机械学习方法、机械学习装置、控制装置以及电动机装置与流程
本发明涉及学习对电动机的动作指令的机械学习方法、机械学习装置以及具备该机械学习装置的控制装置以及电动机装置。
背景技术:
为了有效地执行使用电动机的预期工序,希望能够缩短周期时间。通过最优化电动机的加速度或减速度(以下有时称为“加减速”)而能够缩短周期时间。一般,通过操作员指定电动机的加减速,所以实现最优化有时大大依赖于操作员的知识乃至经验,另外试错是不可缺少的。
使加减速的最优化困难的其他原因是从控制电动机的控制装置产生的热。虽然电动机被控制为在不发生过热的范围进行动作,但是是否发生过热也会根据电动机的周围环境而不同。因此,为了确切地防止发生过热,需要设想最极端的周围环境来进行加减速的最优化。其结果为,当周围温度低时,实际上电动机的动作没有被最优化,周期时间有增大的倾向。
根据发热源的温度来调整电动机的输出的技术是公知的。例如推定用于驱动电动机的功率半导体模块的温度,并且当推定出的温度超过了基准温度时限制电动机的输出的技术是公知的(参照日本特开2014-239631号公报)。
技术实现要素:
希望获得一种根据周围温度使电动机有效地进行动作的控制装置。
在本申请的优选实施方式中,提供一种学习对电动机的动作指令的机械学习装置,其具备:状态观测部,其观测具备电动机以及控制该电动机的控制装置的电动机装置的周围温度、以及上述电动机的周期时间作为状态变量;判定数据取得部,其取得判定在上述电动机装置中是否发生了过热的判定数据;以及学习部,其按照根据上述状态变量和上述判定数据的组合而生成的训练数据集,学习对上述电动机的动作指令。
在本申请的优选实施方式中,上述学习部具备:回报计算部,其根据上述周期时间和上述判定数据来计算回报;函数更新部,其根据上述回报来更新用于决定上述动作指令的函数。
在本申请的优选实施方式中,上述回报计算部构成为,在判定为上述电动机装置中未发生过热,并且上述周期时间小于预先决定的阈值时,增大回报;在判定为上述电动机装置中发生了过热时,或者上述周期时间是上述阈值以上时,降低回报。
在本申请的优选实施方式中,上述函数更新部构成为,按照上述回报来更新行为价值表。
在本申请的优选实施方式中,上述学习部构成为,按照对多个电动机装置生成的训练数据集来学习上述动作指令。
在本申请的优选实施方式中,提供一种控制装置,其具备:上述机械学习装置;测定上述周围温度的温度测定部;测定上述周期时间的时间测定部;根据上述学习部学习后的结果,来决定与当前的上述周围温度和当前的上述周期时间对应的上述动作指令的意图决定部。
在本申请的优选实施方式中,提供一种电动机装置,具备:上述控制装置、通过上述控制装置进行控制的电动机。
在本申请的优选实施方式中,提供一种学习对电动机的动作指令的机械学习方法,包括以下步骤:观测具备电动机和控制该电动机的控制装置的电动机装置的周围温度、以及上述电动机的周期时间作为状态变量;取得判定在上述电动机装置中是否发生了过热的判定数据;以及按照根据上述状态变量和上述判定数据的组合而生成的训练数据集,学习对上述电动机的动作指令。
附图说明
通过参照附图所示的本发明的例示性实施方式的详细说明,能够更加明确本发明的这些以及其他目的、特征以及优点。
图1是一个实施方式的电动机装置的框图。
图2是表示机械学习装置的学习过程的流程的流程图。
图3是表示神经网络的结构例的图。
图4是表示提供给电动机的电流与周期时间之间的关系的图。
具体实施方式
以下,参照附图说明本发明的实施方式。图1是一个实施方式的电动机装置1的框图。电动机装置1具备:电动机2、控制电动机2的控制装置3、学习对电动机2的动作指令的机械学习装置4、和散热器5。
