一种基于逆向强化学习算法在斗地主中的应用
1.本发明属于深度强化学习在游戏领域的应用,具体是涉及一种基于逆向强化学习在斗地主这种需要经验的游戏中的应用。
背景技术:
2.目前深度强化学习在许多游戏上都有应用,比如著名的atari游戏、星际争霸和dota等。而斗地主作为传统扑克游戏,具有自己的特色,拥有巨大的动作状态空间和多样化的出牌策略,是一个非常值得研究和解决的游戏。
3.当前对于斗地主的研究方法有很多,例如将贝叶斯算法和蒙特卡洛搜索树进行结合对斗地主进行处理,的确取得了不错的效果。还有对牌型进行分解的方法,将自己的手牌先分解为最合理的出牌组合以及最合理的出牌动作,符合人类玩家在玩斗地主时的思维。以及简单有效的蒙特卡洛方法,也在斗地主上取得了很好的结果。虽然上述方法虽然取得了不错的效果,但是都需要大量的采样和计算,对数据的需求量很高,并且很多方法都需要很长的时间进行训练。
技术实现要素:
4.发明目的:本发明的目的是提供了一种基于逆向强化学习的斗地主ai,本发明能够利用少量的专家轨迹训练出一个斗地主ai,并且需要的训练时间很短,有助于推进深度强化学习在游戏中的应用以及逆向强化学习在需要经验的游戏中的应用。
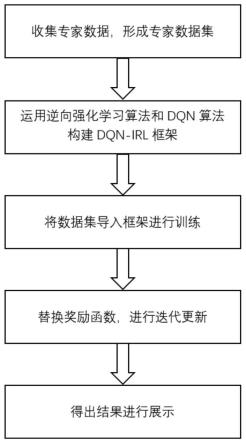
5.技术方案:本发明所述的一种基于逆向强化学习算法在斗地主中的应用,具体操作步骤如下:
6.(1)、采集职业玩家在每一局中的手牌和出牌,形成专家数据集;
7.(2)、利用dqn算法构建深度强化学习框架;
8.(3)、利用逆向强化学习算法学习到一个最符合专业玩家玩斗地主时的策略;
9.(4)、根据值函数的定义,选择一个随机策略;
10.(5)、将专家数据导入上述dqn-irl学习框架中进行训练并得出实验结果;
11.(6)、比较步骤2和步骤5中的实验结果。
12.进一步的,在所述步骤(2)中,利用dqn算法构建深度强化学习框架的具体步骤是:
13.(2.1)、将斗地主游戏中的状态和动作使用one-hot编码方式进行编码,使得agent在训练过程中能进行训练,且选择数据作为状态来帮助训练;将其编码为5*15的矩阵形式,其中状态是6个5*15的矩阵集合,分别为自己的手牌,另外两个玩家的手牌,所有已经出过的牌和最近三轮的动作;
14.(2.2)、将编码好的牌局在dqn算法框架下进行训练,在仿真平台rlcard上使用dqn算法对ai进行训练并得出实验结果。
15.进一步的,在所述步骤(3)中,利用逆向强化学习算法学习到一个最符合专业玩家玩斗地主时的策略,其具体的是:
16.基于收集的专家数据,运用学徒学习学习逼近专家策略的奖励函数r(s);
17.定义一个奖励函数r(s),其如下式所示:
[0018][0019]
其中,w表示是一个随机初始化的参数,表示是一个基底函数,s表示状态,状态是m个n*k的矩阵。
[0020]
进一步的,在所述步骤(4)中,根据值函数的定义,选择一个随机策略具体是:
[0021]
通过值函数的定义对特征期望进行改写,且使用随机策略的特征期望与专家数据的特征期望进行计算得出奖励函数中的w的值,并将其代入到奖励函数公式中得到奖励函数,然后将求得的奖励函数替换掉dqn算法中的奖励函数来进行迭代更新;其具体的操作步骤是:
[0022]
首先,得到下式公式:
[0023][0024]
其中,d表示初始的状态分布,s0表示初始状态,t表示时间步;e表示期望值;v表示值函数;π表示所采取的策略;γ表示折扣因子;r表示奖励函数;s
t
表示随时间步变化而变化的状态;w表示权重系数;表示特征函数;
[0025]
随着策略的改变,特征期望也会随之改变,所示特征期望的定义如下:
[0026][0027]
其中,μ表示特征期望;
[0028]
因此,值函数可改写为:
[0029][0030]
其中,d表示初始状态分布;
[0031]
然后,根据收集的专家数据来估算专家的特征期望:
[0032][0033]
式中,表示专家数据,表示专家轨迹的特征期望;n表示专家轨迹的数量;i表示当前所计算的专家轨迹;
[0034]
将随机策略的特征期望按下述式子对专家策略的随机期望进行逼近,具体如下式所示:
[0035][0036]
式中,∈表示是一个超参数,控制当前策略与专家策略逼近的程度;表示专家策略;μe表示当前策略的特征期望;
[0037]
最后,对w进行求解,求得最优的w,来更新之前设置的奖励函数r(s);
[0038]
在求出奖励函数后去替代dqn算法中的奖励函数来计算期望,进而继续与专家数
据的期望做差值进行更新;所示的框架为dqn-irl的学习框架。
[0039]
进一步的,在所述步骤(5)中,将专家数据导入上述dqn-irl学习框架中进行训练并得出实验结果具体是:将每局的手牌作为输入,通过dqn-irl的框架进行训练,然后令其和随机策略的ai对战并记录下每一局的结果。
[0040]
进一步的,在所述步骤(6)中,比较步骤(2)和步骤(5)中的实验结果具体是:比较两种框架下的表现,比较的指标为每一个框架在经过相同时间训练后的胜率和稳定性。
[0041]
有益效果:本发明与现有技术相比,本发明的特点是:1、本发明提供了一种逆向强化学习算法在斗地主中的应用,为深度强化学习在需要丰富经验的游戏中的应用提供了一种新的思路,对后续一些更加优良的逆向强化学习算法在此类游戏中的应用提供了参考;2、本发明提出的dqn-irl框架,对于数据量的需求不高,并且训练所需时间更短,相较于其他的算法而言易于实现。
附图说明
[0042]
图1是本发明的整体流程示意图;
[0043]
图2是本发明中dqn算法构建的深度强化学习框架示意图;
[0044]
图3是本发明中运用逆向强化学习算法学习到奖励函数并进行替换的示意图;
[0045]
图4是本发明中在地主位置时的胜率和方差示意图;
[0046]
图5是本发明中在地主上家位置时的胜率和方差示意图。
[0047]
图6是本发明中在地主下家位置时的胜率和方差示意图;
[0048]
图7是本发明的实施例示意图。
具体实施方式
[0049]
下面结合附图及实施例对本发明作进一步的说明。
[0050]
如图所述,一种基于逆向强化学习算法在斗地主中的应用,包括以下步骤:
[0051]
步骤1、采集职业玩家每一局的手牌和出牌,形成专家数据集;
[0052]
步骤2、利用dqn算法构建深度强化学习框架,对牌进行编码,在rlcard实验仿真平台上进行训练;具体如下:
[0053]
步骤2.1、将斗地主游戏中的状态和动作使用one-hot编码方式进行编码,将其编码为5*15的矩阵形式,其中状态是6个5*15的矩阵集合,分别为自己的手牌,另外两个玩家的手牌,所有已经出过的牌和最近三轮的动作;
[0054]
步骤2.2、在仿真平台rlcard上使用dqn算法对ai进行训练并得出实验结果;
[0055]
步骤3、利用逆向强化学习算法学习到一个最符合专业玩家玩斗地主时的策略,基于收集的专家数据,运用学徒学习学习逼近专家策略的奖励函数r(s),
[0056]
首先,定义一个奖励函数r(s)如下:
[0057][0058]
其中,w是一个随机初始化的参数,是一个基底函数,s代表状态,状态是m个n*k的矩阵,如步骤2.1中所述;
[0059]
步骤4、根据值函数的定义,选择一个随机策略,即:构建dqn-irl学习框架,根据值函数的定义对奖励函数进行推导和求解;得到公式:
[0060][0061]
d表示初始的状态分布,s0表示初始状态,t表示时间步;
[0062]
随着策略的改变,特征期望也会随之改变,特征期望的定义如下:
[0063][0064]
因此,值函数可以改写为:
[0065][0066]
然后,根据收集的专家数据来估算专家的特征期望:
[0067][0068]
上式中的就是专家数据;
[0069]
将随机策略的特征期望按照下述式子对专家策略的随机期望进行逼近:
[0070][0071]
∈是一个超参数,控制当前策略与专家策略逼近的程度;
[0072]
最后,对w进行求解,求得最优的w,来更新之前设置的奖励函数r(s);
[0073]
在求出奖励函数后去替代dqn(deep q network)算法中的奖励函数来计算期望,进而继续与专家数据的期望做差值进行更新,这种框架我们定义为dqn-irl的学习框架;
[0074]
步骤5、将专家数据导入上述dqn-irl学习框架中进行训练并得出实验结果;即:将专家数据及导入新的深度强化学习框架,进行训练,并记录实验结果;
[0075]
步骤6、比较步骤2和步骤5中的实验结果;即:在同样的训练时间下,比较dqn框架和dqn-irl框架在胜率和方差上的表现。
[0076]
作为本发明所述的一种逆向强化学习算法在斗地主中的应用,步骤1采集了职业玩家在每一局中的手牌和动作,形成专家数据集。
[0077]
作为本发明所述的一种逆向强化学习算法在斗地主中的应用,步骤2.1对扑克牌进行了编码,使得agent在训练过程中能够进行有效率的训练,并且选择了合理的数据作为状态来帮助训练。
[0078]
作为本发明所述的一种逆向强化学习算法在斗地主中的应用,步骤2.2将编码好的牌局在dqn算法框架下进行训练,然后让其和随机策略的ai进行对战并得出实验结果。
[0079]
作为本发明所述的一种逆向强化学习算法在斗地主中的应用,步骤3中选择适当的基底函数对需要学习的奖励函数进行定义,方便后续对奖励函数的求解。
[0080]
作为本发明所述的一种逆向强化学习算法在斗地主中的应用,步骤4通过值函数的定义对特征期望进行改写,并且使用随机策略的特征期望与专家数据的特征期望进行计算得出奖励函数中的w的值,并将其代入到奖励函数公式中得到奖励函数,然后将求得的奖励函数替换掉dqn算法中的奖励函数来进行迭代更新。
[0081]
作为本发明所述的一种逆向强化学习算法在斗地主中的应用,步骤5将每局的手
牌作为输入,通过dqn-irl的框架进行训练,然后令其和随机策略的ai对战并记录下每一局的结果。
[0082]
作为本发明所述的一种逆向强化学习算法在斗地主中的应用,步骤6比较两种框架下的表现,比较的指标为每一个框架在经过相同时间训练后的胜率和稳定性。
[0083]
本发明是运用逆向强化学习算法学习新的奖励函数来构建构建dqn-irl深度强化学习框架,训练出有效的斗地主ai;与以往的方法不同,本发明降低了对数据量的需求,也减少了训练时间,同时也为后续的逆向强化学习在斗地主上的应用做出了一个参考。
[0084]
具体实施例
[0085]
参加附图4,在rlcard仿真平台上,将本ai和dqn算法训练出的地主位置的ai进行对战,得出各自的胜率和胜率的方差,可见本ai的胜率还是较高的,稳定性也较好。
[0086]
参加附图5,在rlcard仿真平台上,将本ai和dqn算法训练出的地主上家位置的ai进行对战,得出各自的胜率和胜率的方差,从胜率和方差来看,两个ai的表现较为接近。
[0087]
参加附图6,在rlcard仿真平台上,将本ai和dqn算法训练出的地主下家位置的ai进行对战,得出各自的胜率和胜率的方差,从胜率上来看,本ai的前期胜率较高,后期表现欠佳,但是相较于dqn算法训练的ai更加稳定。
[0088]
本案例在实战对弈时的具体界面参见附图7。
[0089]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1