历算法,根据二维数组p,实现dag的根节点到每一个叶子节点的每一条路径的输出,输出节点顺序如图2所示,通过访问,输出的全部路径为abce,abcf,abdf,abdg。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1