为了对机床或工业用机器人的旋转轴赋予动力而使用电动机2。电动机2按照通过控制装置3生成的动作指令而进行动作。动作指令包括:位置指令、速度指令、以及加速度指令。机械学习装置4使用后述的机械学习的方法来学习与周围温度对应的最佳的加速度指令。
控制装置3是具备通过总线相互连接的CPU、存储器以及接口的数字计算机。或者,控制装置3可以是向电动机2提供动力的放大器,或者也可以是数字计算机和放大器的组合。以下,说明控制装置3是数字计算机的例子。CPU为了实现控制装置3的各种功能而执行必要的运算处理。
存储器包括ROM、RAM、以及非易失性存储器等。ROM中存储有控制控制装置3的整体动作的系统程序。RAM中暂时存储来自检测装置或者检测电路的检测信号以及CPU的运算结果等。非易失性存储器中存储控制电动机2的动作的动作程序以及参数等。
接口用于将控制装置3与外部装置例如输入装置和显示装置等相互连接,并在它们之间发送接收信号和数据。
如图1所示,控制装置3具备:温度测定部31、指令生成部32、时间测定部33、以及判定部34。
温度测定部31测定电动机装置1的周围温度。在一个实施方式中,温度测定部31通过测定散热器5的温度而取得周围温度。散热器5用于释放从电动机装置1的发热源发生的热。散热器5例如是为了与外部空气进行热交换而构成的散热片,其温度对应于电动机装置1的周围温度而变化。因此,通过测定散热器5的温度,能够间接地测定周围温度。
在另一实施方式中,温度测定部31可以使用安装在控制装置3的壳体上的温度传感器来直接测定周围温度。这样,在本说明书中,通过温度测定部31测定的“周围温度”是指直接或间接地测定外部空气温度而得到的温度。或者,也可以根据与周围温度有关联的其他物理量通过计算来求出“周围温度”。通过温度测定部31测定出的周围温度被输入给机械学习装置4的状态观测部41。
指令生成部32按照存储在非易失性存储器中的动作程序和参数来生成对电动机2的动作指令。控制装置3将与动作指令对应的电力提供给电动机2。
时间测定部33测定按照从指令生成部32输出的动作指令进行动作的电动机2的周期时间。可以针对动作程序的每个程序块来计算周期时间。通过时间测定部33测定出的周期时间被输入到机械学习装置4的状态观测部41中。
判定部34判定在电动机装置1中是否发生了过热(以下有时称为“过热判定”)。判定部34使用检测电路或检测装置来执行过热判定,该检测电路或检测装置检测在控制装置3的放大器中使用的功率元件或其他发热源的温度。或者,判定部34也可以使用检测局部设定了温度上限值的任意部位的温度的检测单元来执行过热判定。过热判定的结果(以下有时称为“判定数据”)被输入到机械学习装置4的判定数据取得部42中。
如图1所示,机械学习装置4具备:状态观测部41、判定数据取得部42、学习部43、以及意图决定部46。
状态观测部41分别观测从温度测定部31发送的周围温度、以及从时间测定部33发送的周期时间,作为状态变量。状态变量从状态观测部41被输入到学习部43中。
判定数据取得部42从控制装置3的判定部34取得判定数据。判定结果用于在后述的回报计算部44中计算回报。
学习部43按照根据从状态观测部41发送的状态变量和从判定数据取得部42发送的判定数据的组合而生成的训练数据集,学习对电动机2的动作指令。
意图决定部46根据学习部43学习后的结果,决定与当前的状态变量对应的对电动机2的动作指令、特别是加速度指令。指令生成部32将通过意图决定部46决定的加速度指令赋予给电动机2。另外,作为在机械学习装置4中包括的单元说明了意图决定部46,但是也可以构成为意图决定部46被包括在控制装置3中。另外也可以构成为,机械学习装置4包括在控制装置3中。控制装置3可以具备:温度测定部31、指令生成部32、时间测定部33、判定部34、上述的意图决定部46、以及不包括意图决定部46的机械学习装置4。
机械学习装置4可以是不同于控制装置3的数字计算机,或者也可以内置在控制装置3中。在后者的情况下,机械学习装置4使用控制装置3的CPU和存储器来执行机械学习。
在一个实施方式中,机械学习装置4可以设置在远离电动机2和控制装置3的部位。此时,机械学习装置4经由网络与控制装置3连接。或者,机械学习装置4也可以存在于云服务器中。
本实施方式的机械学习装置4按照公知的Q学习方法来执行强化学习。机械学习装置4根据求取在某状态变量s(当前的周围温度以及当前的周期时间)时选择了行为a(赋予给电动机2的动作指令)的情况下的行为价值Q(期待值)的行为价值函数Q(s、a),学习最佳的行为。
在学习的初始阶段,针对某状态变量s与行为a的组合而分配的行为价值Q是未知的。机械学习装置4针对各种状态变量s随机地选择行为a并执行,对作为行为a的结果而赋予的回报进行累计,由此来更新行为价值函数Q(s、a)。通过式1表示更新行为价值函数Q(s、a)的一般式。
这里,st是时刻t的状态变量。at是在时刻t执行的行为。st+1是时刻t+1的状态变量,换言之,是作为进行了行为at的结果而发生变化后的状态变量。rt+1是与作为行为at的结果而发生变化的环境对应地赋予的回报。“max”的项表示状态变量st+1的行为价值Q的最大值(即、对最佳行为a的行为价值)。γ是折扣率,被设定为满足0<γ≤1(例如γ=0.9~0.99)。α是学习系数,被设定为满足0<α≤1(例如α=0.05~0.2)。
在通过式1表示的更新式中,如果时刻t+1的最佳行为a的行为价值大于在时刻t执行的行为a的行为价值Q,则增大行为价值Q;相反的情况下,则缩小行为价值Q。换言之,更新行为价值函数Q(s、a),使得时刻t的行为a的行为价值Q接近时刻t+1的最佳的行为价值。由此,某环境的最佳的行为价值不断地依次传播给在那之前的环境的行为价值。
如果再次参照图1,则学习部43具备回报计算部44和函数更新部45。
回报计算部44根据电动机2的周期时间和判定数据来计算回报r。例如在判定为未发生过热,并且周期时间小于预先决定的的阈值时,使回报r增大(例如赋予回报“1”)。另一方面,当判定为发生了过热时,或者周期时间为阈值以上时,降低回报r(例如赋予回报“-1”)。另外,也可以使用按照预定时间而大小不同的阈值。
函数更新部45按照回报计算部44所计算的回报,更新用于决定对电动机2的动作指令的函数。能够按照训练数据集,例如通过更新行为价值表来进行函数的更新。行为价值表是将任意的行为与其行为价值关联起来以表的形式进行存储的数据集。
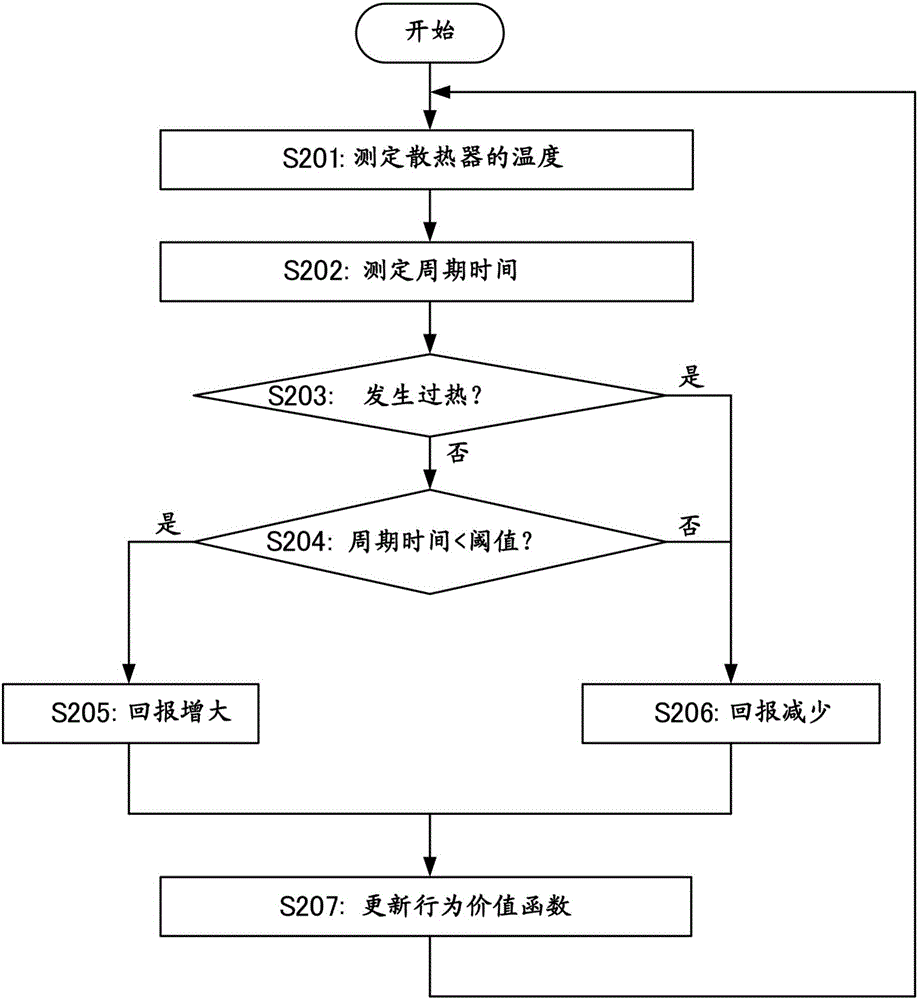
接着,参照图2所示的流程图来说明更新行为价值Q(s、a)的强化学习方法。在步骤S201中,温度测定部31测定散热器5的温度。在步骤S202中,时间测定部33测定电动机2的周期时间。
在步骤S203中,判定在电动机装置1中是否发生了过热。按照从判定部34输出的判定数据来执行步骤S203的判定。当步骤S203的判定结果是否定时,即判定为未发生过热时,前进到步骤S204。
在步骤S204中,判定在步骤S202中取得的周期时间是否小于预先决定的阈值。当步骤S204的判定结果是肯定时(周期时间小于阈值时),前进到步骤S205。在步骤S205中,回报计算部44增大回报r,使得与赋予给电动机2的动作指令对应的行为价值Q增大。
当步骤S203中的判定结果为肯定时,或者步骤S204中的判定结果为否定时,前进到步骤S206。在步骤S206中,回报计算部44降低回报r,使得与赋予给电动机2的动作指令对应的行为价值Q下降。
在步骤S207中,函数更新部45根据步骤S205或步骤S206中计算出的回报r,更新行为价值函数Q(s、a)。之后,再次返回步骤S201,针对新选择出的动作指令,再次执行步骤S201~S207的处理。可以在每次变更动作指令时执行步骤S201~S207的处理,也可以以预定的周期重复执行步骤S201~S207的处理。在机械学习的初始阶段,可以针对随机生成的加速度指令来执行步骤S201~S207的处理。
在另一实施方式中,机械学习装置4可以按照神经网络模型来执行机械学习。图3表示神经网络模型的例子。神经网络由如下构成:包括1个神经元x1、x2、x3、……、x1的输入层;包括m个神经元y1、y2、y3、……、ym的中间层(隐藏层);包括n个神经元z1、z2、z3、……、zn的输出层。另外,在图3中,中间层只表示为1层,但也可以设置2层以上的中间层。
神经网络学习:电动机装置1的周围温度、周期时间、以及有无发生过热之间的关系性。神经网络按照根据状态变量和判定数据而生成的训练数据集,即通过有教师学习,来学习状态变量与环境变化之间的关系性。根据本实施方式,在电动机控制装置3或机械学习装置4中包括的意图决定部46构成为,输出层根据被输入到神经网络的输入层的状态变量来决定最佳的动作指令。
根据上述实施方式的机械学习装置以及机械学习方法,能够根据电动机装置1的周围温度来学习最佳的动作指令。图4是表示提供给电动机2的电流与周期时间之间的关系的图。图中的实线表示在至少一个部位发生过热的情况,虚线表示将使用上述机械学习而求出的动作指令赋予给电动机2的情况。
在比实线图表更上侧的区域A1中发生了过热,电动机2被视为正进行异常动作,成为紧急停止或警报通知的对象。上述电动机控制装置3或机械学习装置4中包括的意图决定部46是比实线图表更下侧的区域A2的范围内,决定要接近与区域A1的边界的动作指令。换言之,按照本实施方式,将在不会发生过热的范围内能够尽可能缩短周期时间的最佳动作指令赋予给电动机2。
如上所述,根据本实施方式,使用机械学习的结果,自动使对电动机的动作指令最佳化,因此不需要依赖操作员的知识或经验。进一步地,由于与周围温度对应地生成最佳的动作指令,因此能够始终使电动机的动作最佳化。另外,由于通过机械学习将决定最佳动作指令的过程自动化,因此不需要试错,能够降低操作员的负担。
在一个实施方式中可以构成为,学习部43按照针对多个电动机装置1而生成的训练数据集,学习动作指令。学习部43可以从在相同现场使用的多个电动机装置1取得训练数据集,或者也可以使用从在不同现场独立运行的电动机装置1收集到的训练数据集来学习故障条件。
说明了使用强化学习以及神经网络进行机械学习的实施方式,但是也可以按照其他公知的方法例如遗传编程、功能逻辑编程、支持向量机等来执行机械学习。
以上,说明了本发明的各种实施方式,但是如果是本领域技术人员会认识到即使通过其他实施方式也能够实现本发明所要达到的作用效果。特别是能够不脱离本发明的范围地删除或置换上述实施方式的结构要素,或者能够进一步附加公知的手段。另外,本领域技术人员明白即使通过任意地组合在本说明书中明示或暗示公开的多个实施方式的特征也能够实施本发明。
本发明的机械学习装置以及机械学习方法,按照根据状态变量与判定数据的组合而生成的训练数据集,来学习对电动机的动作指令。由于将电动机装置的周围温度和周期时间与是否发生过热关联起来而学习动作指令,因此能够学习与周围温度对应的最佳动作指令。
本发明的控制装置以及电动机装置按照与周围温度对应地最佳化的动作指令来使电动机动作,因此能够不发生过热地缩短周期时间。
- 还没有人留言评论。精彩留言会获得点赞!